2.7 DNA'Replication,'Transcription'and'Translation'
DNA'Replication'
!"#$%&'()*+(,-.(/0#$&1%2&*'(&3(304&51*'30/6%2&60(
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
(
782$&'0()*+(2)0(/038$23(*9(2)0(:030$3*'5;2%)$(0"#0/&40'2(38##*/20<(304&51*'30/6%2&60(,-.(/0#$&1%2&*'(
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
(
,031/&=0(2)0(/*$0(*9(2)0(9*$$*+&'>(0'?@403(&'(,-.(/0#$&1%2&*'(
Helicase:##…………………………………………………………………………………………………………………………………………#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
DNA#Polymerase:##…………………………………………………………………………………………………………………………….#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
#
!"#$%&'(2)0(3&>'&9&1%'10(*9(1*4#$040'2%/@(=%30(#%&/&'>(&'(2)0(1*'30/6%2&*'(*9(=%30(30A80'10(
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
#
;2%20(+)0'(%'<(+)0/0(,-.(/0#$&1%2&*'()%##0'3(&'(%(2@#&1%$(08B%/@*2&1(10$$(
…………………………………………………………………………………………………………………………………………………..........#
DNA replication is semi-conservative because when a new double-stranded DNA molecule is formed:
• One strand is from the original template molecule (i.e. conserved)
• One strand is newly synthesised (i.e. not conserved)
Meselson and Stahl treated DNA with a heavier nitrogen isotope (15N) and then replicated in the presence
of a lighter nitrogen isotope (14N) - so template DNA and newly synthesised DNA could be differentiated.
The results supported a semi-conservative model of DNA replication:
• After one division, all molecules contained both 15N and 14N
• After two divisions, some molecules contained both 15N and 14N, while other molecules only contained 14N
Helicase unwinds and separates double-stranded DNA molecules
(by breaking the hydrogen bonds between the complementary base pairs)
DNA polymerase synthesises a new strand (complementary to the template strand)
Nucleotides align opposite their partner, and DNA Pol III covalently joins them together
DNA Pol III synthesises a new strand in a 5’ - 3’ direction
Free nucleotides can only align opposite their complementary base partner (A=T, G=C)
This means a newly synthesised strand will be identical to the complementary partner of a template strand
Hence, base sequence is conserved
DNA replication occurs within the nucleus, during the S phase of interphase
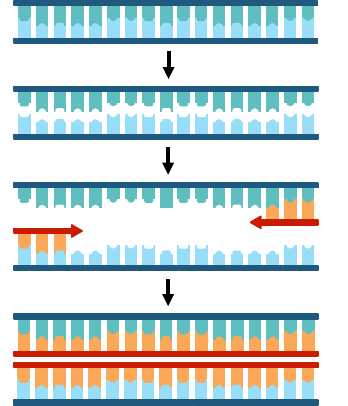
,031/&=0(2)0(#8/#*30(%'<(#/*1033(*9(2)0(#*$@40/%30(1)%&'(/0%12&*'(CDEFG(
………………………………………………………………………………………………………#
………………………………………………………………………………………………………#
………………………………………………………………………………………………………#
………………………………………………………………………………………………………#
………………………………………………………………………………………………………#
………………………………………………………………………………………………………#
………………………………………………………………………………………………………#
………………………………………………………………………………………………………#
#
Transcription'
,09&'0(2/%'31/&*'(
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
#
,&32&'>8&3)(=02+00'(30'30(%'<(%'2&30'30(32/%'<3(
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
#
782$&'0(2)0(/*$0(*9(F-.(#*$@40/%30(&'(2)0(#/*1033(*9(2/%'31/&*'(
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
#
E*'60/2(2)0(9*$$*+&'>(,-.(30A80'10(&'2*(%'(F-.(2/%'31/(
T##A##C##A##A##A##T##T##C##G##T##A##C##T##G##C##A##C##T##C##C##G##G##A##A##C##A##A##C##T#
…………………………………………………………………………………………………………………………………………………..........#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
PCR is used to rapidly amplify minute quantities of DNA
It involves a thermal cycler and three repeating steps:
• Denaturation - DNA is heated to separate strands
• Annealing – Primers are introduced to designate copying points
• Elongation - Taq polymerase* synthesises new strand
These three steps double the amount of DNA, so a typical reaction of
30 cycles will produce over 1 billion copies of desired DNA sequence
* Taq polymerase is heat resistant and so doesn’t denature during PCR
Transcription is the process by which an RNA sequence is produced from a DNA template (gene)
The antisense strand is the DNA strand that IS transcribed (complementary to eventual RNA sequence)
The sense strand is the strand that is NOT transcribed (identical to RNA sequence - except T in place of U)
A U G U U U A A G C A U G A C G U G A G G C C U U G U U G A
RNA polymerase unwinds and separates the double stranded DNA and then synthesises a new RNA strand
based on the antisense template – the RNA strand is then released and DNA double helix reforms
(when RNA polymerase separates the DNA strands, free nucleotides align opposite their complementary
base partners and RNA polymerase covalently joins them together)

Translation'
,09&'0(2/%'3$%2&*'(
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
#
,031/&=0(2)0(98'12&*'(*9(2)0(>0'02&1(1*<0(C&'1$8<&'>(<0>0'0/%1@G(
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
#
H<0'2&9@&'>(2)0(B0@(1*4#*'0'23(*9(2)0(#/*1033(*9(2/%'3$%2&*'(
#M##………………………………………………………………………………………………#
R##………………………………………………………………………………………………#
C##………………………………………………………………………………………………#
A##………………………………………………………………………………………………#
T##………………………………………………………………………………………………#
A##………………………………………………………………………………………………#
P##………………………………………………………………………………………………#
P##………………………………………………………………………………………………# # Hint:##Mr#Cat#App#
#
;844%/&30(2)0(#/*1033(*9(2/%'3$%2&*'(
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
Translation is the process of protein synthesis, whereby genetic information encoded by mRNA is
translated into an amino acid sequence (i.e. polypeptide) at the ribosome
The genetic code is the set of rules by which information encoded by mRNA is translated into polypeptides
• It identifies the specific amino acid encoded by each triplet of mRNA bases (codon)
• There are 64 possible codon combinations (4 x 4 x 4), but only 20 possible amino acids
• This means some codons code for the same amino acid (degeneracy)
Messenger RNA (mRNA) - Contains the genetic instructions
Ribosome – Site of translation
Codon - Triplet of bases denoting a specific amino acid
Anticodon - Complementary sequence on tRNA molecules
Transfer RNA (tRNA) - Transfers amino acids to ribosome
Amino acid - Monomeric component of a polypeptide chain
Peptide bond - The covalent bond formed between amino acids
Polypeptide - The end product of translation
• Ribosome binds to mRNA and moves along it in a 5’ - 3’ direction, reading the sequence in codons
• Each codon encodes a specific amino acid, which is brought to the ribosome by tRNA molecules
• Each tRNA is specific for a particular codon due to the presence of a complementary anticodon
• The tRNA molecules bring the amino acids to the ribosome in an order determined by the codon sequence
• The ribosome moves along the mRNA, joining the amino acids together via peptide bonds
• Translation of a polypeptide begins at a START codon (AUG) and is terminated at a STOP codon
I30(2)0(>0'02&1(1*<0(2*(1*'60/2(2)0(9*$$*+&'>(,-.(
30A80'10(&'2*(%(#*$@#0#2&<0(30A80'10(
#
TAC#AAA#TTC#GTA#CTG#CAC#TCC#GGA#ACA#ACT#
RNA:##………………………………………………………………….#
Protein:##……………………………………………………………..#
#
782$&'0(2)0(099012(*9(2)0(9*$$*+&'>(482%2&*'3J(
GTA#→#GTT:##………………………………………………………#
TCC#→#TCT:##………………………………………………………#
#
,031/&=0(2)0(<&990/0'2(2@#03(*9(#*&'2(482%2&*'3(
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
#
782$&'0(2)0(3&>'&9&1%'10(*9(%(9/%403)&92(482%2&*'(
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
#
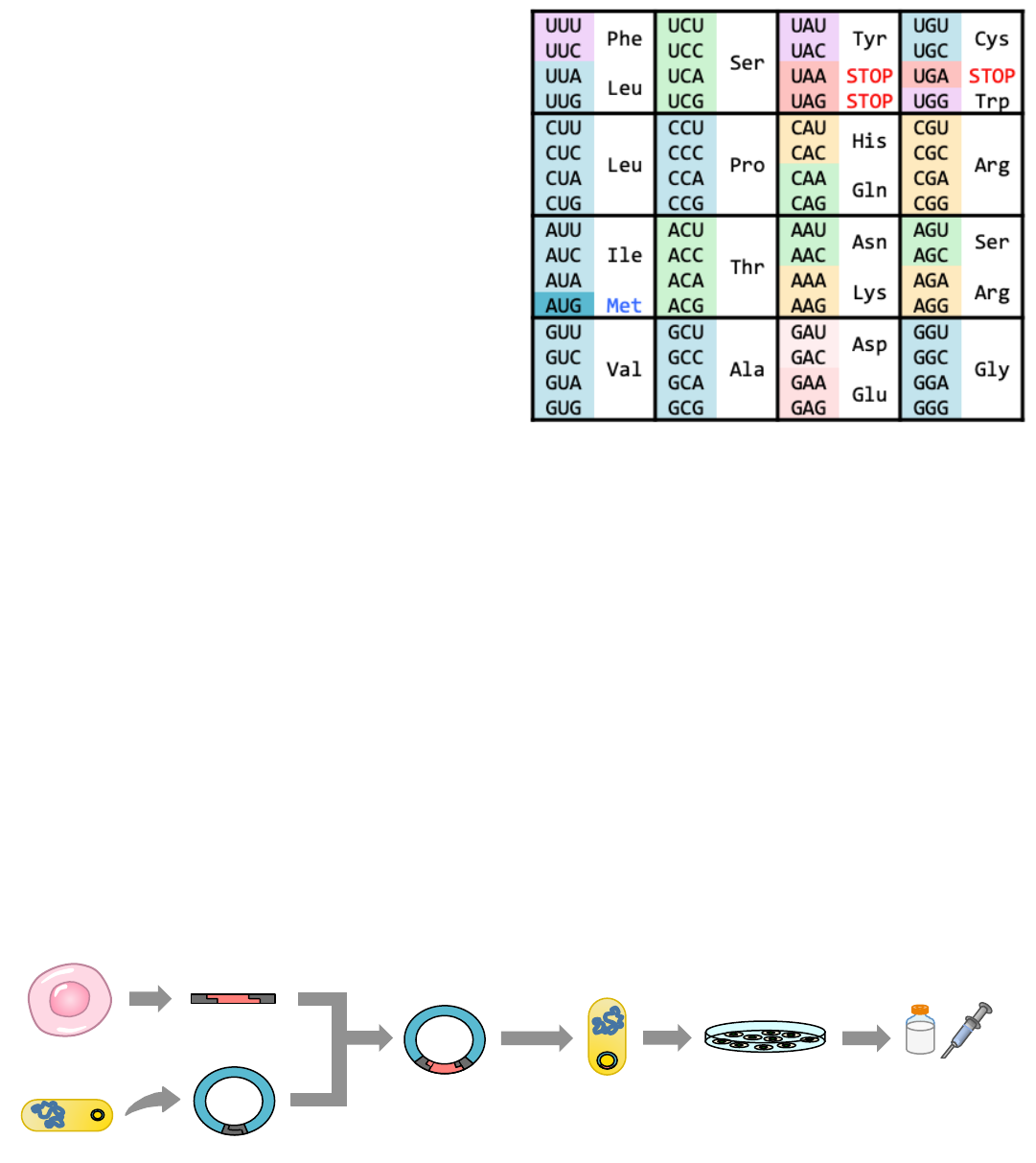
I30(2)0(9*$$*+&'>(&4%>0(2*(0"#$%&'()*+(2)0(8'&60/3%$&2@(*9(2)0(>0'02&1(1*<0(%$$*+3(9*/(>0'0(2/%'390/
#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
…………………………………………………………………………………………………………………………………………………..........#
#
#
#
#
#
#
#
#
##
#
#
#
#
##
#
#
#
#
#
#
##
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
##
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
Human#Cell
Bacteria
Insulin#gene
Plasmid
Recombinant#
Plasmid
#
Transgenic#
bacteria
#
Grow#in#
culture
#
Extract#
insulin
#
#
#
#
#
AUG UUU AAG CAU GAC GUG AGG CCU UGU UGA
Met-Phe-Lys-His-Asp-Val-Arg-Pro-Cys-STOP
His to Gln (missense mutation)
Arg to Arg (silent mutation)
Silent mutations do not change the polypeptide sequence (possible due to degeneracy of the genetic code)
Missense mutations involve a change in a single amino acid within the polypeptide sequence
Nonsense mutations create a STOP codon (thus prematurely terminating the polypeptide chain)
Frameshift mutations (insertions, deletions) change the reading frame (meaning all codons are changed)
The genetic code is universal, meaning (almost) all organisms follow the same set of genetic instructions
This means that a DNA sequence from one organism can be successfully translated by another organism
The gene for insulin is extracted from human cells and inserted into bacterial cells (via recombinant plasmid)
The bacteria can now produce human insulin (bacteria divide quickly, allowing for effective mass production)
This can be used to produce insulin treatments for type I diabetics
