
PUBLIC
Document Version: 4.3 (14.3.00.00)–2024-03-25
Data Services Supplement for Big Data
© 2024 SAP SE or an SAP aliate company. All rights reserved.
THE BEST RUN
Content
1 About this supplement........................................................4
2 Naming conventions and variables...............................................5
3 Big data in SAP Data Services..................................................10
3.1 Apache Cassandra...........................................................10
Setting ODBC driver conguration on Linux........................................11
Data source properties for Cassandra........................................... 12
3.2 Apache Hadoop............................................................. 13
Hadoop Distributed File System (HDFS)..........................................14
Hadoop Hive .............................................................14
Upload data to HDFS in the cloud...............................................15
Google Cloud Dataproc clusters................................................15
3.3 HP Vertica................................................................. 16
Enable MIT Kerberos for HP Vertica SSL protocol................................... 17
Creating a DSN for HP Vertica with Kerberos SSL................................... 21
Creating HP Vertica datastore with SSL encryption..................................23
Increasing loading speed for HP Vertica..........................................24
HP Vertica data type conversion...............................................25
HP Vertica table source..................................................... 27
HP Vertica target table conguration............................................28
3.4 MongoDB................................................................. 32
MongoDB metadata........................................................32
MongoDB as a source...................................................... 33
MongoDB as a target.......................................................36
MongoDB template documents............................................... 39
Preview MongoDB document data..............................................41
Parallel Scan.............................................................42
Reimport schemas........................................................ 43
Searching for MongoDB documents in the repository................................44
3.5 Apache Impala..............................................................44
Download the Cloudera ODBC driver for Impala ....................................45
Creating an Apache Impala datastore ...........................................46
3.6 PostgreSQL ................................................................48
Datastore options for PostgreSQL..............................................49
Congure the PostgreSQL ODBC driver ..........................................53
Conguring ODBC driver for SSL/TLS X509 PostgresSQL.............................54
2
PUBLIC
Data Services Supplement for Big Data
Content
Import PostgreSQL metadata.................................................55
PostgreSQL source, target, and template tables ....................................56
PostgreSQL data type conversions............................................. 57
3.7 SAP HANA.................................................................58
Cryptographic libraries and global.ini settings .....................................59
X.509 authentication.......................................................61
JWT authentication........................................................62
Bulk loading in SAP HANA................................................... 63
Creating stored procedures in SAP HANA........................................ 65
SAP HANA database datastores ...............................................66
Conguring DSN for SAP HANA on Windows...................................... 72
Conguring DSN for SAP HANA on Unix ......................................... 74
Datatype conversion for SAP HANA.............................................76
Using spatial data with SAP HANA..............................................78
3.8 Amazon Athena.............................................................80
Athena data type conversions.................................................81
ODBC capacities and functions for Athena........................................82
4 Cloud computing services.................................................... 84
4.1 Cloud databases.............................................................84
Amazon Redshift database...................................................85
Azure SQL database....................................................... 96
Google BigQuery..........................................................98
Google BigQuery ODBC.....................................................99
SAP HANA Cloud, data lake database...........................................99
Snowake..............................................................103
4.2 Cloud storages............................................................. 116
Amazon S3..............................................................117
Azure Blob Storage........................................................123
Azure Data Lake Storage....................................................130
Google Cloud Storage le location.............................................134
Data Services Supplement for Big Data
Content
PUBLIC 3
1 About this supplement
This supplement contains information about the big data products that SAP Data Services supports.
The supplement contains information about the following:
• Supported big data products
• Supported cloud computing technologies including cloud databases and cloud storages.
Find basic information in the Reference Guide, Designer Guide, and some of the applicable supplement guides.
For example, to learn about datastores and creating datastores, see the Reference Guide. To learn about Google
BigQuery, refer to the Supplement for Google BigQuery.
4 PUBLIC
Data Services Supplement for Big Data
About this supplement

2 Naming conventions and variables
This documentation uses specic terminology, location variables, and environment variables that describe
various features, processes, and locations in SAP Data Services.
Terminology
SAP Data Services documentation uses the following terminology:
• The terms Data Services system and SAP Data Services mean the same thing.
• The term BI platform refers to SAP BusinessObjects Business Intelligence platform.
• The term IPS refers to SAP BusinessObjects Information platform services.
Note
Data Services requires BI platform components. However, when you don't use other SAP applications,
IPS, a scaled back version of BI, also provides these components for Data Services.
• CMC refers to the Central Management Console provided by the BI or IPS platform.
• CMS refers to the Central Management Server provided by the BI or IPS platform.
Variables
The following table describes the location variables and environment variables that are necessary when you
install and congure Data Services and required components.
Data Services Supplement for Big Data
Naming conventions and variables
PUBLIC 5

Variables Description
INSTALL_DIR
The installation directory for SAP applications such as Data
Services.
Default location:
• For Windows: C:\Program Files (x86)\SAP
BusinessObjects
• For UNIX: $HOME/sap businessobjects
Note
INSTALL_DIR isn't an environment variable. The in-
stallation location of SAP software can be dierent than
what we list for INSTALL_DIR based on the location
that your administrator sets during installation.
BIP_INSTALL_DIR
The directory for the BI or IPS platform.
Default location:
• For Windows: <INSTALL_DIR>\SAP
BusinessObjects Enterprise XI 4.0
Example
C:\Program Files
(x86)\SAP BusinessObjects\SAP
BusinessObjects Enterprise XI 4.0
• For UNIX: <INSTALL_DIR>/enterprise_xi40
Note
These paths are the same for both BI and IPS.
Note
BIP_INSTALL_DIR isn't an environment variable.
The installation location of SAP software can be dierent
than what we list for BIP_INSTALL_DIR based on the
location that your administrator sets during installation.
6
PUBLIC
Data Services Supplement for Big Data
Naming conventions and variables

Variables Description
<LINK_DIR>
An environment variable for the root directory of the Data
Services system.
Default location:
• All platforms
<INSTALL_DIR>\Data Services
Example
C:\Program Files (x86)\SAP
BusinessObjects\Data Services
Data Services Supplement for Big Data
Naming conventions and variables
PUBLIC 7

Variables Description
<DS_COMMON_DIR>
An environment variable for the common conguration di-
rectory for the Data Services system.
Default location:
• If your system is on Windows (Vista and newer):
<AllUsersProfile>\SAP
BusinessObjects\Data Services
Note
The default value of <AllUsersProfile> environ-
ment variable for Windows Vista and newer is
C:\ProgramData.
Example
C:\ProgramData\SAP
BusinessObjects\Data Services
• If your system is on Windows (Older versions such as
XP)
<AllUsersProfile>\Application
Data\SAP BusinessObjects\Data
Services
Note
The default value of <AllUsersProfile> en-
vironment variable for Windows older versions
is C:\Documents and Settings\All
Users.
Example
C:\Documents and Settings\All
Users\Application Data\SAP
BusinessObjects\Data Services
• UNIX systems (for compatibility)
<LINK_DIR>
The installer automatically creates this system environment
variable during installation.
Note
Starting with Data Services 4.2 SP6, users
can designate a dierent default location for
8
PUBLIC
Data Services Supplement for Big Data
Naming conventions and variables

Variables Description
<DS_COMMON_DIR> during installation. If you can't nd
the <DS_COMMON_DIR> in the listed default location, ask
your System Administrator to nd out where your de-
fault location is for <DS_COMMON_DIR>.
<DS_USER_DIR>
The environment variable for the user-specic conguration
directory for the Data Services system.
Default location:
• If you're on Windows (Vista and newer):
<UserProfile>\AppData\Local\SAP
BusinessObjects\Data Services
Note
The default value of <UserProfile> environment
variable for Windows Vista and newer versions is
C:\Users\{username}.
• If you're on Windows (Older versions such as XP):
<UserProfile>\Local
Settings\Application Data\SAP
BusinessObjects\Data Services
Note
The default value of <UserProfile> en-
vironment variable for Windows older ver-
sions is C:\Documents and Settings\
{username}.
Note
The system uses <DS_USER_DIR> only for Data
Services client applications on Windows. UNIX plat-
forms don't use <DS_USER_DIR>.
The installer automatically creates this system environment
variable during installation.
Data Services Supplement for Big Data
Naming conventions and variables
PUBLIC 9
3 Big data in SAP Data Services
SAP Data Services supports many types of big data through various object types and le formats.
Apache Cassandra [page 10]
Apache Cassandra is an open-source data storage system that you can access with SAP Data Services.
Apache Hadoop [page 13]
Use SAP Data Services to connect to Apache Hadoop frameworks including Hadoop Distributive File
Systems (HDFS) and Hive.
HP Vertica [page 16]
Access HP Vertica data by creating an HP Vertica database datastore in SAP Data Services Designer.
MongoDB [page 32]
To read data from MongoDB sources and load data to other SAP Data Services targets, create a
MongoDB adapter.
Apache Impala [page 44]
Create an ODBC datastore to connect to Apache Impala in Hadoop.
PostgreSQL [page 48]
To use your PostgreSQL tables as sources and targets in SAP Data Services, create a PostgreSQL
datastore and import your tables and other metadata.
SAP HANA [page 58]
Process your SAP HANA data in SAP Data Services by creating an SAP HANA database datastore.
Amazon Athena [page 80]
Use the Simba Athena ODBC driver to connect to Amazon Athena.
3.1 Apache Cassandra
Apache Cassandra is an open-source data storage system that you can access with SAP Data Services.
Data Services natively supports Cassandra as an ODBC data source with a DSN connection. Cassandra uses
the generic ODBC driver. Use Cassandra on Windows or Linux operating systems.
Use Cassandra data for the following tasks:
• Use as sources, targets, or template tables
• Preview data
• Query using distinct, where, group by, and order by
• Write scripts using functions such as math, string, date, aggregate, and ifthenelse
Before you use Cassandra with Data Services, ensure that you perform the following setup tasks:
• Add the appropriate environment variables to the al_env.sh le.
• For Data Services on Linux platforms, congure the ODBC driver using the Connection Manager.
10
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Note
For Data Services on Windows platforms, use the generic ODBC driver.
For more information about conguring database connectivity for UNIX and Linux, see the Administrator Guide.
Setting ODBC driver conguration on Linux [page 11]
Use the Connection Manager to congure the ODBC driver for Apache Cassandra on Linux.
Data source properties for Cassandra [page 12]
Complete data source properties in the Connection Manager when you congure the ODBC driver for
SAP Data Services on Linux.
3.1.1Setting ODBC driver conguration on Linux
Use the Connection Manager to congure the ODBC driver for Apache Cassandra on Linux.
Before you complete the following steps, read the topic and subtopics under “Congure database connectivity
for UNIX and Linux” in the Administrator Guide.
Use the GTK+2 library to make a graphical user interface for the Connection Manager. Connection Manager is
a command-line utility. To use it with a UI, install the GTK+2 library. For more information about obtaining and
installing GTK+2, see https://www.gtk.org/ . The following steps are for the UI for Connection Manager.
1. Open a command prompt and set $ODBCINI to a le in which the Connection Manager denes the DSN.
Ensure that the le is readable and writable.
Sample Code
$ export ODBCINI=<dir-path>/odbc.ini
touch $ODBCINI
The Connection Manager uses the $ODBCINI le and other information that you enter for data sources, to
dene the DSN for Cassandra.
Note
Do not point to the Data Services ODBC .ini le.
2. Start the Connection Manager user interface by entering the following command:
Sample Code
$ cd <LINK_DIR>/bin/
$ /DSConnectionManager.sh
Note
<LINK_DIR> is the Data Services installation directory.
3. In Connection Manager, open the Data Sources tab, and click Add to display the list of database types.
4. In the Select Database Type dialog box, select Cassandra and click OK.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 11

The Conguration for... dialog box opens. It contains the absolute location of the odbc.ini le that you set
in the rst step.
5. Provide values for additional connection properties for the Cassandra database type as applicable.
6. Provide the following properties:
• User name
• Password
Note
Data Services does not save these properties for other users.
7. To test the connection, click Test Connection.
8. Click Restart Services to restart services applicable to the Data Services installation location:
If Data Services is installed on the same machine and in the same folder as the IPS or BI platform, restart
the following services:
• EIM Adaptive Process Service
• Data Services Job Service
If Data Services is not installed on the same machine and in the same folder as the IPS or BI platform,
restart the following service:
• Data Services Job Service
Task overview: Apache Cassandra [page 10]
Related Information
Data source properties for Cassandra [page 12]
3.1.2Data source properties for Cassandra
Complete data source properties in the Connection Manager when you congure the ODBC driver for SAP Data
Services on Linux.
The Connection Manager congures the $ODBCINI le based on the property values that you enter in the Data
Sources tab. The following table lists the properties that are relevant for Apache Cassandra.
12
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Data Source settings for Apache Cassandra
Database Type Properties on Data Sources tab
Apache Cassandra
• User Name
• Database password
• Host Name
• Port
• Database
• Unix ODBC Lib Path
• Driver
• Cassandra SSL Certicate Mode [0:disabled|1:one-way|2:two-way]
Depending on the value you choose for the certicate mode, Data Services may
require you to dene some or all of the following options:
• Cassandra SSL Server Certicate File
• Cassandra SSL Client Certicate File
• Cassandra SSL Client Key File
• Cassandra SSL Client Key Password
• Cassandra SSL Validate Server Hostname? [0:disabled|1:enabled]
Parent topic: Apache Cassandra [page 10]
Related Information
Setting ODBC driver conguration on Linux [page 11]
3.2 Apache Hadoop
Use SAP Data Services to connect to Apache Hadoop frameworks including Hadoop Distributive File Systems
(HDFS) and Hive.
Data Services supports Hadoop on both the Linux and Windows platform. For Windows support, Data Services
uses Hortonworks Data Platform (HDP) only. HDP allows data from many sources and formats. See the latest
Product Availability Matrix (PAM) on the SAP Support Portal for the supported versions of HDP.
For information about deploying Data Services on a Hadoop MapR cluster machine, see SAP Note 2404486
.
For information about accessing your Hadoop in the administered SAP Big Data Services, see the Supplement
for SAP Big Data Services.
For complete information about how Data Services supports Apache Hadoop, see the Supplement for Hadoop.
Hadoop Distributed File System (HDFS) [page 14]
Connect to your HDFS data using an HDFS le format or an HDFS le location in SAP Data Services
Designer.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 13
Hadoop Hive [page 14]
Use a Hive adapter datastore or a Hive database datastore in SAP Data Services Designer to connect to
the Hive remote server.
Upload data to HDFS in the cloud [page 15]
Upload data processed with Data Services to your HDFS that is managed by SAP Big Data Services.
Google Cloud Dataproc clusters [page 15]
To connect to an Apache Hadoop web interface running on Google Cloud Dataproc clusters, use a Hive
database datastore and a WebHDFS le location.
3.2.1Hadoop Distributed File System (HDFS)
Connect to your HDFS data using an HDFS le format or an HDFS le location in SAP Data Services Designer.
Create an HDFS le format and le location with your HDFS connection information, such as the account
name, password, and security protocol. Data Services uses this information to access HDFS data during Data
Services processing.
For complete information about how Data Services supports your HDFS, see the Supplement for Hadoop.
Parent topic: Apache Hadoop [page 13]
Related Information
Hadoop Hive [page 14]
Upload data to HDFS in the cloud [page 15]
Google Cloud Dataproc clusters [page 15]
3.2.2Hadoop Hive
Use a Hive adapter datastore or a Hive database datastore in SAP Data Services Designer to connect to the
Hive remote server.
Use the Hive adapter datastore when Data Services is installed within the Hadoop cluster. Use the Hive
adapter datastore for server-named (DSN-less) connections. Also include SSL (or the newer Transport Layer
Security TLS) for secure communication over the network.
Use a Hive database datastore when Data Services is installed on a machine either within or outside of the
Hadoop cluster. Use the Hive database datastore for either a DSN or a DSN-less connection. Also include
SSL/TLS for secure communication over the network.
For complete information about how Data Services supports Hadoop Hive, see the Supplement for Hadoop.
Parent topic: Apache Hadoop [page 13]
14
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Related Information
Hadoop Distributed File System (HDFS) [page 14]
Upload data to HDFS in the cloud [page 15]
Google Cloud Dataproc clusters [page 15]
3.2.3Upload data to HDFS in the cloud
Upload data processed with Data Services to your HDFS that is managed by SAP Big Data Services.
Big Data Services is a Hadoop distribution in the cloud. Big Data Services performs all Hadoop upgrades and
patches for you and provides Hadoop support. SAP Big Data Services was formerly known as Altiscale.
Upload your big data les directly from your computer to Big Data Services. Or, upload your big data les from
your computer to an established cloud account, and then to Big Data Services.
Example
Access data from S3 (Amazon Simple Storage Service) and use the data as a source in Data Services. Then
upload the data to your HDFS that resides in Big Data Service in the cloud.
How you choose to upload your data is based on your use case.
For complete information about accessing your Hadoop account in Big Data Services and uploading big data,
see the Supplement for SAP Big Data Services.
Parent topic: Apache Hadoop [page 13]
Related Information
Hadoop Distributed File System (HDFS) [page 14]
Hadoop Hive [page 14]
Google Cloud Dataproc clusters [page 15]
3.2.4Google Cloud Dataproc clusters
To connect to an Apache Hadoop web interface running on Google Cloud Dataproc clusters, use a Hive
database datastore and a WebHDFS le location.
Use a Hive datastore to browse and view metadata from Hadoop and to import metadata for use in data ows.
To upload processed data, use a Hadoop le location and a Hive template table. Implement bulk loading in the
target editor in a data ow where you use the Hive template table as a target.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 15
For complete information about how SAP Data Services supports Google Cloud Dataproc clusters, see the
Supplement for Hadoop.
Parent topic: Apache Hadoop [page 13]
Related Information
Hadoop Distributed File System (HDFS) [page 14]
Hadoop Hive [page 14]
Upload data to HDFS in the cloud [page 15]
3.3 HP Vertica
Access HP Vertica data by creating an HP Vertica database datastore in SAP Data Services Designer.
Use HP Vertica data as sources or targets in data ows. Implement SSL secure data transfer with MIT Kerberos
to access HP Vertica data securely. Additionally, congure options in the source or target table editors to
enhance HP Vertica performance.
Enable MIT Kerberos for HP Vertica SSL protocol [page 17]
SAP Data Services uses MIT Kerberos 5 authentication to securely access an HP Vertica database
using SSL protocol.
Creating a DSN for HP Vertica with Kerberos SSL [page 21]
To enable SSL for HP Vertica database datastores, rst create a data source name (DSN).
Creating HP Vertica datastore with SSL encryption [page 23]
To enable SSL encryption for HP Vertica datastores, you must create a Data Source Name (DSN)
connection.
Increasing loading speed for HP Vertica [page 24]
SAP Data Services doesn't support bulk loading for HP Vertica, but there are settings you can make to
increase loading speed.
HP Vertica data type conversion [page 25]
SAP Data Services converts incoming HP Vertica data types to native data types, and outgoing native
data types to HP Vertica data types.
HP Vertica table source [page 27]
Congure options for an HP Vertica table as a source by opening the source editor in the data ow.
HP Vertica target table conguration [page 28]
Congure options for an HP Vertica table as a target by opening the target editor in the data ow.
16
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

3.3.1Enable MIT Kerberos for HP Vertica SSL protocol
SAP Data Services uses MIT Kerberos 5 authentication to securely access an HP Vertica database using SSL
protocol.
You must have Database Administrator permissions to install MIT Kerberos 5 on your Data Services client
machine. Additionally, the Database Administrator must establish a Kerberos Key Distribution Center (KDC)
server for authentication. The KDC server must support Kerberos 5 using the Generic Security Service (GSS)
API. The GSS API also supports non_MIT Kerberos implementations, such as Java and Windows clients.
Note
Specic Kerberos and HP Vertica database processes are required before you can enable SSL protocol in
Data Services. For complete explanations and processes for security and authentication, consult your HP
Vertica user documentation and the MIT Kerberos user documentation.
MIT Kerberos authorizes connections to the HP Vertica database using a ticket system. The ticket system
eliminates the need for users to enter a password.
Edit conguration or initialization le [page 18]
After you install MIT Kerberos, dene the specic Kerberos properties in the Kerberos conguration or
initialization le.
Generate secure key with kinit command [page 21]
After you've updated the conguration or initialization le and saved it to the client domain, execute the
kinit command to generate a secure key.
Parent topic: HP Vertica [page 16]
Related Information
Creating a DSN for HP Vertica with Kerberos SSL [page 21]
Creating HP Vertica datastore with SSL encryption [page 23]
Increasing loading speed for HP Vertica [page 24]
HP Vertica data type conversion [page 25]
HP Vertica table source [page 27]
HP Vertica target table conguration [page 28]
Edit conguration or initialization le [page 18]
Generate secure key with kinit command [page 21]
Creating a DSN for HP Vertica with Kerberos SSL [page 21]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 17
3.3.1.1 Edit conguration or initialization le
After you install MIT Kerberos, dene the specic Kerberos properties in the Kerberos conguration or
initialization le.
After you dene Kerberos properties, save the conguration or initialization le to your domain.
Example
Save the initialization le named krb5.ini to C:\Windows.
See the MIT Kerberos documentation for information about completing the Unix krb5.conf property le or
the Windows krb5.ini property le.
Log le locations for Kerberos
The following table describes log le names and locations for the Kerberos log les.
Log le
Property File name and location
Kerberos library log le
default = <value>
krb5libs.log.
Example
default = FILE:/var/log/
krb5libs.log
Kerberos Data Center log le
kdc = <value>
krb5kdc.log.
Example
kdc = FILE:/var/log/
krb5kdc.log
Administrator log le
admin_server = <value>
kadmind.log.
Example
admin_server
= FILE:/var/log/
kadmind.log
Kerberos 5 library settings
The following table describes the Kerberos 5 library settings.
18
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Property Description
default_realm = <VALUE> <VALUE> = the location of your domain.
Example
default_realm = EXAMPLE.COM
Domain location value must be in all capital letters.
dns_lookup_realm = <value>
Set to False: dns_lookup_realm = false
dns_lookup_kdc = <value>
Set to False: dns_lookup_kdc = false
ticket_lifetime = <value> Set number of hours for the initial ticket request.
Example
ticket_lifetime = 24h
The default is 24h.
renew_lifetime = <value> Set number of days a ticket can be renewed after the ticket
lifetime expiration.
Example
renew_lifetime = 7d
The default is 0.
forwardable = <value>
Set to True to forward initial tickets: forwardable =
true
Kerberos realm
The following table describes the Kerberos realm property.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 19
Property Description
<kerberos_realm> = {<subsection_property =
value>}
Location for each property of the Kerberos realm.
Example
EXAMPLE.COM = {kdc=<location>
admin_server=<location>
kpasswd_server=<location>}
Properties include the following:
• KDC location
• Admin Server location
• Kerberos Password Server location
Note
Enter host and server names in lowercase.
Kerberos domain realm
The following table describes the property for the Kerberos domain realm.
Property Description
<server_host_name>=<kerberos_realm> Maps the server host name to the Kerberos realm name. If
you use a domain name, prex the name with a period (.).
Parent topic: Enable MIT Kerberos for HP Vertica SSL protocol [page 17]
Related Information
Generate secure key with kinit command [page 21]
20
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

3.3.1.2 Generate secure key with kinit command
After you've updated the conguration or initialization le and saved it to the client domain, execute the kinit
command to generate a secure key.
Example
Enter the following command using your own information for the variables: kinit
<user_name>@<realm_name>
The following table describes the keys that the command generates.
Key Description
-k
Precedes the service name portion of the Kerberos principal.
The default is vertica.
-K
Precedes the instance or host name portion of the Kerberos
principal.
-h
Precedes the machine host name for the server.
-d
Precedes the HP Vertica database name with which to con-
nect.
-U
Precedes the user name of the administrator user.
For complete information about using the kinit command to obtain tickets, see the MIT Kerberos Ticket
Management documentation.
Parent topic: Enable MIT Kerberos for HP Vertica SSL protocol [page 17]
Related Information
Edit conguration or initialization le [page 18]
3.3.2Creating a DSN for HP Vertica with Kerberos SSL
To enable SSL for HP Vertica database datastores, rst create a data source name (DSN).
This procedure is for HP Vertica users who have database administrator permissions to perform these steps, or
who have been associated with an authentication method through a GRANT statement.
Note
DSN for HP Vertica is available in SAP Data Services version 4.2 SP7 Patch 1 (14.2.7.1) or later.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 21

Before you perform the following steps, install MIT Kerberos 5 and perform all of the required steps for MIT
Kerberos authentication for HP Vertica. See your HP Vertica documentation in the security and authentication
sections for details.
To create a DSN for HP Vertica with Kerberos SSL, perform the following steps:
1. Open the ODBC Data Source Administrator.
Access the ODBC Data Source Administrator either from the Datastore Editor in Data Services Designer or
directly from your Start menu.
2. Open the System DSN tab and select Add.
3. Choose the applicable HP Vertica driver from the list and select Finish.
4. Open the Basic Settings tab and complete the options as described in the following table.
HP Vertica ODBC DSN Conguration Basic Settings tab
Option Value
DSN Enter the HP Vertica data source name.
Description Optional. Enter a description for this data source.
Database Enter the name of the database that is running on the
server.
Server Enter the server name.
Port Enter the port number on which HP Vertica listens for
ODBC connections.
The default port is 5433.
User Name Enter the database user name.
The database user must have DBADMIN permission
or must be associated with the authentication method
through a GRANT statement.
5. Optional: Select Test Connection.
If the connection fails, either continue with the conguration and x the connection issue later, or
recongure the connection information and test the connection again.
6. Open the Client Settings tab and complete the options as described in the following table.
HP Vertica ODBC DSN Conguration Client Settings tab
Option Value
Kerberos Host Name Enter the name of the host computer where Kerberos is
installed.
Kerberos Service Name Enter the applicable value.
SSL Mode Select Require.
22 PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Option Value
Address Family Preference Select None.
Autocommit Select this option.
Driver String Conversions Select Output.
Result Buer Size (bytes) Enter the applicable value in bytes.
The default value is 131072.
Three Part Naming Select this option.
Log Level Select No logging from the dropdown list.
7. Select Test Connection.
When the connection test is successful, select OK and close the ODBC Data Source Administrator.
Now the HP Vertica DSN that you just created is included in the DSN option in the datastore editor.
Create the HP Vertica database datastore in Data Services Designer and select the DSN that you created.
Task overview: HP Vertica [page 16]
Related Information
Enable MIT Kerberos for HP Vertica SSL protocol [page 17]
Creating HP Vertica datastore with SSL encryption [page 23]
Increasing loading speed for HP Vertica [page 24]
HP Vertica data type conversion [page 25]
HP Vertica table source [page 27]
HP Vertica target table conguration [page 28]
3.3.3Creating HP Vertica datastore with SSL encryption
To enable SSL encryption for HP Vertica datastores, you must create a Data Source Name (DSN) connection.
Before you perform the following steps, an administrator must install MIT Kerberos 5, and enable Kerberos for
HP Vertica SSL protocol.
Additionally, an administrator must create an SSL DSN using the ODBC Data Source Administrator. For more
information about conguring SSL DSN with ODBC drivers, see Congure drivers with data source name
(DSN) connections in the Administrator Guide.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 23

Note
SSL encryption for HP Vertica is available in SAP Data Services version 4.2 Support Package 7 Patch 1
(14.2.7.1) or later. Enabling SSL encryption slows down job performance.
Note
An HP Vertica database datastore requires that you choose DSN as a connection method. DSN-less
connections aren't allowed for HP Vertica datastore with SSL encryption.
To create an HP Vertica datastore with SSL encryption, perform the following steps in Data Services Designer:
1. Select Project New Datastore.
The Datastore editor opens.
2. Complete the regular HP Vertica database datastore options.
Choose the HP Vertica client version from the Database version list, and enter your user name and
password.
3. Select Use Data Source Name (DSN).
4. Choose the HP Vertica SSL DSN that you created from the Data Source Name list.
5. Complete the applicable Advanced options and save your datastore.
Task overview: HP Vertica [page 16]
Related Information
Enable MIT Kerberos for HP Vertica SSL protocol [page 17]
Creating a DSN for HP Vertica with Kerberos SSL [page 21]
Increasing loading speed for HP Vertica [page 24]
HP Vertica data type conversion [page 25]
HP Vertica table source [page 27]
HP Vertica target table conguration [page 28]
3.3.4Increasing loading speed for HP Vertica
SAP Data Services doesn't support bulk loading for HP Vertica, but there are settings you can make to increase
loading speed.
For complete details about connecting to HP Vertica, see Connecting to Vertica in the Vertica
documentation. Make sure to select the correct version.
When you load data to an HP Vertica target in a data ow, the software automatically executes an HP Vertica
statement that contains a COPY Local statement. This statement makes the ODBC driver read and stream
the data le from the client to the server.
24
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

You can further increase loading speed by increasing rows per commit and enable use native connection load
balancing:
1. when you congure the ODBC driver for HP Vertica, enable the option to use native connection load
balancing.
2. In Designer, open the applicable data ow.
3. In the workspace, double-click the HP Vertica datastore target object to open it.
4. Open the Options tab in the lower pane.
5. Increase the number of rows in the Rows per commit option.
Task overview: HP Vertica [page 16]
Related Information
Enable MIT Kerberos for HP Vertica SSL protocol [page 17]
Creating a DSN for HP Vertica with Kerberos SSL [page 21]
Creating HP Vertica datastore with SSL encryption [page 23]
HP Vertica data type conversion [page 25]
HP Vertica table source [page 27]
HP Vertica target table conguration [page 28]
3.3.5HP Vertica data type conversion
SAP Data Services converts incoming HP Vertica data types to native data types, and outgoing native data
types to HP Vertica data types.
The following table contains HP Vertica data types and the native data types to which Data Services converts
them.
HP Vertica data type Data Services data type
Boolean Int
Integer, INT, BIGINT, INT8, SMALLINT, TINYINT Decimal
FLOAT Double
Money Decimal
Numeric Decimal
Number Decimal
Decimal Decimal
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 25

HP Vertica data type Data Services data type
Binary, Varbinary, Long Varbinary Blob
Long Varchar Long
Char Varchar
Varchar Varchar
Char(n), Varchar(n) Varchar(n)
DATE Date
TIMESTAMP Datetime
TIMESTAMPTZ Varchar
Time Time
TIMETZ Varchar
INTERVAL Varchar
The following table contains native data types and the HP Vertica data types to which Data Services outputs
them. Data Services outputs the converted data types to HP Vertica template tables or Data_Transfer
transform tables.
Data Services data type HP Vertica data type
Blob Long Varbinary
Date Date
Datetime Timestamp
Decimal Decimal
Double Float
Int Int
Interval Float
Long Long Varchar
Real Float
Time Time
Varchar Varchar
26 PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Data Services data type HP Vertica data type
Timestamp Timestamp
Parent topic: HP Vertica [page 16]
Related Information
Enable MIT Kerberos for HP Vertica SSL protocol [page 17]
Creating a DSN for HP Vertica with Kerberos SSL [page 21]
Creating HP Vertica datastore with SSL encryption [page 23]
Increasing loading speed for HP Vertica [page 24]
HP Vertica table source [page 27]
HP Vertica target table conguration [page 28]
3.3.6HP Vertica table source
Congure options for an HP Vertica table as a source by opening the source editor in the data ow.
HP Vertica source table options
Option Description
Table name Species the table name for the source table.
Table owner Species the table owner.
You cannot edit the value. Data Services automatically popu-
lates with the name that you entered when you created the
HP Vertica table.
Datastore name Species the name of the related HP Vertica datastore.
Database type Species the database type.
You cannot edit this value. Data Services automatically pop-
ulates with the database type that you chose when you cre-
ated the datastore.
Parent topic: HP Vertica [page 16]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 27

Related Information
Enable MIT Kerberos for HP Vertica SSL protocol [page 17]
Creating a DSN for HP Vertica with Kerberos SSL [page 21]
Creating HP Vertica datastore with SSL encryption [page 23]
Increasing loading speed for HP Vertica [page 24]
HP Vertica data type conversion [page 25]
HP Vertica target table conguration [page 28]
3.3.7HP Vertica target table conguration
Congure options for an HP Vertica table as a target by opening the target editor in the data ow.
Options tab General options
Option Description
Column comparison Species how the software maps input columns to output
columns:
• Compare by position: Maps source columns to target
columns by position, and ignores column names.
• Compare by name: Maps source columns to target col-
umns by column name. Compare by name is the default
setting.
Data Services issues validation errors when the data types of
the columns do not match.
28 PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Option Description
Number of loaders Species the number of loaders Data Services uses to load
data to the target.
Enter a positive integer. The default is 1.
There are dierent types of loading:
• Single loader loading: Loading with one loader.
• Parallel loading: Loading with two or more loaders.
With parallel loading, each loader receives the number of
rows indicated in the Rows per commit option, and proc-
esses the rows in parallel with other loaders.
Example
For example, if Rows per commit = 1000 and Number of
Loaders = 3:
• First 1000 rows go to the rst loader
• Second 1000 rows go to the second loader
• Third 1000 rows go to the third loader
• Fourth 1000 rows go to the rst loader
Options tab Error handling options
Option Description
Use overow le Species whether Data Services uses a recovery le for rows
that it could not load.
• No: Data Services does not save information about un-
loaded rows. The default setting is No.
• Yes: Data Services loads data to an overow le when it
cannot load a row. When you select Yes, also complete
File Name and File Format.
File name
File format
Species the le name and le format for the overow le.
Applicable only when you select Yes for Use overow le.
Enter a le name or specify a variable
The overow le can include the data rejected and the oper-
ation being performed (write_data) or the SQL command
used to produce the rejected operation (write_sql).
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 29
Update control
Option Description
Use input keys Species whether Data Services uses the primary keys from
the input table when the target table does not have a pri-
mary key.
• Yes: Uses the primary keys from the input table when
the target table does not have primary keys.
• No: Does not use primary keys from the input table
when the target table does not have primary keys. No is
the default setting.
Update key columns Species whether Data Services updates key column values
when it loads data to the target table.
• Yes: Updates key column values when it loads data to
the target table.
• No: Does not update key column values when it loads
data to the target table. No is the default setting.
Auto correct load Species whether Data Services uses auto correct loading
when it loads data to the target table. Auto correct loading
ensures that Data Services does not duplicate the same row
in a target table. Auto correct load is useful for data recovery
operations.
• Yes: Uses auto correct loading.
Note
Not applicable for targets in real time jobs or target
tables that contain LONG columns.
• No: Does not use auto correct loading. No is the default
setting.
For more information about auto correct loading, read about
recovery mechanisms in the Designer Guide.
Ignore columns with value Species a value that might appear in a source column and
that you do not want updated in the target table during auto
correct loading.
Enter a string excluding single or double quotation marks.
The string can include spaces.
When Data Services nds the string in the source column,
it does not update the corresponding target column during
auto correct loading.
30 PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Transaction control
Option Description
Include in transaction Species that this target table is included in the transaction
processed by a batch or real-time job.
• No: This target table is not included in the transaction
processed by a batch or real-time job. No is the default
setting
• Yes: The target table is included in the transaction proc-
essed by a batch or real-time job. Selecting Yes enables
Data Services to commit data to multiple tables as part
of the same transaction. If loading fails for any of the
tables, Data Services does not commit any data to any
of the tables.
Note
Ensure that the tables are from the same datastore.
Data Services does not push down a complete opera-
tion to the database when transactional loading is ena-
bled.
Data Services may buer rows to ensure the correct load
order. If the buered data is larger than the virtual memory
available, Data Services issues a memory error.
If you choose to enable transactional loading, the following
options are not available:
• Rows per commit
• Use overow le and overow le specication
• Number of loaders
Parent topic: HP Vertica [page 16]
Related Information
Enable MIT Kerberos for HP Vertica SSL protocol [page 17]
Creating a DSN for HP Vertica with Kerberos SSL [page 21]
Creating HP Vertica datastore with SSL encryption [page 23]
Increasing loading speed for HP Vertica [page 24]
HP Vertica data type conversion [page 25]
HP Vertica table source [page 27]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 31
3.4 MongoDB
To read data from MongoDB sources and load data to other SAP Data Services targets, create a MongoDB
adapter.
MongoDB is an open-source document database, which has JSON-like documents called BSON. MongoDB has
dynamic schemas instead of traditional schema-based data.
Data Services needs metadata to gain access to MongoDB data for task design and execution. Use Data
Services processes to generate schemas by converting each row of the BSON le into XML and converting XML
to XSD.
Data Services uses the converted metadata in XSD les to access MongoDB data.
To learn more about Data Services adapters, see the Supplement for Adapters.
MongoDB metadata [page 32]
Use metadata from a MongoDB adapter datastore to create sources, targets, and templates in a data
ow.
MongoDB as a source [page 33]
Use MongoDB as a source in Data Services and atten the nested schema by using the XML_Map
transform.
MongoDB as a target [page 36]
Congure options for MongoDB as a target in your data ow using the target editor.
MongoDB template documents [page 39]
Use template documents as a target in one data ow or as a source in multiple data ows.
Preview MongoDB document data [page 41]
Use the data preview feature in SAP Data Services Designer to view a sampling of data from a
MongoDB document.
Parallel Scan [page 42]
SAP Data Services uses the MongoDB Parallel Scan process to improve performance while it generates
metadata for big data.
Reimport schemas [page 43]
When you reimport documents from your MongoDB datastore, SAP Data Services uses the current
datastore settings.
Searching for MongoDB documents in the repository [page 44]
SAP Data Services enables you to search for MongoDB documents in your repository from the object
library.
3.4.1MongoDB metadata
Use metadata from a MongoDB adapter datastore to create sources, targets, and templates in a data ow.
MongoDB represents its embedded documents and arrays as nested data in BSON les. SAP Data Services
converts MongoDB BSON les to XML and then to XSD. Data Services saves the XSD le to the following
location: <LINK_DIR>\ext\mongo\mcache.
32
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Restrictions and limitations
Data Services has the following restrictions and limitations for working with MongoDB:
• In the MongoDB collection, the tag name can't contain special characters that are invalid for the XSD le.
Example
The following special characters are invalid for XSD les: >, <, &,/, \, #, and so on.
If special characters exist, Data Services removes them.
• Because MongDB data is always changing, the XSD doesn't always reect the entire data structure of all
the documents in the MongoDB.
• Data Services doesn't support projection queries on adapters.
• Data Services ignores any new elds that you add after the metadata schema creation that aren't present
in the common documents.
• Data Services doesn't support push down operators when you use MongoDB as a target.
For more information about formatting XML documents, see the Nested Data section in the Designer Guide. For
more information about source and target objects, see the Data ows section of the Designer Guide.
Parent topic: MongoDB [page 32]
Related Information
MongoDB as a source [page 33]
MongoDB as a target [page 36]
MongoDB template documents [page 39]
Preview MongoDB document data [page 41]
Parallel Scan [page 42]
Reimport schemas [page 43]
Searching for MongoDB documents in the repository [page 44]
3.4.2MongoDB as a source
Use MongoDB as a source in Data Services and atten the nested schema by using the XML_Map transform.
The following examples illustrate how to use various objects to process MongoDB sources in data ows.
Example 1: Change the schema of a MongoDB source using the Query transform, and load output to an XML
target.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 33
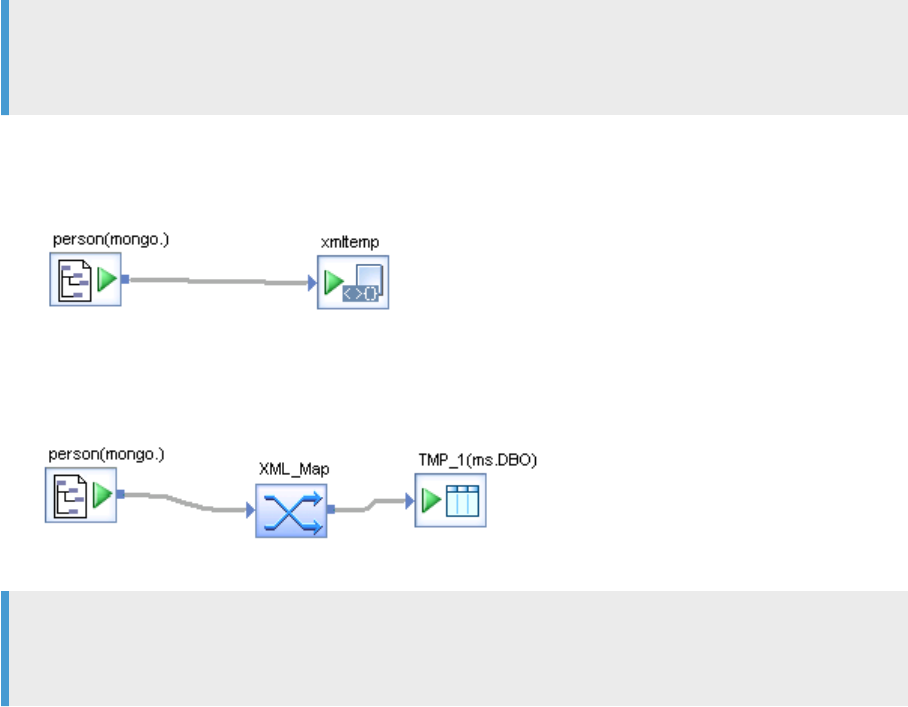
Note
Specify conditions in the Query transform. Some conditions can be pushed down and others are processed
by Data Services.
Example 2: Set a dataow where Data Services reads the schema and then loads the schema directly into an
XML template le.
Example 3: Flatten a schema using the XML_Map transform and then load the data to a table or at le.
Note
Specify conditions in the XML_Map transform. Some conditions can be pushed down and others are
processed by Data Services.
MongoDB query conditions [page 35]
Use query criteria to retrieve documents from a MongoDB collection.
Push down operator information [page 35]
SAP Data Services processes push down operators with a MongoDB source in specic ways based on
the circumstance.
Parent topic: MongoDB [page 32]
Related Information
MongoDB metadata [page 32]
MongoDB as a target [page 36]
MongoDB template documents [page 39]
Preview MongoDB document data [page 41]
Parallel Scan [page 42]
Reimport schemas [page 43]
Searching for MongoDB documents in the repository [page 44]
MongoDB query conditions [page 35]
34
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Push down operator information [page 35]
3.4.2.1 MongoDB query conditions
Use query criteria to retrieve documents from a MongoDB collection.
Use query criteria as a parameter of the db.<collection>.find() method. Add MongoDB query conditions
to a MongoDB table as a source in a data ow.
To add a MongoDB query format, enter a value next to the Query criteria parameter in the source editor
Adapter Source tab. Ensure that the query criteria is in MongoDB query format. For example, { type:
{ $in: [‘food’, ’snacks’] } }
Example
Given a value of {prize:100}, MongoDB returns only rows that have a eld named “prize” with a value of
100. If you don’t specify the value 100, MongoDB returns all the rows.
Congure a Where condition so that Data Services pushes down the condition to MongoDB. Specify a Where
condition in a Query or XML_Map transform, and place the Query or XML_Map transform after the MongoDB
source object in the data ow. MongoDB returns only the rows that you want.
For more information about the MongoDB query format, consult the MongoDB Web site.
Note
If you use the XML_Map transform, it may have a query condition with a SQL format. Data Services
converts the SQL format to the MongoDB query format and uses the MongoDB specication to push down
operations to the source database. In addition, be aware that Data Services does not support push down of
query for nested arrays.
Parent topic: MongoDB as a source [page 33]
Related Information
Push down operator information [page 35]
Push down operator information [page 35]
3.4.2.2 Push down operator information
SAP Data Services processes push down operators with a MongoDB source in specic ways based on the
circumstance.
Push down behavior:
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 35

• Data Services does not push down Sort by conditions.
• Data Services pushes down Where conditions.
• Data Services does not push down the nested array when you use a nested array in a Where condition.
• Data Services does not support push down operators when you use MongoDB as a target.
Data Services supports the following operators when you use MongoDB as a source:
• Comparison operators: =, !=, >, >=, <, <=, like, and in.
• Logical operators: and and or in SQL query.
Parent topic: MongoDB as a source [page 33]
Related Information
MongoDB query conditions [page 35]
3.4.3MongoDB as a target
Congure options for MongoDB as a target in your data ow using the target editor.
About the <_id> eld
SAP Data Services considers the <_id> eld in MongoDB data as the primary key. If you create a new
MongoDB document and include a eld named <_id>, Data Services recognizes that eld as the unique
BSON ObjectID. If a MongoDB document contains more than one <_id> eld at dierent levels, Data Services
considers only the <_id> eld at the rst level as the BSON Object Id.
The following table contains descriptions for options in the Adapter Target tab of the target editor.
Adapter Target tab options
Option
Description
Use auto correct Species the mode Data Services uses for MongoDB as a target datastore.
• True: Uses Upsert mode for the writing behavior. Updates the document with the same
<_id> eld or it inserts a new <_id> eld.
Note
Selecting True may slow the performance of writing operations.
• False: Uses Insert mode for writing behavior. If documents have the same <_id> eld in
the MongoDB collection, then Data Services issues an error message.
36 PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Option Description
Write concern level
Species the MongoDB write concern level that Data Services uses for reporting the success
of a write operation. Enable or disable dierent levels of acknowledgement for writing opera-
tions.
• Acknowledged: Provides acknowledgment of write operations on a standalone mongod or
the primary in a replica set. Acknowledged is the default setting.
• Unacknowledged: Disables the basic acknowledgment and only returns errors of socket
exceptions and networking errors.
• Replica Set Acknowledged: Guarantees that write operations have propagated success-
fully to the specied number of replica set members, including the primary.
• Journaled: Acknowledges the write operation only after MongoDB has committed the
data to a journal.
• Majority: Conrms that the write operations have propagated to the majority of voting
nodes.
Use bulk
Species whether Data Services executes writing operations in bulk. Bulk may provide better
performance.
• True: Runs write operation in bulk for a single collection to optimize the CRUD eciency.
If the write operation in a bulk is more than 1000, MongoDB automatically splits into
multiple bulk groups.
• False: Does not run write operation in bulk.
For more information about bulk, ordered bulk, and bulk maximum rejects, see the Mon-
goDB documentation at http://help.sap.com/disclaimer?site=http://docs.mongodb.org/man-
ual/core/bulk-write-operations/.
Use ordered bulk
Species the order in which Data Services executes write operations: Serial or Parallel.
• True: Executes write operations in serial.
• False: Executes write operations in parallel. False is the default setting. MongoDB proc-
esses the remaining write operations even when there are errors.
Documents per commit
Species the maximum number of documents that are loaded to a target before the software
saves the data.
• Blank: Uses the maximum of 1000 documents. Blank is the default setting.
• Enter any integer to specify a number other than 1000.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 37
Option Description
Bulk maximum rejects
Species the maximum number of acceptable errors before Data Services fails the job.
Note
Data Services continues to load to the target MongoDB even when the job fails.
Enter an integer. Enter -1 so that Data Services ignores and does not log bulk loading errors.
If the number of actual errors is less than, or equal to the number you specify here, Data
Services allows the job to succeed and logs a summary of errors in the adapter instance trace
log.
Applicable only when you select True for Use ordered bulk.
Delete data before loading
Deletes existing documents in the current collection before loading occurs. Retains all the
conguration, including indexes, validation rules, and so on.
Drop and re-create
Species whether Data Services drops the existing MongoDB collection and creates a new one
with the same name before loading occurs.
• True: Drops the existing MongoDB collection and creates a new one with the same name
before loading. Ignores the value of Delete data before loading. True is the default setting.
• False: Does not drop the existing MongoDB collection and create a new one with the same
name before loading.
This option is available for template documents only.
Use audit
Species whether Data Services creates audit les that contain write operation information.
• True: Creates audit les that contain write operation information. Stores audit les
in the <DS_COMMON_DIR>/adapters/audits/ directory. The name of the le is
<MongoAdapter_instance_name>.txt.
• False: Does not create and store audit les.
Data Services behaves in the following way when a regular load fails:
• Use audit = False: Data Services logs loading errors in the job trace log.
• Use audit = True: Data Services logs loading errors in the job trace log and in the audit log.
Data Services behaves in the following way when a bulk load fails:
• Use audit = False: Data Services creates a job trace log that provides only a summary. It
does not contain details about each row of bad data. There is no way to obtain details
about bad data.
• Use audit = True: Data Services creates a job trace log that provides only a summary but
no details. However, the job trace log provides information about where to nd details
about each row of bad data in the audit le.
Parent topic: MongoDB [page 32]
38
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Related Information
MongoDB metadata [page 32]
MongoDB as a source [page 33]
MongoDB template documents [page 39]
Preview MongoDB document data [page 41]
Parallel Scan [page 42]
Reimport schemas [page 43]
Searching for MongoDB documents in the repository [page 44]
3.4.4MongoDB template documents
Use template documents as a target in one data ow or as a source in multiple data ows.
Template documents are useful in early application development when you design and test a project. After you
import data for the MongoDB datastore, Data Services stores the template documents in the object library.
Find template documents in the Datastore tab of the object library.
When you import a template document, the software converts it to a regular document. You can use the regular
document as a target or source in your data ow.
Note
Template documents are available in Data Services 4.2.7 and later. If you upgrade from a previous version,
open an existing MongoDB datastore and then click OK to close it. Data Services updates the datastore so
that you see the Template Documents node and any other template document related options.
Template documents are similar to template tables. For information about template tables, see the Data
Services User Guide and the Reference Guide.
Creating MongoDB template documents [page 40]
Create MongoDB template documents as targets in data ows, then use the target as a source in a
dierent data ow.
Convert a template document into a regular document [page 41]
SAP Data Services enables you to convert an imported template document into a regular document.
Parent topic: MongoDB [page 32]
Related Information
MongoDB metadata [page 32]
MongoDB as a source [page 33]
MongoDB as a target [page 36]
Preview MongoDB document data [page 41]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 39

Parallel Scan [page 42]
Reimport schemas [page 43]
Searching for MongoDB documents in the repository [page 44]
3.4.4.1 Creating MongoDB template documents
Create MongoDB template documents as targets in data ows, then use the target as a source in a dierent
data ow.
To use a MongoDB template as the target or source in a data ow, rst use the template as a target. To add a
MongoDB template as a target in a data ow, perform the following steps to create the target:
1. Click the template icon from the tool palette.
2. Click inside a data ow in the workspace.
The Create Template dialog box opens.
3. Enter a name for the template in Template name.
Note
Use the MongoDB collection namespace format: database.collection. Don’t exceed 120 bytes.
4. Select the related MongoDB datastore from the In datastore dropdown list.
5. Click OK.
6. To use the template document as a target in the data ow, connect the template document to the object
that comes before the template document.
Data Services automatically generates a schema based on the object directly before the template
document in the data ow.
Restriction
The eld <_id> is the default primary key of the MongoDB collection. Therefore, make sure that you
correctly congure the <_id> eld in the output schema of the object that comes directly before
the target template. If you don't include <_id> in the output schema, the following error appears
when you view the data: “An element named <_id> present in the XML data input does
not exist in the XML format used to set up this XML source in the data flow
<dataflow>. Validate your XML data.”
7. Click Save.
The template document icon in the data ow changes, and Data Services adds the template document to
the object library. Find the template document in the applicable database node under Templates.
Convert the template document into a regular document by selecting to import the template document in the
object library. Then you can use the template document as a source or a target document in other data ows.
Task overview: MongoDB template documents [page 39]
40
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Related Information
Convert a template document into a regular document [page 41]
3.4.4.2 Convert a template document into a regular
document
SAP Data Services enables you to convert an imported template document into a regular document.
Use one of the following methods to import a MongoDB template document:
• Open a data ow and select one or more template target documents in the workspace. Right-click, and
choose Import Document.
• Select one or more template documents in the Local Object Library, right-click, and choose Import
Document.
The icon changes and the document appears under Documents instead of Template Documents in the object
library.
Note
The Drop and re-create target conguration option is available only for template target documents.
Therefore it is not available after you convert the template target into a regular document.
Parent topic: MongoDB template documents [page 39]
Related Information
Creating MongoDB template documents [page 40]
3.4.5Preview MongoDB document data
Use the data preview feature in SAP Data Services Designer to view a sampling of data from a MongoDB
document.
Choose one of the following methods to preview MongoDB document data:
• Expand an applicable MongoDB datastore in the object library. Right-click the MongoDB document and
select View Data from the dropdown menu.
• Right-click the MongoDB document in a data ow and select View Data from the dropdown menu.
• Click the magnifying glass icon in the lower corner of either a MongoDB source or target object in a data
ow.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 41
Note
By default, Data Services displays a maximum of 100 rows. Change this number by setting the Rows To
Scan option in the applicable MongoDB datastore editor. Entering -1 displays all rows.
For more information about viewing data, see the Designer Guide.
Parent topic: MongoDB [page 32]
Related Information
MongoDB metadata [page 32]
MongoDB as a source [page 33]
MongoDB as a target [page 36]
MongoDB template documents [page 39]
Parallel Scan [page 42]
Reimport schemas [page 43]
Searching for MongoDB documents in the repository [page 44]
MongoDB adapter datastore conguration options
3.4.6Parallel Scan
SAP Data Services uses the MongoDB Parallel Scan process to improve performance while it generates
metadata for big data.
To generate metadata, Data Services rst scans all documents in the MongoDB collection. This
scanning can be time consuming. However, when Data Services uses the Parallel Scan command
parallelCollectionScan, it uses multiple parallel cursors to read all the documents in a collection. Parallel
Scan can increase performance.
Note
Parallel Scan works with MongoDB server version 2.6.0 and above.
For more information about the parallelCollectionScan command, consult your MongoDB
documentation.
For more information about Mongo adapter datastore conguration options, see the Supplement for Adapters.
Parent topic: MongoDB [page 32]
42
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Related Information
MongoDB metadata [page 32]
MongoDB as a source [page 33]
MongoDB as a target [page 36]
MongoDB template documents [page 39]
Preview MongoDB document data [page 41]
Reimport schemas [page 43]
Searching for MongoDB documents in the repository [page 44]
3.4.7Reimport schemas
When you reimport documents from your MongoDB datastore, SAP Data Services uses the current datastore
settings.
Reimport a single MongoDB document by right-clicking the document and selecting Reimport from the
dropdown menu.
To reimport all documents, right-click an applicable MongoDB datastore or right-click on the Documents node
and select Reimport All from the dropdown menu.
Note
When you enable Use Cache, Data Services uses the cached schema.
When you disable Use Cache, Data Services looks in the sample directory for a sample BSON le with the
same name. If there is a matching le, the software uses the schema from the BSON le. If there isn't a
matching BSON le in the sample directory, the software reimports the schema from the database.
Parent topic: MongoDB [page 32]
Related Information
MongoDB metadata [page 32]
MongoDB as a source [page 33]
MongoDB as a target [page 36]
MongoDB template documents [page 39]
Preview MongoDB document data [page 41]
Parallel Scan [page 42]
Searching for MongoDB documents in the repository [page 44]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 43
3.4.8Searching for MongoDB documents in the repository
SAP Data Services enables you to search for MongoDB documents in your repository from the object library.
1. Right-click in any tab in the object library and choose Search from the dropdown menu.
The Search dialog box opens.
2. Select the applicable MongoDB datastore name from the Look in dropdown menu.
The datastore is the one that contains the document for which you are searching.
3. Select Local Repository to search the entire repository.
4. Select Documents from the Object Type dropdown menu.
5. Enter the criteria for the search.
6. Click Search.
Data Services lists matching documents in the lower pane of the Search dialog box. A status line at the
bottom of the Search dialog box shows statistics such as total number of items found, amount of time to
search, and so on.
For more information about searching for objects, see the Objects section of the Designer Guide.
Task overview: MongoDB [page 32]
Related Information
MongoDB metadata [page 32]
MongoDB as a source [page 33]
MongoDB as a target [page 36]
MongoDB template documents [page 39]
Preview MongoDB document data [page 41]
Parallel Scan [page 42]
Reimport schemas [page 43]
3.5 Apache Impala
Create an ODBC datastore to connect to Apache Impala in Hadoop.
Before you create an Apache Impala datastore, download the Cloudera ODBC driver and create a data source
name (DSN). Use the datastore to connect to Hadoop and import Impala metadata. Use the metadata as a
source or target in a data ow.
Before you work with Apache Impala, be aware of the following limitations:
• SAP Data Services supports Impala 2.5 and later.
• SAP Data Services supports only Impala scalar data types. Data Services does not support complex types
such as ARRAY, STRUCT, or MAP.
44
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

For more information about ODBC datastores, see the Datastores section in the Designer Guide.
For descriptions of common datastore options, see the Designer Guide.
Download the Cloudera ODBC driver for Impala [page 45]
For Linux users. Before you create an Impala database datastore, connect to Apache Impala using the
Cloudera OBDC driver.
Creating an Apache Impala datastore [page 46]
To connect to your Hadoop les and access Impala data, create an ODBC datastore in SAP Data
Services Designer.
3.5.1Download the Cloudera ODBC driver for Impala
For Linux users. Before you create an Impala database datastore, connect to Apache Impala using the Cloudera
OBDC driver.
Perform the following high-level steps to download a Cloudera ODBC driver and create a data source name
(DSN). For more in-depth information, consult the Cloudera documentation.
1. Enable Impala Services on the Hadoop server.
2. Download and install the Cloudera ODBC driver (https://www.cloudera.com/downloads/connectors/
impala/odbc/2-5-26.html
):
Select the driver that is compatible with your platform. For information about the correct driver versions,
see the SAP Product Availability Matrix (PAM).
3. Start DSConnectionManager.sh.
Either open the le or run the following command:
cd $LINK_DIR/bin/
$ ./DSConnectionManager.sh
Example
The following shows prompts and values in DS Connection Manager that includes Kerberos and SSL:
The ODBC ini file is <path to the odbc.ini file>
There are available DSN names in the file:
[DSN name 1]
[DSN name 2]
Specify the DSN name from the list or add a new one:
<New DSN file name>
Specify the User Name:
<Hadoop user name>
Type database password:(no echo)
*Type the Hadoop password. Password does not appear after you type it for security.
Retype database password:(no echo)
Specify the Host Name:
<host name/IP address>
Specify the Port:'21050'
<port number>
Specify the Database:
default
Specify the Unix ODBC Lib Path:
*The Unix ODBC Lib Path is based on where you install the driver.
*For example, /build/unixODBC-2.3.2/lib.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 45

Specify the Driver:
/<path>/lib/64/libclouderaimpalaodbc64.so
Specify the Impala Auth Mech [0:noauth|1:kerberos|2:user|3:user-
password]:'0':
1
Specify the Kerberos Host FQDN:
<hosts fully qualified domain name>
Specify the Kerberos Realm:
<realm name>
Specify the Impala SSL Mode [0:disabled | 1:enabled]:'0'
1
Specify the Impala SSL Server Certificate File:
<path to certificate.pem>
Testing connection...
Successfully added database source.
Task overview: Apache Impala [page 44]
Related Information
Creating an Apache Impala datastore [page 46]
3.5.2Creating an Apache Impala datastore
To connect to your Hadoop les and access Impala data, create an ODBC datastore in SAP Data Services
Designer.
Before performing the following steps, enable Impala Services on your Hadoop server. Then download the
Cloudera driver for your platform.
Note
If you didn't create a DSN (data source name) in Windows ODBC Data Source application, you can create a
DSN in the following process.
To create an ODBC datastore for Apache Impala, perform the following steps in Designer:
1. Select
Tools New Datastore.
The datastore editor opens.
2. Choose Database from the Datastore Type dropdown list.
3. Choose ODBC from the Database Type dropdown list.
4. Select ODBC Admin.
The ODBC Data Source Administrator opens.
5. Open the System DSN tab and select the Cloudera driver that you downloaded from the System Data
Sources list.
6. Select Congure.
46
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services
The Cloudera ODBC Driver for Impala DSN Setup dialog box opens.
7. Enter the required information based on your system
8. Select Advanced Options.
9. Check Use SQL Unicode Types.
10. Close Advanced Options.
11. Optional: Enable Kerberos authentication by performing the following substeps:
a. Choose Kerberos from the Mechanism list.
b. Enter the name of the applicable realm in Realm.
A realm is a set of managed nodes that share the same Kerberos database.
c. Enter the fully qualied domain name (FQDN) of the Hive Server host in Host FQDN.
d. Enter the service principal name for the Hive server in Service Name.
e. Enable the Canonicalize Principal FQDN option.
This option canonicalizes the host FQDN in the server principal name.
12. Optional: To enable Secure Sockets Layer (SSL) protocol, perform the following substeps:
a. Choose No Authentication (SSL) from the Mechanism list.
b. Select Advanced Options.
c. Enter or browse to the Cloudera certicate le in Trusted Certicates.
The default path to the Impala certificate.pem le automatically populates.
d. Close Advanced Options.
13. Close the Cloudera ODBC Driver for Impala DSN Setup dialog box and the ODBC Data Source
Administrator.
14. Select the Cloudera DSN that you created from the Data Source Name list.
The DSN appears in the dropdown list only after you've created it.
15. Select Advanced and complete the advanced options as necessary.
a. Optional: Set the Code page option to utf-8 in the Locale group to process multibyte data in Impala
tables.
b. Optional: In the ODBC Date Function Support group, set the Week option to No.
If you don’t set the Week option to No, the result of the Data Services built-in function
week_in_year() may be incorrect.
Task overview: Apache Impala [page 44]
Related Information
Download the Cloudera ODBC driver for Impala [page 45]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 47
3.6 PostgreSQL
To use your PostgreSQL tables as sources and targets in SAP Data Services, create a PostgreSQL datastore
and import your tables and other metadata.
Prerequisites
Before you congure the PostgreSQL datastore, perform the following prerequisites:
• Download and install the latest supported PostgreSQL Server version from the ocial PostgreSQL Web
site at https://www.postgresql.org/download/
. Check the Product Availability Matrix (PAM) on the
SAP Support Portal to ensure that you have the supported PostgreSQL version for your version of Data
Services.
• Obtain the ODBC driver that is compatible with your version of PostgreSQL. To avoid potential
processing problems, download the ODBC driver from the ocial PostgreSQL Web site at https://
www.postgresql.org/ftp/odbc/versions/ . Find option descritions for conguring the ODBC driver at
https://odbc.postgresql.org/docs/cong.html .
DSN or DSN-less connections
Create a PostgreSQL datastore using either a DSN or DSN-less connection.
When you create a DSN-less connection, you can optionally protect your connection with SSL/TLS and X509
single sign-on authentication when you congure the datastore.
Bulk loading
Congure the PostgreSQL datastore for bulk loading to the target PostgreSQL database. Before you can
congure the bulk loading options, obtain the PSQL tool from the ocial PostgreSQL website. In addition
to setting the bulk loader directory and the location for the PSQL tool in the datastore, complete the Bulk
Loader Options tab in the target editor. For complete information about the bulk loading in PostgreSQL and the
options, see the Performance Optimization Guide.
Note
Data Services supports bulk loading for PostgreSQL DSN-less connections only.
48
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Pushdown functions
Data Services supports the basic pushdown functions for PostgreSQL. For a list of pushdown functions that
Data Services supports for PostgreSQL, see SAP Note 2212730 .
UTF-8 encoding
To process PostgreSQL tables as sources in data ows, Data Services requires that all data in PostgreSQL
tables use UTF-8 encoding. Additionally, Data Services outputs data to PostgreSQL target tables using UTF 8
encoding.
Conversion to or from internal data types
Data Services converts PostgreSQL data types to data types that it can process. After processing, Data
Services outputs data and converts the data types back to the corresponding PostgreSQL data types.
Datastore options for PostgreSQL [page 49]
Complete options in the datastore editor to set the datastore type, database version, database access
information, and DSN information if applicable.
Congure the PostgreSQL ODBC driver [page 53]
Congure the PostgreSQL ODBC driver for Windows or Linux to update the conguration le with the
applicable driver information.
Conguring ODBC driver for SSL/TLS X509 PostgresSQL [page 54]
For Linux, congure the ODBC driver for SSL/TLS X509 authentication for connecting to your
PostgresSQL databases.
Import PostgreSQL metadata [page 55]
Use the PostgreSQL database datastore to access the schemas and tables in the dened database.
PostgreSQL source, target, and template tables [page 56]
Use PostgreSQL tables as sources and targets in data ows and use PostgreSQL table schemas for
template tables.
PostgreSQL data type conversions [page 57]
When you import metadata from a PostgreSQL table into the repository, SAP Data Services converts
PostgreSQL data types to Data Services native data types for processing.
3.6.1Datastore options for PostgreSQL
Complete options in the datastore editor to set the datastore type, database version, database access
information, and DSN information if applicable.
The following table contains descriptions for the rst set of options, which dene the datastore type (database)
and the PostgreSQL version information.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 49
PostgreSQL datastore option descriptions
Option Value
Datastore Type Select Database.
Database Type Select PostgreSQL.
Database Version Select a version.
Check the Product Availability Matrix (PAM)
to ensure
that you have the supported PostgreSQL version for your
version of Data Services.
The following table describes the specic options to complete when you create a DSN connection.
PostgreSQL DSN option descriptions
Option
Description
Data Source Name
Species the name of the DSN you create in the ODBC Data
Source Administrator.
Ensure that you create the DSN so that it appears in the
dropdown list.
User Name
Species the user name to access the data source dened in
the DSN.
Password Species the password related to the User Name value.
To create a server-name (DSN-less) connection for the datastore, complete the database-specic options
described in the following table.
PostgreSQL database option descriptions for DSN-less connection
Option
Description
Database server name
Species the database server address. Enter localhost
or an IP address.
Database name Species the database name to which this datastore con-
nects.
Port Species the port number that this datastore uses to access
the database.
User name Species the name of the user authorized to access the
database.
Password Species the password related to the specied User name.
Enable Automatic Data Transfer Species that any data ow that uses the tables imported
with this datastore can use the Data_Transfer transform.
Data_Transfer uses transfer tables to push down certain op-
erations to the database server for more ecient process-
ing.
50 PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Option Description
Use SSL encryption Species to use SSL/TLS encryption for the datastore con-
nection to the database. SSL/TLS encryption is applicable
only for DSN-less connections.
• Yes: Creates the datastore with SSL/TLS encryption.
When you select Yes, you must also complete the op-
tions in the Encryption Parameters dialog.
• No: Creates the datastore without SSL/TLS encryption.
You can optionally add X509 authentication by selecting
X509 in the Authentication Method option.
Encryption parameters
Opens the Encryption Parameters dialog box.
To open the dialog, double-click in the empty cell.
Enabled only when you select Yes for Use SSL encryption.
Authentication Method Species how to authenticate SSL encryption. Options in-
clude the following:
• Basic: Species to authenticate using the user name
and password. When you select Basic, also complete
the User Name and Password options. Basic is the de-
fault setting.
• X509: Species to authenticate using X509 Single Sign-
On Authentication. When you select X509, also com-
plete the User Name option and complete the options in
the Encryption Parameters dialog box.
Note
The user name must be the same as the user name
mapped to the x509 certicate.
Bulk loader directory
Species the directory where Data Services stores the les
related to bulk loading, such as log le, error le, and tempo-
rary les.
Click the down arrow at the end of the eld and select
<Browse> or select an existing global variable that you cre-
ated for this location.
If you leave this eld blank, Data Services writes the les to
%DS_COMMON_DIR%/log/bulkloader.
Note
Bulk loading in PostgreSQL is applicable for DSN-less
connections only.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 51

Option Description
PSQL full path
Species the full path to the location of the PSQL tool.
The PSQL tool is required for PostgreSQL bulk loading. Ob-
tain the PSQL tool from the ocial PostgreSQL website.
For convenience, create a global variable for this value before
you congure the datastore.
Click the down arrow at the end of the eld and select
<Browse> or select the global variable.
Note
Bulk loading in PostgreSQL is applicable for DSN-less
connections only.
The following options are in the Encryption Parameters dialog box when you select Yes for Use SSL encryption.
SSL Mode Species whether the connection is veried by the server
and in what priority.
• Prefer: First tries to connect PostgreSQL with SSL; if
that fails, tries to connect without SSL. Prefer is the
default setting.
• Require: Connects only using SSL. If a root CA le
is present, veries the certicate in the same way as
Verify-CA.
• Verify-CA: Connects only using SSL, and veries that
the server certicate is issued by a trusted certicate
authority (CA).
• Verify-Full: Connects only using SSL, veries that the
server certicate is issued by a trusted CA, and veries
that the requested server host name matches the host
name in the certicate.
Verify Client Certicate
When selected, species to have the client verify the server
certicate. Your selection for SSL Mode determines the
method:
• If you select Verify-CA for SSL Mode, the server certi-
cate is veried by the client with the CA.
• If you select Verify-Full for SSL Mode, the client with the
CA veries the following:
• The server certicate.
• The CN name in the server certicate matches the
hostname of the database to which you are con-
necting.
When you select Verify Client Certicate, you must also
complete Certicate, Certicate Key, and Certicate Key
Password.
52 PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Option Description
Certicate Browse to and select the client certicate le. If you've cre-
ated a substitution parameter for this le, select the substi-
tution parameter from the list.
Certicate Key Browse to and select the client private key le. If you've
created a substitution parameter for this le, select the sub-
stitution parameter from the list.
Certicate Key Password Species the password used to encrypt the client key le.
SSL CA File Browse to and select the SSL CA certicate le to verify the
server. If you've created a substitution parameter for this le,
select the substitution parameter from the list.
Note
This option is applicable only when you set SSL Mode to
Verify-Full.
For a list of properties required for each database type, see the Administrator Guide.
For information about bulk loading with PostgreSQL, see the Performance Optimization Guide.
Parent topic: PostgreSQL [page 48]
Related Information
Congure the PostgreSQL ODBC driver [page 53]
Conguring ODBC driver for SSL/TLS X509 PostgresSQL [page 54]
Import PostgreSQL metadata [page 55]
PostgreSQL source, target, and template tables [page 56]
PostgreSQL data type conversions [page 57]
3.6.2Congure the PostgreSQL ODBC driver
Congure the PostgreSQL ODBC driver for Windows or Linux to update the conguration le with the
applicable driver information.
Download and install the PostgreSQL client ODBC driver from the PostgresSQL Website at https://
www.postgresql.org/ftp/odbc/versions/ . For description of conguration options, see the PostgresSQL
Website at https://odbc.postgresql.org/docs/cong.html .
For Windows, use the ODBC Drivers Selector to verify the ODBC driver is installed. For Linux, congure the
ODBC driver using the SAP Data Services Connection Manager.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 53

For DSN-less connections, you can enable SSL/TLS with optional X509 authentication. Ensure that you
complete the necessary steps in your PostgreSQL database before you congure the datastore for SSL/TLS
with optional X509 authentication in SAP Data Services. See your PostgreSQL documentation for details.
Parent topic: PostgreSQL [page 48]
Related Information
Datastore options for PostgreSQL [page 49]
Conguring ODBC driver for SSL/TLS X509 PostgresSQL [page 54]
Import PostgreSQL metadata [page 55]
PostgreSQL source, target, and template tables [page 56]
PostgreSQL data type conversions [page 57]
3.6.3Conguring ODBC driver for SSL/TLS X509
PostgresSQL
For Linux, congure the ODBC driver for SSL/TLS X509 authentication for connecting to your PostgresSQL
databases.
Before you perform the following steps, download and install the PostgreSQL client ODBC driver from the
PostgresSQL Website at https://www.postgresql.org/ftp/odbc/versions/ . For description of conguration
options, see the PostgresSQL Website at https://odbc.postgresql.org/docs/cong.html .
For complete instructions to use the Connection Manager utility, and to implement the graphical user interface
for the utility, see the Server Management section of the Administrator Guide.
1. Open the connection manager using the following command:
$ cd $LINK_DIR/bin
$ source al_env.sh
$ DSConnectionManager.sh
Replace $LINK_DIR with the SAP Data Services installation directory.
2. Complete the options as shown in the following example:
Example
Values shown as <value> and in bold indicate where you enter your own values or values related to
your system.
********************************
Configuration for PostgreSQL
********************************
The ODBC inst file is <.../odbcinst.ini>
Specify the Driver Version:<'version>'
Specify the Driver Name:
<driver_name>
54
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Specify the Driver:
<.../psqlodbcw.so
>
Specify the Host Name:
<host_name>
Specify the Port:<'port>'
Specify the Database:
<database_name>
Specify the Unix ODBC Lib Path:'<.../drivers/unixODBC-2.3.2/lib>'
Specify the SSL Mode(0:none|1:prefer|2:require|3:verify-ca|4:verify-
full):'0'
3
Specify the SSL Client Certificate file:
</.../postgres.crt
>
Specify the SSL Client Key file:
</.../drivers/ssl/pgs/postgres.key
>
Specify the SSL Client Key file password:
Specify the SSL CA Certificate:
</.../drivers/ssl/pgs/root.crt>
Specify the Authentication Mode(1:Basic|2:X509):'1'
2
Specify the User Name:
<user_name>
Testing connection...
Successfully added driver.
Press Enter to go back to the Main Menu.
------------------Main Menu-Configure Drivers------------------
Drivers:
Index Database Type Version State Name
------ ------ ------ ------ ------
1: SQL Anywhere 17 not installed DS Bundled
SQL Anywhere
2: PostgreSQL 14.x installed PGS14
Task overview: PostgreSQL [page 48]
Related Information
Datastore options for PostgreSQL [page 49]
Congure the PostgreSQL ODBC driver [page 53]
Import PostgreSQL metadata [page 55]
PostgreSQL source, target, and template tables [page 56]
PostgreSQL data type conversions [page 57]
3.6.4Import PostgreSQL metadata
Use the PostgreSQL database datastore to access the schemas and tables in the dened database.
Open the datastore and view the metadata available to download. For PostgreSQL, download schemas and the
related tables. Each table resides under a specic schema. For example, each schema contains tables that use
the schema. A table name appears as <dbname>.<schema_name>.<table_name>.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 55
Import metadata by browsing, by name, or by searching.
For more information about viewing metadata, see the Datastore metadata section of the Designer Guide.
For more information about the imported metadata from database datastores, see the Datastores section of
the Designer Guide.
Parent topic: PostgreSQL [page 48]
Related Information
Datastore options for PostgreSQL [page 49]
Congure the PostgreSQL ODBC driver [page 53]
Conguring ODBC driver for SSL/TLS X509 PostgresSQL [page 54]
PostgreSQL source, target, and template tables [page 56]
PostgreSQL data type conversions [page 57]
3.6.5PostgreSQL source, target, and template tables
Use PostgreSQL tables as sources and targets in data ows and use PostgreSQL table schemas for template
tables.
Drag the applicable PostgreSQL table onto your workspace and connect it to a data ow as a source or target.
Also, use a template table as a target in a data ow and save it to use as a future source in a dierent data ow.
See the Designer Guide to learn about using template tables. Additionally, see the Reference Guide for
descriptions of options to complete for source, target, and template tables.
Parent topic: PostgreSQL [page 48]
Related Information
Datastore options for PostgreSQL [page 49]
Congure the PostgreSQL ODBC driver [page 53]
Conguring ODBC driver for SSL/TLS X509 PostgresSQL [page 54]
Import PostgreSQL metadata [page 55]
PostgreSQL data type conversions [page 57]
56
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

3.6.6PostgreSQL data type conversions
When you import metadata from a PostgreSQL table into the repository, SAP Data Services converts
PostgreSQL data types to Data Services native data types for processing.
After processing, Data Services converts data types back to PostgreSQL data types when it outputs the
generated data to the target.
The following table contains PostgreSQL data types and the corresponding Data Services data types.
Data type conversion for PostgreSQL
PostgreSQL data type
Converts to or from Data Services
data type Notes
Boolean/Integer/Smallint Int
Serial/Samllserial/Serial4/OID Int
Bigint/BigSerial/Serial8 Decimal(19,0)
Float(1)-Float(24), Real real
Float(25)-Float(53), Double precision double
Money double
Numeric(precision, scale) Decimal(precision, scale)
Numeric/Decimal Decimal(28,6)
Bytea Blob
Char(n) Fixedchar(n)
Text/varchar(n) Varchar(n)
DATE Date
TIMESTAMP Datetime
TIMESTAMPTZ Varchar(127)
TIMETZ Varchar(127)
INTERVAL Varchar(127)
If Data Services encounters a column that has an unsupported data type, it does not import the column.
However, you can congure Data Services to import unsupported data types by checking the Import
unsupported data types as VARCHAR of size option in the datastore editor dialog box.
Note
When you import tables that have specic PostgreSQL native data types, Data Services saves the data type
as varchar or integer, and includes an attribute setting for Native Type. The following table contains the
column data type in which Data Services saves the PostgreSQL native data type, and the corresponding
attribute.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 57
Data Services saves PostgreSQL native data types
PostgreSQL column native data type Data Services saves as data type Data Services attribute
json
jsonb
xml
uuid
Varchar
Native Type = JSON
Native Type = JSONB
Native Type = XML
Native Type = UUID
bool
text
bigint
Integer
Native Type = BOOL
Native Type = TEXT
Native Type = INT8
Parent topic: PostgreSQL [page 48]
Related Information
Datastore options for PostgreSQL [page 49]
Congure the PostgreSQL ODBC driver [page 53]
Conguring ODBC driver for SSL/TLS X509 PostgresSQL [page 54]
Import PostgreSQL metadata [page 55]
PostgreSQL source, target, and template tables [page 56]
3.7 SAP HANA
Process your SAP HANA data in SAP Data Services by creating an SAP HANA database datastore.
Import SAP HANA metadata using a database datastore. Use the table metadata as sources and targets in
data ows. Some of the benets of using SAP HANA in Data Services include the following:
• Protect your SAP HANA data during network transmission using SSL/TLS protocol and X.509
authentication with Cryptographic libraries.
• Create stored procedures and enable bulk loading for faster reading and loading.
• Load spatial and complex spatial data from Oracle to SAP HANA.
Note
Beginning with SAP HANA 2.0 SP1, access databases only through a multitenant database container
(MDC). If you use a version of SAP HANA that is earlier than 2.0 SP1, access only a single database.
Cryptographic libraries and global.ini settings [page 59]
When you create an SAP HANA database datastore with SSL/TLS encryption or X.509 authentication,
congure both server side and client side for the applicable authentication.
X.509 authentication [page 61]
58
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

X.509 authentication is a more secure method of accessing SAP HANA than user name and password
authentication.
JWT authentication [page 62]
SAP Data Services supports the JSON web token (JWT) single sign-on user authentication mechanism
for SAP HANA on-premise and cloud servers.
Bulk loading in SAP HANA [page 63]
SAP Data Services improves bulk loading for SAP HANA by using a staging mechanism to load data to
the target table.
Creating stored procedures in SAP HANA [page 65]
SAP Data Services supports SAP HANA stored procedures with zero, one, or more output parameters.
SAP HANA database datastores [page 66]
To access SAP HANA data for SAP Data Services processes, congure an SAP HANA database
datastore with either a data source name (DSN) or a server name (DSN-less) connection.
Conguring DSN for SAP HANA on Windows [page 72]
To use a DSN connection for an SAP HANA datastore, congure a DSN connection for Windows using
the ODBC Data Source Administrator.
Conguring DSN for SAP HANA on Unix [page 74]
Congure a DSN connection for an SAP HANA database datastore for Unix using the SAP Data
Services Connection Manager.
Datatype conversion for SAP HANA [page 76]
SAP Data Services performs data type conversions when it imports metadata from SAP HANA sources
or targets into the repository and when it loads data into an external SAP HANA table or le.
Using spatial data with SAP HANA [page 78]
SAP Data Services supports spatial data such as point, line, polygon, collection, for specic databases.
3.7.1Cryptographic libraries and global.ini settings
When you create an SAP HANA database datastore with SSL/TLS encryption or X.509 authentication,
congure both server side and client side for the applicable authentication.
On the server side, the process of conguring the ODBC driver, SSL/TLS, and/or X.509 authentication
automatically sets the applicable settings in the communications section of the global.ini le.
SAP HANA uses the SAP CommonCrypto library for both SSL/TLS encryption and X.509 authentication. The
SAP HANA server installer installs the CommonCryptoLib (libsapcrypto.sar) to $DIR_EXECUTABLE by default.
Note
SAP CommonCrypto library was formerly known as SAPCrypto library.
Note
Support for OpenSSL in SAP HANA is deprecated. If you are using OpenSSL, we recommend that you
migrate to CommonCryptoLib. For more information, see 2093286
Obtaining the SAP CommonCryptoLib le in Windows and Unix [page 60]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 59

The SAP CommonCryptoLib les are required for using SSL/TLS encryption and X.509 authentication
in your SAP HANA database datastores.
Parent topic: SAP HANA [page 58]
Related Information
X.509 authentication [page 61]
JWT authentication [page 62]
Bulk loading in SAP HANA [page 63]
Creating stored procedures in SAP HANA [page 65]
SAP HANA database datastores [page 66]
Conguring DSN for SAP HANA on Windows [page 72]
Conguring DSN for SAP HANA on Unix [page 74]
Datatype conversion for SAP HANA [page 76]
Using spatial data with SAP HANA [page 78]
3.7.1.1 Obtaining the SAP CommonCryptoLib le in
Windows and Unix
The SAP CommonCryptoLib les are required for using SSL/TLS encryption and X.509 authentication in your
SAP HANA database datastores.
If you use the SAP HANA ODBC driver version 2.9 or higher, you don't have to perform the following steps to
obtain the SAP CommonCrypto library, because it's bundled with the driver.
To obtain the SAP CommonCryptoLib le, perform the following steps based on your platform:
1. For Windows:
a. Create a local folder to store the CommonCryptoLib les.
b. Download and install the applicable version of SAPCAR
from the SAP download center.
Use SAPCAR to extract the SAP CommonCryptoLib libraries.
c. Obtain the SAP CommonCryptoLib Library le from the SAP download center.
d. Use SAPCar to extract the library les from libsapcrypto.sar to the local folder that you created to
store the les.
e. Create a system variable in Windows named $SECUDIR and point to the local folder that you created
for the CommonCryptoLib library les.
The process to create a system variable on Windows varies based on your Windows version.
Example
To create a system variable for Windows 10 Enterprise, access Control Panel as an administrator
and open Systems. Search for System Variables and select Edit System Variables.
60
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services
f. Append %SECUDIR% to the PATH variable in Environment Variables.
g. Restart Windows.
2. For Unix:
a. Create a local folder to store the CommonCryptoLib les.
b. Obtain the SAP CommonCryptoLib Library libsapcrypto.sar le from the Software Center
.
c. Use SAPCar to extract the library les from libsapcrypto.sar to the local folder that you created to
store the les.
d. Create a system variable named SECUDIR and point to the local folder that you created to store the
les.
export SECUDIR=/PATH/<LOCAL_FOLDER>
e. Append $SECUDIR to PATH.
export PATH=$SECUDIR:$PATH
f. Restart the Job Server.
Task overview: Cryptographic libraries and global.ini settings [page 59]
3.7.2X.509 authentication
X.509 authentication is a more secure method of accessing SAP HANA than user name and password
authentication.
Include X.509 authentication when you congure an SAP HANA datastore. When you use X.509
authentication, consider the following information:
• Use with or without SSL/TLS protocol.
• Applicable for both DSN and server named (DSN-less) connections.
• Uses the same Cryptographic libraries and global.ini settings as the SSL/TLS protocol.
• Requires an X.509 key store le, which contains the following:
• The X.509 client certicate.
• The SSL server certicate, only if you select to use SSL/TLS encryption and you select to validate the
server certicate in SAP Data Services.
Note
Support for X.509 authentication begins in SAP Data Services version 4.2 SP14 (14.2.14.16) and is
applicable for SAP HANA Server on premise 2.0 SP05 revision 56 and above, and SAP HANA Cloud. For
SAP HANA client, X.509 is applicable for SAP HANA ODBC client 2.7 and above.
Create and congure the server and client certicate les before you include X.509 authentication for
connecting to your SAP HANA data. For details, see the SAP Knowledge Base article 3126555 .
Parent topic: SAP HANA [page 58]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 61
Related Information
Cryptographic libraries and global.ini settings [page 59]
JWT authentication [page 62]
Bulk loading in SAP HANA [page 63]
Creating stored procedures in SAP HANA [page 65]
SAP HANA database datastores [page 66]
Conguring DSN for SAP HANA on Windows [page 72]
Conguring DSN for SAP HANA on Unix [page 74]
Datatype conversion for SAP HANA [page 76]
Using spatial data with SAP HANA [page 78]
3.7.3JWT authentication
SAP Data Services supports the JSON web token (JWT) single sign-on user authentication mechanism for SAP
HANA on-premise and cloud servers.
To use JWT user authentication for a SAP HANA datastore and a MDS/VDS request, edit the HANA datastore
and leave the User Name eld empty and enter an encoded JWT into the Password eld.
For information about obtaining a JWT for a HANA user on the HANA on-premise server, see Single Sign-On
Using JSON Web Tokens in SAP HANA Security Guide for SAP HANA Platform.
For information about obtaining a JWT for a HANA user on the HANA Cloud server, contact your Cloud server
administrator.
Parent topic: SAP HANA [page 58]
Related Information
Cryptographic libraries and global.ini settings [page 59]
X.509 authentication [page 61]
Bulk loading in SAP HANA [page 63]
Creating stored procedures in SAP HANA [page 65]
SAP HANA database datastores [page 66]
Conguring DSN for SAP HANA on Windows [page 72]
Conguring DSN for SAP HANA on Unix [page 74]
Datatype conversion for SAP HANA [page 76]
Using spatial data with SAP HANA [page 78]
62
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services
3.7.4Bulk loading in SAP HANA
SAP Data Services improves bulk loading for SAP HANA by using a staging mechanism to load data to the
target table.
When Data Services uses changed data capture (CDC) or auto correct load, it uses a temporary staging table
to load the target table. Data Services loads the data to the staging table and applies the operation codes
INSERT, UPDATE, and DELETE to update the target table. With the Bulk load option selected in the target table
editor, any one of the following conditions triggers the staging mechanism:
• The data ow contains a Map CDC Operation transform.
• The data ow contains a Map Operation transform that outputs UPDATE or DELETE rows.
• The data ow contains a Table Comparison transform.
• The Auto correct load option in the target table editor is set to Yes.
If none of these conditions are met, the input data contains only INSERT rows. Therefore Data Services
performs only a bulk insert operation, which does not require a staging table or the need to execute any
additional SQL.
By default, Data Services automatically detects the SAP HANA target table type. Then Data Services updates
the table based on the table type for optimal performance.
The bulk loader for SAP HANA is scalable and supports UPDATE and DELETE operations. Therefore, the
following options in the target table editor are also available for bulk loading:
• Use input keys: Uses the primary keys from the input table when the target table does not contain a
primary key.
• Auto correct load: If a matching row to the source table does not exist in the target table, Data Services
inserts the row in the target. If a matching row exists, Data Services updates the row based on other update
settings in the target editor.
Find these options in the target editor under Update Control.
For more information about SAP HANA bulk loading and option descriptions, see the Data Services
Supplement for Big Data.
SAP HANA target table options [page 64]
When you use SAP HANA tables as targets in a data ow, congure options in the target editor.
Parent topic: SAP HANA [page 58]
Related Information
Cryptographic libraries and global.ini settings [page 59]
X.509 authentication [page 61]
JWT authentication [page 62]
Creating stored procedures in SAP HANA [page 65]
SAP HANA database datastores [page 66]
Conguring DSN for SAP HANA on Windows [page 72]
Conguring DSN for SAP HANA on Unix [page 74]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 63

Datatype conversion for SAP HANA [page 76]
Using spatial data with SAP HANA [page 78]
SAP HANA target table options [page 64]
3.7.4.1 SAP HANA target table options
When you use SAP HANA tables as targets in a data ow, congure options in the target editor.
The following tables describe options in the target editor that are applicable to SAP HANA. For descriptions of
the common options, see the Reference Guide.
Options
Option
Description
Table type Species the table type when you use SAP HANA template table as target.
• Column Store: Creates tables organized by column. Column Store is the default
setting.
Note
Data Services does not support blob, dbblob, and clob data types for column
store table types.
• Row Store: Creates tables organized by row.
Bulk loading
Option
Description
Bulk load Species whether Data Services uses bulk loading to load data to the target.
• Selected: Uses bulk loading to load data to the target.
• Not selected: Does not use bulk loading to load data to the target.
Mode Species the mode that Data Services uses for loading data to the target table:
• Append: Adds new records to the table. Append is the default setting.
• Truncate: Deletes all existing records in the table and then adds new records.
Commit size Species the maximum number of rows that Data Services loads to the staging and target
tables before it saves the data (commits).
• default: Uses a default commit size based on the target table type.
• Column Store: Default commit size is 10,000
• Row Store: Default commit size is 1,000
• Enter a value that is greater than 1.
64 PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Option Description
Update method Species how Data Services applies the input rows to the target table.
• default: Uses an update method based on the target table type:
• Column Store: Uses UPDATE to apply the input rows.
• Row Store: Uses DELETE-INSERT to apply the input rows.
• UPDATE: Issues an UPDATE to the target table.
• DELETE-INSERT: Issues a DELETE to the target table for data that matches the old
data in the staging table. Issues an INSERT with the new data.
Note
Do not use DELETE-INSERT if the update rows contain data for only some of the
columns in the target table. If you use DELETE-INSERT, Data Services replaces
missing data with NULLs.
Parent topic: Bulk loading in SAP HANA [page 63]
3.7.5Creating stored procedures in SAP HANA
SAP Data Services supports SAP HANA stored procedures with zero, one, or more output parameters.
Data Services supports scalar data types for input and output parameters. Data Services does not support
table data types. If you try to import a procedure with table data type, the software issues an error. Data
Services does not support data types such as binary, blob, clob, nclob, or varbinary for SAP HANA procedure
parameters.
Procedures can be called from a script or from a Query transform as a new function call.
Example
Syntax
The SAP HANA syntax for the stored procedure:
CREATE PROCEDURE GET_EMP_REC (IN EMP_NUMBER INTEGER, OUT EMP_NAME
VARCHAR(20), OUT EMP_HIREDATE DATE) AS
BEGIN
SELECT ENAME, HIREDATE
INTO EMP_NAME, EMP_HIREDATE
FROM EMPLOYEE
WHERE EMPNO = EMP_NUMBER;
END;
Limitations
SAP HANA provides limited support of user-dened functions that can return one or several scalar values.
These user-dened functions are usually written in L. If you use user-dened functions, limit them to the
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 65

projection list and the GROUP BY clause of an aggregation query on top of an OLAP cube or a column table.
These functions are not supported by Data Services.
SAP HANA procedures cannot be called from a WHERE clause.
For more information about creating stored procedurees in a database, see the Functions and Procedures
section in the Designer Guide.
Parent topic: SAP HANA [page 58]
Related Information
Cryptographic libraries and global.ini settings [page 59]
X.509 authentication [page 61]
JWT authentication [page 62]
Bulk loading in SAP HANA [page 63]
SAP HANA database datastores [page 66]
Conguring DSN for SAP HANA on Windows [page 72]
Conguring DSN for SAP HANA on Unix [page 74]
Datatype conversion for SAP HANA [page 76]
Using spatial data with SAP HANA [page 78]
3.7.6SAP HANA database datastores
To access SAP HANA data for SAP Data Services processes, congure an SAP HANA database datastore with
either a data source name (DSN) or a server name (DSN-less) connection.
You can optionally include secure socket layer (SSL) or transport layer security (TLS) for secure transfer of
data over a network, and you can use X.509 authentication instead of user name and password authentication.
Note
Support for SSL/TLS with a DSN connection begins in SAP Data Services version 4.2 SP7 (14.2.7.0).
Support for SSL/TLS with a DSN-less connection begins in SAP Data Services version 4.2 SP12 (14.2.12.0).
Note
Support for X.509 authentication is applicable for SAP HANA Server on premise 2.0 SP05 revision 56 and
above and SAP HANA Cloud. For SAP HANA client, X.509 is applicable for SAP HANA ODBC client 2.7 and
above.
When you create an SAP HANA datastore, and use SAP HANA data in data ows, Data Services requires
the SAP HANA ODBC driver. The following table lists the additional requirements for including additional
authentications.
66
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Authentication Requirements
SSL/TLS
SAP CommonCrypto library
SAP HANA SSL/TLS certicate and key les
X.509
SAP CommonCrypto library
X.509 KeyStore le, which contains the following certi-
cates:
• X.509 client certicate.
• SSL/TLS server certicate, only when you use SSL en-
cryption and validate the server certicate in Data Serv-
ices.
For more information about SAP HANA, SSL/TLS, SAP CommonCrypto library, and settings for secure
external connections in the global.ini le, see the “SAP HANA Network and Communication Security”
section of the SAP HANA Security Guide.
Note
Enabling SSL/TLS encryption slows job performance.
SAP HANA datastore prerequisites [page 68]
Before you congure an SAP HANA datastore, perform prerequisite tasks, such as conguring the
ODBC driver.
SAP HANA datastore option descriptions [page 69]
In addition to the common database datastore options, SAP Data Services requires that you set
options specic to SAP HANA, SSL/TLS, and X.509 authentication.
Parent topic: SAP HANA [page 58]
Related Information
Cryptographic libraries and global.ini settings [page 59]
X.509 authentication [page 61]
JWT authentication [page 62]
Bulk loading in SAP HANA [page 63]
Creating stored procedures in SAP HANA [page 65]
Conguring DSN for SAP HANA on Windows [page 72]
Conguring DSN for SAP HANA on Unix [page 74]
Datatype conversion for SAP HANA [page 76]
Using spatial data with SAP HANA [page 78]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 67

3.7.6.1 SAP HANA datastore prerequisites
Before you congure an SAP HANA datastore, perform prerequisite tasks, such as conguring the ODBC
driver.
Perform the following prerequisite tasks before you create the SAP HANA datastore:
• Download, install, and congure the SAP HANA ODBC driver.
• For Windows, congure the driver using the ODBC Drivers Selector utility.
• For UNIX, congure the driver using the ODBC Data Source Administrator.
Note
If you plan to include SSL/TLS or X.509 authentication in the datastore, consider using the SAP HANA
ODBC driver version 2.9 or higher. Version 2.9 or higher is bundled with the SAP CommonCrypto
library, which is required for SSL/TLS and X.509.
• If you use a data source name (DSN), create a DSN connection using the ODBC Data Source Administrator
(Windows) or the SAP Data Services Connection Manager (Unix).
• If you include SSL/TLS encryption:
• Download the SAP CommonCrypto library and set the PATH environment variable as instructed in
Obtaining the SAP CommonCryptoLib le in Windows and Unix [page 60].
Note
If you use the SAP HANA ODBC driver version 2.9 or higher, set the following environment
variables:
• Windows: Set the SECUDIR and PATH environment variables to HANA Client directory with
Commoncrypto library on Windows system.
• Unix: Set the SECUDIR and LD_LIBRARY_PATH environment variables to HANA Client
directory with Commoncrypto library on Unix system.
• Set SSL/TLS options in the datastore editor (Windows) or the Data Services Connection Manager
(Unix).
• If you use X.509 authentication:
• Download the SAP CommonCrypto library and set the PATH environment variable as instructed in
Obtaining the SAP CommonCryptoLib le in Windows and Unix [page 60].
Note
If you've downloaded the SAP CommonCrypto library and set the PATH environment variable for
SSL/TLS, you don't have to repeat it for X.509 authentication.
Note
If you use the SAP HANA ODBC driver version 2.9 or higher, set the following environment
variables:
• Windows: Set the SECUDIR and PATH environment variables to HANA Client directory with
Commoncrypto library on Windows system.
• Unix: Set the SECUDIR and LD_LIBRARY_PATH environment variables to HANA Client
directory with Commoncrypto library on Unix system.
68
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

• Congure the X.509 key store le. For details, see the SAP Knowledge Base article 3126555 .
• Set X.509 options in the datastore editor (Windows) or the Data Services Connection Manager (Unix).
Note
Support for X.509 authentication is applicable for SAP HANA Server on premise 2.0 SP05 revision 56
and above and SAP HANA Cloud. For SAP HANA client, X.509 is applicable for SAP HANA ODBC client
2.7 and above.
Parent topic: SAP HANA database datastores [page 66]
Related Information
SAP HANA datastore option descriptions [page 69]
3.7.6.2 SAP HANA datastore option descriptions
In addition to the common database datastore options, SAP Data Services requires that you set options
specic to SAP HANA, SSL/TLS, and X.509 authentication.
For descriptions of common database datastore options, and for steps to create a database datastore, see the
Datastores section of the Designer Guide.
The following table contains the SAP HANA-specic options in the datastore editor, including DSN and DSN-
less settings.
Option Value
Use Data Source Name (DSN) Species whether to use a DSN (data source name) connec-
tion.
• Select to create a datastore using a DSN.
• Don't select to create a datastore using a server-name
(DSN-less) connection.
The following options appear when you select to use a DSN connection:
Data Source Name Select the SAP HANA DSN that you created previously (see
Prerequisites).
User Name
Password
Enter the user name and password connected to the DSN.
Note
If you use X.509 authentication, you don't have to enter
a user name and password.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 69

Option Value
The following options appear when you create a DSN-less connection:
Database server name
Species the name of the computer where the SAP HANA
server is located.
If you're connecting to SAP HANA 2.0 SPS 01 MDC or later,
enter the SAP HANA database server name for the applica-
ble tenant database.
Note
See SAP HANA documentation to learn how to nd the
specic tenant database port number.
Port
Enter the port number to connect to the SAP HANA Server.
The default is 30015.
If you're connecting to SAP HANA 2.0 SPS 01 MDC or later,
enter the port number of the specic tenant database.
Note
See SAP HANA documentation to learn how to nd the
specic tenant database port number.
Advanced options
The following table contains descriptions for the advanced options in the SAP HANA datastore editor, including
options for SSL/TLS and X.509.
Note
Support for X.509 authentication is applicable for SAP HANA Server on premise 2.0 SP05 revision 56 and
above, and SAP HANA Cloud. For SAP HANA client, X.509 is applicable for SAP HANA ODBC client 2.7 and
above.
Option
Description
Database name Optional. Enter the specic tenant database name. Applica-
ble for SAP HANA version 2.0 SPS 01 MDC and later.
Additional connection parameters Enter information for any additional parameters that
the data source ODBC driver and database supports.
Use the following format: <parameter1=value1;
parameter2=value2>
70 PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services
Option Description
Use SSL encryption Species to use SSL/TLS encryption for the datastore con-
nection to the database.
• Yes: Creates the datastore with SSL/TLS encryption.
• No: Creates the datastore without SSL/TLS encryption.
Encryption parameters
Opens the Encryption Parameters dialog box.
To open the dialog, either double-click in the empty cell or
select the empty cell and then select the Ellipses (…) icon
that appears at the end.
Enabled only when you select Yes for Use SSL encryption or
Yes for Use X.509 authentication.
The following options are in the Encryption Parameters dialog box when you select Yes for Use SSL encryption:
Validate Certicate
Species whether the software validates the SAP HANA
server SSL certicate. If you do not select this option, none
of the other SSL options are available to complete.
Crypto Provider Species the crypto provider used for SSL/TLS and X.509
communication. Data Services populates Crypto Provider
automatically with commoncrypto. SAP CommonCryptoLib
library is the only supported cryptographic library for SAP
HANA.
Certicate host
Species the host name used to verify the server identity.
Choose one of the following actions:
• Leave blank. Data Services uses the value in Database
server name.
• Enter a string that contains the SAP HANA server host-
name.
• Enter the wildcard character “*” so that Data Services
doesn't validate the certicate host.
Key Store
Species the location and le name for your key store le.
You can also use a substitution parameter.
Note
If you choose to use X.509 authentication, the key store
PSE le must contain both the SSL server certicate
and X.509 client certicate. If the key store le name
isn't an absolute path, Data Services assumes the PSE
le is located in $SECUDIR.
X.509 authentication settings:
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 71

Option Description
Use X.509 authentication Species to use X.509 authentication.
Note
X.509 authentication is applicable for SAP HANA Server
on premise 2.0 SP05 revision 56 and above and SAP
HANA Cloud. For SAP HANA client, X.509 is applicable
for SAP HANA ODBC client 2.7 and above.
X.509 key store
Species the x509 key store le, which includes the X.509
client certicate. If the input isn't an absolute le path, Data
Services assumes that the le is in $SECUDIR. You can also
use a substitution parameter for X.509 key store.
Proxy group: For DSN-less connections only. For connecting to SAP HANA data through the SAP Cloud connector.
Proxy host Species the proxy server host.
Proxy port Species the proxy server port.
Proxy user name Species the proxy server user name.
Proxy password Species the proxy server password.
SAP cloud connector account Species the SAP Cloud connector account. Complete when
the SAP HANA data is in SAP Big Data Services.
Parent topic: SAP HANA database datastores [page 66]
Related Information
SAP HANA datastore prerequisites [page 68]
3.7.7Conguring DSN for SAP HANA on Windows
To use a DSN connection for an SAP HANA datastore, congure a DSN connection for Windows using the
ODBC Data Source Administrator.
Optionally include SSL/TLS encryption and the X.509 authentication settings when you congure the DSN.
Perform the prerequisites listed in SAP HANA datastore prerequisites [page 68].
For SSL/TLS encryption, perform the following steps:
1. Copy sapsrv.pse from $SECUDIR of the SAP HANA server.
2. Paste sapsrv.pse to $SECUDIR of the client.
3. Rename sapsrv.pse to sapcli.pse.
To congure DSN for SAP HANA on Windows, perform the following steps:
72
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

1. Open the ODBC Data Source Administrator.
Access the ODBC Data Source Administrator either from the datastore editor in Data Services Designer or
directly from your Start menu.
2. In the ODBC Data Source Administrator, open the System DSN tab and select Add.
3. Choose the SAP HANA ODBC driver and select Finish.
The driver is listed only after you select it in the ODBC Drivers Selector utility.
The ODBC Conguration for SAP HANA dialog box opens.
4. Enter a unique name in Data Source Name, and enter a description if applicable.
5. Choose the database type from the Database type list.
6. Enter the server host name in Host.
7. Enter the port number in Port.
8. Enter the tenant database name in Tenant database.
9. Optional: For SSL/TLS encryption and/or X.509 authentication, select Settings.
10. Optional: Complete the following options for SSL/TLS:
a. In the TLS/SSL group, select the following options:
• Connect to the database using TLS/SSL
• Validate the SSL certicate (optional)
b. Either leave Certicate host blank or enter a value:
If you leave Certicate host blank, Data Services uses the value in Database server name. If you don't
want the value from the Database server name, enter one of the following values:
• A string that contains the SAP HANA server hostname.
• The wildcard character “*”, so that Data Services doesn't validate the certicate host.
c. Specify the location and le name for your key store in Key Store.
d. Select OK.
11. Optional: Complete the following options for X.509 authentication:
a. Optional: In the TLS/SSL group, select Connect to the database using TLS/SSL.
b. Open Advanced ODBC Connection Property Setup and enter a string in Additional connection
properties:
To bypass certicate validation, enter the following string:
authenticationX509:<location_of_PSE>\x509.pse
sslValidateCertificate:FALSE
To validate certicate, enter the following string:
authenticationX509:<Location_of_PSE>\x509.pse
c. Select OK.
Task overview: SAP HANA [page 58]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 73

Related Information
Cryptographic libraries and global.ini settings [page 59]
X.509 authentication [page 61]
JWT authentication [page 62]
Bulk loading in SAP HANA [page 63]
Creating stored procedures in SAP HANA [page 65]
SAP HANA database datastores [page 66]
Conguring DSN for SAP HANA on Unix [page 74]
Datatype conversion for SAP HANA [page 76]
Using spatial data with SAP HANA [page 78]
3.7.8Conguring DSN for SAP HANA on Unix
Congure a DSN connection for an SAP HANA database datastore for Unix using the SAP Data Services
Connection Manager.
Optionally include SSL/TLS encryption and the X.509 authentication settings when you congure the DSN.
Perform the prerequisites listed in SAP HANA datastore prerequisites [page 68].
For SSL/TLS encryption, perform the following steps:
1. Copy sapsrv.pse from $SECUDIR of the SAP HANA server.
2. Paste sapsrv.pse to $SECUDIR of the client.
3. Rename sapsrv.pse to sapcli.pse.
Use the GTK+2 library to make a graphical user interface for the Connection Manager. Connection Manager is
a command-line utility. To use it with a UI, install the GTK+2 library. For more information about obtaining and
installing GTK+2, see https://www.gtk.org/
.
The following instructions assume that you have the user interface for Connection Manager.
1. Export $ODBCINI to a le in the same computer as the SAP HANA data source. For example:
export ODBCINI=<dir_path>/odbc.ini
2. Start SAP Data Services Connection Manager by entering the following command:
$LINK_DIR/bin/DSConnectionManager.sh
3. Open the Data Sources tab and select Add to display the list of database types.
4. In the Select Database Type dialog box, select the SAP HANA database type and select OK.
The conguration page opens with some of the connection information automatically completed:
• Absolute location of the odbc.ini le
• Driver for SAP HANA
• Driver version
5. Complete the following options:
74
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

• DSN Name
• Specify the Driver Name
• Specify the Server Name
• Specify the Server Instance
• Specify the User Name
• Type the database password
• Specify the Host Name
• Specify the Port
6. Optional: To include SSL/TLS encryption, complete the following options:
• Specify the SSL Encryption Option: Select y.
• Specify the Validate Server Certicate Option: Select y or n.
• Specify the HANA SSL provider: Accept commoncrypto.
• Specify the SSL Certicate File: Enter the absolute path of the SSL trust store le.
• Specify the SSL Key File: Enter the absolute path of the SSL key store le.
Note
If you enable X.509 authentication, the key store le must contain both the SSL server certicate
and the X.509 client certicate.
• Specify the SSL Host Name in Certicate:
• Leave blank to use the database server name.
• Enter a string that contains the SAP HANA server hostname.
• Enter the wildcard character “*” so that Data Services doesn't validate the certicate host.
For descriptions of the DSN and SSL/TLS options, see SAP HANA datastore prerequisites [page 68].
7. Optional: To include X.509 authentication, complete the following X.509 option: Specify the HANA User
Authentication Method: Select 1: x.509.
8. Press Enter .
The system tests the connection. The message “Successfully edited database source.” appears when
you've successfully congured the DSN.
Task overview: SAP HANA [page 58]
Related Information
Cryptographic libraries and global.ini settings [page 59]
X.509 authentication [page 61]
JWT authentication [page 62]
Bulk loading in SAP HANA [page 63]
Creating stored procedures in SAP HANA [page 65]
SAP HANA database datastores [page 66]
Conguring DSN for SAP HANA on Windows [page 72]
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 75
Datatype conversion for SAP HANA [page 76]
Using spatial data with SAP HANA [page 78]
3.7.9Datatype conversion for SAP HANA
SAP Data Services performs data type conversions when it imports metadata from SAP HANA sources or
targets into the repository and when it loads data into an external SAP HANA table or le.
Data Services uses its own conversion functions instead of conversion functions that are specic to the
database or application that is the source of the data.
Additionally, if you use a template table or Data_Transfer table as a target, Data Services converts from internal
data types to the data types of the respective DBMS.
SAP HANA datatypes [page 76]
SAP Data Services converts SAP HANA data types when you import metadata from an SAP HANA
source or target into the repository.
Parent topic: SAP HANA [page 58]
Related Information
Cryptographic libraries and global.ini settings [page 59]
X.509 authentication [page 61]
JWT authentication [page 62]
Bulk loading in SAP HANA [page 63]
Creating stored procedures in SAP HANA [page 65]
SAP HANA database datastores [page 66]
Conguring DSN for SAP HANA on Windows [page 72]
Conguring DSN for SAP HANA on Unix [page 74]
Using spatial data with SAP HANA [page 78]
3.7.9.1 SAP HANA datatypes
SAP Data Services converts SAP HANA data types when you import metadata from an SAP HANA source or
target into the repository.
Data Services converts data types back to SAP HANA data types when you load data into SAP HANA after
processing.
76
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

Data type conversion on import
SAP HANA data type Converts to Data Services data type
integer int
tinyint int
smallint int
bigint decimal
char varchar
nchar varchar
varchar varchar
nvarchar varchar
decimal or numeric decimal
oat double
real real
double double
date date
time time
timestamp datetime
clob long
nclob long
blob blob
binary blob
varbinary blob
The following table shows the conversion from internal data types to SAP HANA data types in template tables.
Data type conversion on load to template table
Data Services data type
Converts to SAP HANA data type
blob blob
date date
datetime timestamp
decimal decimal
double double
int integer
interval real
long clob/nclob
real decimal
time time
timestamp timestamp
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 77

Data Services data type Converts to SAP HANA data type
varchar varchar/nvarchar
Parent topic: Datatype conversion for SAP HANA [page 76]
3.7.10Using spatial data with SAP HANA
SAP Data Services supports spatial data such as point, line, polygon, collection, for specic databases.
Data Services supports spatial data in the following databases:
• Microsoft SQL Server for reading
• Oracle for reading
• SAP HANA for reading and loading
When you import a table with spatial data columns, Data Services imports the spatial type columns as
character based large objects (clob). The column attribute is Native Type, which has the value of the
actual data type in the database. For example, Oracle is SDO_GEOMETRY, Microsoft SQL Server is geometry/
geography, and SAP HANA is ST_GEOMETRY.
When reading a spatial column from HANA, Data Services reads it as EWKT (Extended Well-Known Text). When
loading a spatial column to HANA the input must have the correct SRID (spatial reference identier). Note that
creating template tables with a spatial column and SRID is not supported.
Limitations
• You cannot create template tables with spatial types because spatial columns are imported into Data
Services as clob.
• You cannot manipulate spatial data inside a data ow because the spatial utility functions are not
supported.
Loading spatial data to SAP HANA [page 79]
Load spacial data from Oracle or Microsoft SQL Server to SAP HANA.
Loading complex spatial data from Oracle to SAP HANA [page 79]
Complex spatial data is data such as circular arcs and LRS geometries.
Parent topic: SAP HANA [page 58]
Related Information
Cryptographic libraries and global.ini settings [page 59]
X.509 authentication [page 61]
JWT authentication [page 62]
Bulk loading in SAP HANA [page 63]
Creating stored procedures in SAP HANA [page 65]
78
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services
SAP HANA database datastores [page 66]
Conguring DSN for SAP HANA on Windows [page 72]
Conguring DSN for SAP HANA on Unix [page 74]
Datatype conversion for SAP HANA [page 76]
3.7.10.1Loading spatial data to SAP HANA
Load spacial data from Oracle or Microsoft SQL Server to SAP HANA.
Learn more about spatial data by reading the SAP HANA documentation.
1. Import a source table from Oracle or Microsoft SQL Server to SAP Data Services.
2. Create a target table in SAP HANA with the appropriate spatial columns.
3. Import the SAP HANA target table into Data Services.
4. Create a data ow with an Oracle or Microsoft SQL Server source as reader.
Include any necessary transformations.
5. Add the SAP HANA target table as a loader.
Make sure not to change the data type of spatial columns inside the transformations.
6. Build a job that includes the data ow and run it to load the data into the target table.
Task overview: Using spatial data with SAP HANA [page 78]
Related Information
Loading complex spatial data from Oracle to SAP HANA [page 79]
3.7.10.2Loading complex spatial data from Oracle to SAP
HANA
Complex spatial data is data such as circular arcs and LRS geometries.
1. Create an Oracle datastore for the Oracle table.
For instructions, see the guide Supplement for Oracle Applications.
2. Import a source table from Oracle to SAP Data Services using the Oracle datastore.
3. Create a target table in SAP HANA with the appropriate spatial columns.
4. Import the SAP HANA target table into Data Services.
5. Create a data ow in Data Services, but instead of including an Oracle source, include a SQL transform as
reader.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 79

6. Retrieve the data from the Oracle database directly. First, open the SQL transform, then add the SQL
Select statement. Add the SQL Select statement by calling the following functions against the spatial data
column:
• SDO_UTIL.TO_WKTGEOMETRY
• SDO_GEOM.SDO_ARC_DENSIFY
For example, in the SQL below, the table name is “Points”. The “geom” column contains the following
geospatial data:
SELECT
SDO_UTIL.TO_WKTGEOMETRY(
SDO_GEOM.SDO_ARC_DENSIFY(
geom,
(MDSYS.SDO_DIM_ARRAY(
MDSYS.SDO_DIM_ELEMENT('X',-83000,275000,0.0001),
MDSYS.SDO_DIM_ELEMENT('Y',366000,670000,0.0001)
)),
'arc_tolerance=0.001'
)
)
from "SYSTEM"."POINTS"
For more information about how to use these functions, see the Oracle Spatial Developer's Guide on the
Oracle Web page at SDO_GEOM Package (Geometry) .
7. Build a job in Data Services that includes the data ow and run it to load the data into the target table.
Task overview: Using spatial data with SAP HANA [page 78]
Related Information
Loading spatial data to SAP HANA [page 79]
3.8 Amazon Athena
Use the Simba Athena ODBC driver to connect to Amazon Athena.
Once connected to Amazon Athena, you can browse metadata, import tables, read data from tables, and load
data into tables. Note that template table creation is not supported.
Note
Before you begin, make sure you have the necessary privileges for Athena and for the underlying S3
storage for the table data. If you need help with privileges, please refer to the Amazon documentation or
contact their Support team.
Note
DELETE is not allowed for the normal external table. The DELETE is transactional and is supported only for
Apache Iceberg tables.
80
PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services

1. Download and install the Simba Athena ODBC driver. You can download the driver from https://
docs.aws.amazon.com/athena/latest/ug/connect-with-odbc.html .
2. Create a data source name (DSN).
For Windows:
1. Open the Microsoft ODBC Data Source Administrator.
2. Populate the elds in the Simba Athena ODBC Driver DSN Setup window. The AWS Region and S3
Output Location elds are required.
3. Click Authentication Options and select IAM Credentials for the Authentication Type.
Enter the User (the access key provided by your AWS account) and the Password (the secret key
provided by your AWS account).
4. Test the connection and close the window.
For Linux:
For information about manually conguring a driver and data source for non-native ODBC data sources,
see Non-Native ODBC data sources.
3. In the Data Services Designer, create and congure an ODBC database datastore and choose the DSN you
created for Athena as the Data Source Name.
For more information, see Creating a database datastore in the Designer Guide.
Related Information
ODBC capacities and functions for Athena [page 82]
3.8.1Athena data type conversions
When you import metadata from an Athena table into the repository, SAP Data Services converts Athena data
types to Data Services native data types for processing.
Athena database data type
Data Services Data Type
Boolean Int
Smallint/Tinyint Int
Int Int
Bigint Decimal(19,0)
Double Double
Decimal(prec,scale) Decimal(prec,scale)
Char(n) Varchar(n)
Varchar(n) Varchar(n)
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 81
Athena database data type Data Services Data Type
String Varchar(N)
Note
N depends on the setting in the data source.
Date
Date
Timestamp Datetime
Array Varchar(N)
Note
N depends on the setting in the data source.
Map
Varchar(N)
Note
N depends on the setting in the data source.
Struct
Varchar(N)
Note
N depends on the setting in the data source.
Binary
Varchar(255)
Note
Unknown data type. Depends on the setting of the
Import unknown datatype as varchar option in the Data
Services data store.
3.8.2ODBC capacities and functions for Athena
Capacities and functions that are supported by Amazon Athena.
ODBC capacities
Options
Supported
Parameterized SQL Not supported. Option is set to No by default.
Array Fetch Yes
Outer Join Yes
SQL92 Join syntax Yes
AutoCommit Yes
82 PUBLIC
Data Services Supplement for Big Data
Big data in SAP Data Services
ODBC functions
Function Push down
Absolute Yes
Ceiling Yes
Floor Yes
Round Yes
Truncate Yes
Sqrt Yes
Log Yes
Ln Yes
Power Yes
Mod Yes
Lower Yes
Upper Yes
Trim Yes
String Length Yes
Substring Yes
Soundex Not supported
Year/Month/Week/DayOfMonth/DayOfYear Yes
Sysdate/Systime Yes
Avg/Count/Sum Yes
Max/Min Yes
Nvl Not supported
Ifthenelse Yes
For more information, see Value descriptions for capability and function options and ODBC Capability and
function options in the Designer Guide.
Data Services Supplement for Big Data
Big data in SAP Data Services
PUBLIC 83
4 Cloud computing services
SAP Data Services provides access to various cloud databases and storages to use for reading or loading big
data.
Cloud databases [page 84]
Access various cloud databases through le location objects and le format objects.
Cloud storages [page 116]
Access various cloud storages through le location objects and gateways.
4.1 Cloud databases
Access various cloud databases through le location objects and le format objects.
SAP Data Services supports many cloud database types to use as readers and loaders in a data ow.
Amazon Redshift database [page 85]
Amazon Redshift is a cloud database designed for large data les.
Azure SQL database [page 96]
Developers and administrators who use Microsoft SQL Server can store on-premise SQL Server
workloads on an Azure virtual machine in the cloud.
Google BigQuery [page 98]
The Google BigQuery datastore contains access information and passwords so that the software can
open your Google BigQuery account on your behalf.
Google BigQuery ODBC [page 99]
With a Google BigQuery ODBC datastore, make ODBC calls to your Google BigQuery data sets to
download, process, and upload data in SAP Data Services.
SAP HANA Cloud, data lake database [page 99]
Access your data lake database in an SAP HANA Cloud by creating a database datastore.
Snowake [page 103]
Snowake provides a data warehouse that is built for the cloud.
Parent topic: Cloud computing services [page 84]
Related Information
Cloud storages [page 116]
84
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

4.1.1Amazon Redshift database
Amazon Redshift is a cloud database designed for large data les.
In SAP Data Services, create a database datastore to access your data from Amazon Redshift. Additionally,
load Amazon S3 data les into Redshift using the built-in function load_from_s3_to_redshift.
Authentication
Select from two authentication methods when you congure your connection to Amazon Redshift:
• Standard: Use your user name and password to connect to Amazon Redshift.
• AWS IAM (Identication and Access Management): There are two types of IAM to select from:
• AWS IAM credentials: Use Cluster ID, Region, Access Key ID, and Secret Access Key for
authentication.
• AWS IAM prole: Use an AWS prole and enter your Cluster ID, Region, and prole name for
authentication.
Note
If you enter the server name in the datastore editor as a full server endpoint, Cluster ID and Region
aren't required. However, if you enter a server name as a gateway, Cluster ID and Region are required.
Encryption
You control whether you require SSL for your Amazon Redshift cluster database by enabling or disabling SSL.
In SAP Data Services, enable SSL in the datastore editor and then set the mode in the Encryption Parameters
dialog box. To learn how the SAP Data Services SSL mode settings aect the SSL mode setting in Amazon
Redshift cluster database, see the table in Using SSL and Trust CA certicates in ODBC in your Amazon
Redshift documentation.
Note
Beginning in SAP Data Services 4.3.02.01, use the options Use SSL encryption and Encryption parameters
to congure SSL encryption instead of entering options in the Additional connection parameters option.
Note
The SSL modes, verify-ca and verify-full, require the application to check the trusted root CA certicate.
The latest Redshift ODBC driver ships with bundled trusted root CA certicates. Check to ensure that your
installed ODBC driver includes trusted root CA certicates. For more information about certicates, see
Connect using SSL in the AWS Redshift documentation. If the root.crt le isn't in your ODBC driver
library directory (C:\Program Files\Amazon Redshift ODBC Driver\lib), you must download the
server certicate from Amazon. Save the certicate as root.crt in the ODBC library directory, or save the
server certicate in a special directory on your system.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 85
The Redshift ODBC driver sets the boolean data type to string by default. However, you can't insert a string to
the boolean data type column in some ODBC driver versions. Therefore, uncheck the data type option Show
Boolean Column As String during DSN conguration. In the ODBC driver version 1.4.65 and later, you can set
the boolean data type to int.
Connection information
The Amazon Redshift datastore supports either a DSN or server-based connection. The following list contains
information about these connections:
• For a server-based connection on Windows, select the Redshift ODBC driver by using the
ODBCDriverSelector.exe utility located under %link_dir%\bin. Then, congure the Amazon Redshift
datastore and make sure that Use data source name (DNS) isn't selected. For information about
conguring DSN on Linux, see Conguring a Redshift DSN connection on Linux using ODBC [page 90].
• To congure a DSN connection, select the option Use data source name (DSN) in the datastore editor to
congure the DSN.
Amazon Redshift datastores [page 87]
Use an Amazon Redshift datastore to access data from your Redshift cluster datastore for processing
in SAP Data Services.
Conguring a Redshift DSN connection on Linux using ODBC [page 90]
For a data source name (DSN) connection, use the DS Connection Manager to congure Amazon
Redshift as a source.
Amazon Redshift source [page 91]
Option descriptions for using an Amazon Redshift database table as a source in a data ow.
Amazon Redshift target table options [page 92]
Descriptions of options for using an Amazon Redshift table as a target in a data ow.
Amazon Redshift data types [page 94]
SAP Data Services converts Redshift data types to the internal data types when it imports metadata
from a Redshift source or target into the repository.
Parent topic: Cloud databases [page 84]
Related Information
Azure SQL database [page 96]
Google BigQuery [page 98]
Google BigQuery ODBC [page 99]
SAP HANA Cloud, data lake database [page 99]
Snowake [page 103]
86
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

4.1.1.1 Amazon Redshift datastores
Use an Amazon Redshift datastore to access data from your Redshift cluster datastore for processing in SAP
Data Services.
Use a Redshift database datastore for the following tasks:
• Import table metadata.
• Read Redshift tables in a data ow.
• Preview and process data.
• Create and import template tables.
• Load processed data to your Redshift cluster datastore.
• Load Amazon S3 data les into a Redshift table using the built-in function load_from_s3_to_redshift.
The following table describes the options specic for Redshift when you create or edit a datastore. For
descriptions of basic datastore options, see Common datastore options in the Designer Guide.
Main window options
Option Description
Database server name Species the server name for the Redshift cluster database. Enter as a gateway
hostname, gateway IP address, or as an endpoint.
If you enter the server name as an endpoint, you don't have to complete the
Cluster ID and Region options.
User Name
Species the Redshift cluster database user name. User name is required
regardless of the authentication method you choose.
Note
The cluster database user name isn't the same as your AWS Identity and
Access Management (IAM) user name.
Password
Species the password that corresponds to the entered User Name. Only appli-
cable when you select Standard for Authentication Method.
Additional connection parameters
Species additional connection information, such as to use integer for boolean
data type.
Example
The Amazon Redshift ODBC driver uses the string (char) data type. To
insert the boolean data type as an integer, enter BoolsAsChar=0. After
you re-import the table, the Bool data type column shows int.
Use SSL encryption
Species to use SSL encryption when connecting to your Redshift cluster
database. When you set to Yes, also open the Encryption parameters dialog and
select the SSL mode.
If you set Use SSL Encryption to No, SSL mode is disabled.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 87
Option Description
Encryption parameters
Species the level of SSL encryption on the client side.
Select the text box to open the Encryption Parameters dialog. Choose from one
of the following modes:
• Allow: If the server requires SSL, connects with SSL encryption.
• Prefer: Connects with SSL encryption.
• Require: Connects with SSL encryption.
• Verify-ca: Connects with SSL encryption after verifying the server certi-
cate authority (CA).
• Verify-full: Connects with SSL encryption after verifying the server CA and
verifying that the server host name matches the host name attribute on
the server CA.
Note
SSL settings for Amazon Redshift aect some of the SSL modes. For more
information, see
Using SSL and Trust CA certicates in ODBC in your Amazon Redshift
documentation.
Authentication Method
Species how to authenticate the connection to Amazon Redshift cluster data-
base:
• Standard: Uses your user name and password to authenticate. You must
complete the options User Name and Password.
• AWS IAM Credentials: Uses your AWS Cluster ID, Region, AccessKeyId, and
SecretAccessKey to authenticate.
• AWS Prole: Authenticates using your AWS Cluster ID, Region, and Prole
Name to authenticate.
Cluster ID
Species the ID assigned to your Amazon Redshift cluster. Obtain from the
AWS Management Console.
Not applicable when the Database server name is an endpoint, which includes
the cluster ID.
Region
Species the region assigned to your Amazon Redshift cluster. Obtain from the
AWS Management Console.
Not applicable when the Database server name is an endpoint, which includes
the region.
For more information about AWS regions, see your Amazon Redshift documen-
tation.
88 PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Option Description
AccessKeyId
Species your AWS IAM access key ID. Obtain from the AWS Management
Console.
Note
The datastore editor encrypts the access key ID when you enter it so no
one else can see or use it.
Not applicable when you select AWS Prole for Authentication Method.
SecretAccessKey
Species your AWS IAM secret access key. Obtain from the AWS Management
Console.
Note
The secret access key appears the rst time you create an access key ID in
AWS. After that, you must remember it because AWS won't show it again.
The datastore editor encrypts the secret access key when you enter it so
no one else can see or use it.
Not applicable when you select AWS Prole for Authentication Method.
Prole Name
Species your AWS prole name when you use AWS IAM Prole for
Authentication Method. For more information about using an authentication
prole, see your AWS Redshift documentation.
Note
If you choose to use AWS Prole for authentication, a credentials le is
required. The credentials le contains chained roles proles. The default
location for a credentials le is ~/.aws/Credentials, or ~/.aws/
config. You can use the AWS_SHARED_CREDENTIALS_FILE envi-
ronment variable to point to a dierent credentials le location.
Not applicable when you select AWS IAM Credentials for Authentication
Method.
Parent topic: Amazon Redshift database [page 85]
Related Information
Conguring a Redshift DSN connection on Linux using ODBC [page 90]
Amazon Redshift source [page 91]
Amazon Redshift target table options [page 92]
Amazon Redshift data types [page 94]
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 89
4.1.1.2 Conguring a Redshift DSN connection on Linux
using ODBC
For a data source name (DSN) connection, use the DS Connection Manager to congure Amazon Redshift as a
source.
Before performing the following task, download and install the Amazon Redshift ODBC driver for Linux.
For details, and the latest ODBC driver download, see Conguring an ODBC Connection on the Amazon
Website. For complete information about installing and conguring an ODBC driver, nd a link to download the
PDF le Amazon Redshift ODBC Data Connector Installation and Conguration Guide. Find a link tor the guide in
the topic “Conguring an ODBC Connection”.
To congure a DSN connection on Linux for an Amazon Redshift cluster database, install the downloaded driver
and then perform the following steps:
1. Congure the following les following directions in the Amazon Redshift ODBC Data Connector Installation
and Conguration Guide:
• amazon.redshiftodbc.ini
• odbc.ini
• odbcinst.ini
If you installed the ODBC driver to the default location, the les are in /opt/amazon/
redshiftodbc/lib/64.
2. Open the amazon.redshiftodbc.ini and add a line at the end of the le to point to the
libodbcinst.so le.
The libodbcinst.so le is in the unixODBC/lib directory.
Example
/home/ec2-user/unixODBC/lib/libodbcinst.so
3. Find the [Driver] section in the amazon.redshiftodbc.ini le, and set DriverManagerEncoding to
UTF-16.
Example
[Driver]
DriverManagerEncoding=UTF-16
4. Run DSConnectionManager.sh and congure a data source for Redshift.
The SAP Data Services installer places the DS Connection Manager in $LINK_DIR//bin/
DSConnectionManager.sh by default. Use the following example as a guide.
Example
Example of DS Connection Manager using an AWS IAM Credentials authentication method:
Specify the DSN name from the list or add a new one:
<DSN_Name>
Specify the Unix ODBC Lib Path:
/build/unixODBC-232/lib
Specify the Driver:
/build/redshiftodbc/lib/64/libamazonredshiftodbc64.so
90
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Specify the Driver Version:
<driver_version>
Specify the Host Name:
<Gateway or Endpoint>
Specify the Port:
<Port_Number>
Specify the Database:
<Database_Name>
Specify the Authentication Method(1:Standard|2:AWS IAM Credentials|3:AWS Prole):'1'
2
Specify the User Name:
<User_Name>
Specify the Cluster ID:
<Cluster_ID>
Specify the Region:
<Region>
Specify the AccessKeyId: (no echo)
Specify the SecretAccessKey: (no echo)
Specify the Redshift SSL certicate verication mode[require|allow|disable|prefer|verify-ca|verify-
full]:'verify-ca'
verify-ca
Testing connection...
Successfully add data source.
Task overview: Amazon Redshift database [page 85]
Related Information
Amazon Redshift datastores [page 87]
Amazon Redshift source [page 91]
Amazon Redshift target table options [page 92]
Amazon Redshift data types [page 94]
4.1.1.3 Amazon Redshift source
Option descriptions for using an Amazon Redshift database table as a source in a data ow.
When you use an Amazon Redshift table as a source, the software supports the following features:
• All Redshift data types
• Optimized SQL
• Basic push-down functions
The following list contains behavior dierences from Data Services when you use certain functions with
Amazon Redshift:
• When using add_month(datetime, int), pushdown doesn't occur if the second parameter is not in an
integer data type.
• When using cast(input as ‘datatype’), pushdown does not occur if you use the real data type.
• When using to_char(input, format), pushdown doesn't occur if the format is ‘XX’ or a number such
as ‘099’, ‘999’, ‘99D99’, ‘99G99’.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 91

• When using to_date(date, format), pushdown doesn't occur if the format includes a time part, such
as ‘YYYY-MM-DD HH:MI:SS’.
For more about push down functions, see SAP Note 2212730
, “SAP Data Services push-down operators,
functions, and transforms”. Also read about maximizing push-down operations in the Performance
Optimization Guide.
The following table lists source options when you use an Amazon Redshift table as a source:
Option
Description
Table name Name of the table that you added as a source to the data ow.
Table owner Owner that you entered when you created the Redshift table.
Datastore name Name of the Redshift datastore.
Database type Database type that you chose when you created the datastore. You cannot change
this option.
The Redshift source table also uses common table source options.
For more information about pushdown operations and viewing optimized SQL, see the Performance
Optimization Guide.
Parent topic: Amazon Redshift database [page 85]
Related Information
Amazon Redshift datastores [page 87]
Conguring a Redshift DSN connection on Linux using ODBC [page 90]
Amazon Redshift target table options [page 92]
Amazon Redshift data types [page 94]
Amazon Redshift data types [page 94]
Amazon Redshift target table options [page 92]
Amazon Redshift datastores [page 87]
4.1.1.4 Amazon Redshift target table options
Descriptions of options for using an Amazon Redshift table as a target in a data ow.
The Amazon Redshift target supports the following features:
• input keys
• auto correct
• data deletion from a table before loading
• transactional loads
• load triggers, pre-load commands, and post-load commands
92
PUBLIC
Data Services Supplement for Big Data
Cloud computing services
• bulk loading
When you use the bulk load feature, Data Services generates les and saves the les to the bulk load
directory that is dened in the Amazon Redshift datastore. If there is no value set for the bulk load
directory, the software saves the data les to the default bulk load location at: %DS_COMMON_DIR%/log/
BulkLoader. Data Services then copies the les to Amazon S3 and executes the Redshift copy command
to upload the data les to the Redshift table.
Note
The Amazon Redshift primary key is informational only and the software does not enforce key constraints
for the primary key. Be aware that using SELECT DISTINCT may return duplicate rows if the primary key is
not unique.
Note
The Amazon Redshift ODBC driver does not support parallelize load via ODBC into a single table. Therefore,
the Number of Loaders option in the Options tab is not applicable for a regular loader.
Bulk loader tab
Option
Description
Bulk load Select to use bulk loading options to write the data.
Mode Select the mode for loading data in the target table:
• Append: Adds new records to the table.
Note
Append mode does not apply to template tables.
• Truncate: Deletes all existing records in the table, and then adds new records.
S3 le location
Enter or select the path to the Amazon S3 conguration le. You can enter a variable for
this option.
Maximum rejects Enter the maximum number of acceptable errors. After the maximum is reached, the
software stops Bulk loading. Set this option when you expect some errors. If you enter 0,
or if you do not specify a value, the software stops the bulk loading when the rst error
occurs.
Column delimiter
Enter a single-character column delimiter.
Text delimiter Enter a single-character text delimiter.
If you insert a Text delimiter, other than a single quote (‘), as well as a comma (,) for the
Column delimiter, Data Services will treat the data le as a .csv le.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 93

Option Description
Generate les only Enable to generate data les that you can use for bulk loading.
When enabled, the software loads data into data les instead of the target in the data ow.
The software writes the data les into the bulk loader directory specied in the datastore
denition.
If you do not specify a bulk loader directory, the software writes the les to
<%DS_COMMON_DIR%>\log\bulkloader\<tablename><PID>. Then you man-
ually copy the les to the Amazon S3 remote system.
The le name is
<tablename><PID>_<timestamp>_<loader_number>_<number of
files generated by each loader>.dat, where <tablename> is the name
of the target table.
Clean up bulk loader directory
after load
Enable to delete all bulk load-oriented les from the bulk load directory and the Amazon
S3 remote system after the load is complete.
Parameters Allows you to enter some Amazon Redshift copy command data conversion parameters,
such as escape, emptyasnull, blanksasnull, ignoredblanklines, and so on. These parame-
ters dene how to insert data to a Redshift table. For more information about the param-
eters, see https://docs.aws.amazon.com/redshift/latest/dg/r_COPY.html#r_COPY-syn-
tax-overview-optional-parameters
.
General settings
Option
Description
Number of loaders Sets the number of threads to generate multiple data les
for a parallel load job. Enter a positive integer for the number
of loaders (threads).
Parent topic: Amazon Redshift database [page 85]
Related Information
Amazon Redshift datastores [page 87]
Conguring a Redshift DSN connection on Linux using ODBC [page 90]
Amazon Redshift source [page 91]
Amazon Redshift data types [page 94]
4.1.1.5 Amazon Redshift data types
SAP Data Services converts Redshift data types to the internal data types when it imports metadata from a
Redshift source or target into the repository.
The following table lists the internal data type that Data Services uses in place of the Redshift data type.
94
PUBLIC
Data Services Supplement for Big Data
Cloud computing services
Convert Redshift to Data Services internal data type
Redshift data type Converts to Data Services data type
smallint int
integer int
bigint decimal(19,0)
decimal decimal
real real
oat double
boolean varchar(5)
char char
Note
The char data type doesn't support multibyte characters. The maximum range is 4096
bytes.
nchar char
varchar
nvarchar
varchar
Note
The varchar and nvarchar data types support UTF8 multibyte characters. The size is the
number of bytes and the max range is 65535.
Caution
If you try to load multibyte characters into a char or nchar data type column, Redshift
issues an error. Redshift internally converts nchar and nvarchar data types to char and
varchar. The char data type in Redshift doesn't support multibyte characters. Use overow
to catch the unsupported data or, to avoid this problem, create a varchar column instead of
using the char data type.
date date
timestamp datetime
text varchar(256)
bpchar char(256)
The following data type conversions apply when you use a Redshift template table as the target.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 95
Data Services internal data type to Redshift data type
Data Services data type Redshift template table data type
blob varchar(max)
date date
datetime datetime
decimal decimal
double double precision
int integer
interval oat
long varchar(8190)
real oat
time varchar(25)
timestamp datetime
varchar varchar/nvarchar
char char/nchar
Parent topic: Amazon Redshift database [page 85]
Related Information
Amazon Redshift datastores [page 87]
Conguring a Redshift DSN connection on Linux using ODBC [page 90]
Amazon Redshift source [page 91]
Amazon Redshift target table options [page 92]
4.1.2Azure SQL database
Developers and administrators who use Microsoft SQL Server can store on-premise SQL Server workloads on
an Azure virtual machine in the cloud.
The Azure virtual machine supports both Unix and Windows platforms.
Moving les to and from Azure containers [page 97]
96
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

To move blobs to or from a Microsoft Azure container, use built-in functions in a script object and a le
location object.
Parent topic: Cloud databases [page 84]
Related Information
Amazon Redshift database [page 85]
Google BigQuery [page 98]
Google BigQuery ODBC [page 99]
SAP HANA Cloud, data lake database [page 99]
Snowake [page 103]
4.1.2.1 Moving les to and from Azure containers
To move blobs to or from a Microsoft Azure container, use built-in functions in a script object and a le location
object.
Note
Files are called blobs when they are in an Azure container.
Before you perform the following steps, create a le location object for the Azure container. Also create an
unstructured binary text le format that describes the blob in the Azure container. Use the le format in a data
ow to perform extra operations on the blob.
Use an existing Azure container or create a new one. Because SAP Data Services doesn't internally manipulate
the blobs in an Azure container, the blobs can be of any type. Currently, Data Services supports the block blob
in the container storage type.
To use built-in functions to upload les to a container storage blob in Microsoft Azure, perform the following
high-level steps:
1. Create a storage account in Azure and take note of the primary shared key.
For instructions, see your Microsoft documentation.
2. Create a le location object with the Azure Cloud Storage protocol.
3. Create a job in Data Services Designer and include the applicable le format as source or target.
4. Add scripts to the job that contain one or both of the following built-in functions:
To move les between remote and local directories, use the following scripts:
• copy_to_remote_system
• copy_from_remote_system
Example
To access a subfolder in your Azure container, specify the subfolder in the following script:
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 97

copy_to_remote_system('New_FileLocation', '*', '<container_name>/
<remote_directory>/<sub_folder>')
The script copies all of the les from the local directory specied in the le location object to the
container specied in the same object. When you include the remote directory and subfolder in the
script, the function copies all of the les from the local directory to the subfolder specied in the script.
5. Save and run the job.
Task overview: Azure SQL database [page 96]
4.1.3Google BigQuery
The Google BigQuery datastore contains access information and passwords so that the software can open your
Google BigQuery account on your behalf.
After accessing your account, SAP Data Services can load data to or extract data from your Google BigQuery
projects:
• Extract data from a Google BigQuery table to use as a source for Data Services processes.
• Load generated data from Data Services to Google BigQuery for analysis.
• Automatically create and populate a table in your Google BigQuery dataset by using a Google BigQuery
template table.
You can also reference the Google BigQuery datastore in the built-in function load_from_gcs_to_gbq, to
load data from your GCS to a Google BigQuery table. For details about the function, see the Reference Guide.
Note
We recommend that you create a Google BigQuery ODBC datastore instead of the Google BigQuery
datastore. The Google BigQuery ODBC datastore uses the Magnitude Simba ODBC driver for BigQuery,
which supports standard SQL and more data types than the Google BigQuery datastore. For more
information, see SAP Note 3241713
.
For complete information about how Data Services supports Google BigQuery, see the Supplement for Google
BigQuery.
Parent topic: Cloud databases [page 84]
Related Information
Amazon Redshift database [page 85]
Azure SQL database [page 96]
Google BigQuery ODBC [page 99]
SAP HANA Cloud, data lake database [page 99]
Snowake [page 103]
98
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

4.1.4Google BigQuery ODBC
With a Google BigQuery ODBC datastore, make ODBC calls to your Google BigQuery data sets to download,
process, and upload data in SAP Data Services.
To access the data in your Google BigQuery account, the datastore uses the Simba ODBC driver for Google
BigQuery, which supports the OAuth 2.0 protocol for authentication and authorization. Congure the driver to
provide your credentials and authenticate the connection to the data using either a Google user account or a
Google service account.
Note
Beginning with Data Services 4.2.13, we recommend that you create a Google BigQuery ODBC datastore
instead of the Google BigQuery datastore. The Google BigQuery ODBC datastore uses the Magnitude
Simba ODBC driver for BigQuery, which supports standard SQL and more data types than the Google
BigQuery datastore.
Note
Data Services supports Google BigQuery ODBC datastore on Windows and Linux platforms only.
For information about how Data Services supports Google BigQuery ODBC, see the Supplement for Google
BigQuery.
Parent topic: Cloud databases [page 84]
Related Information
Amazon Redshift database [page 85]
Azure SQL database [page 96]
Google BigQuery [page 98]
SAP HANA Cloud, data lake database [page 99]
Snowake [page 103]
4.1.5SAP HANA Cloud, data lake database
Access your data lake database in an SAP HANA Cloud by creating a database datastore.
SAP HANA Cloud, data lake consists of a data lake Relational Engine and data lake Files:
• The data lake Relational Engine provides high-performance analysis for petabyte volumes of relational
data.
• Data lake Files provide managed access to structured, semistructured, and unstructured data that is
stored as les in the data lake.
For more information about SAP HANA Cloud, data lake, see the documentation on the SAP Customer Portal.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 99

SAP HANA Cloud, data lake database is a cloud version of SAP IQ. It uses native ODBC support. Access your
data in your data lake with a server-named (DSN-less) connection. SSL/TLS 1.2 protocol is required.
SAP HANA Cloud, data lake supports bulk loading and pushdown to the database level. Further, you don't need
to use VPN or VPC to connect to your data lake database.
Prerequisites
Download the SAP HANA client server package from the SAP Software center at https://
launchpad.support.sap.com/#/softwarecenter . Enter the search term HANADLCLIENT. Select to download
the SAP HANA data lake client package based on your operating system and the applicable version. The
package includes the native ODBC driver, which you must congure using either the ODBC Driver Selector
(Windows) or the DS Connection Manager (Linux).
For more information about installing the SAP HANA Cloud data lake client, see the SAP HANA Cloud, Data
Lake Client Interfaces guide.
Datastore options for SAP HANA Cloud, data lake [page 100]
The datastore for SAP HANA Cloud, data lake contains the connection information that SAP Data
Services uses to connect to your database.
Congure ODBC driver in DS Connection Manager for Linux [page 101]
Congure the ODBC driver for connecting to your SAP HANA Cloud, data lake database for Linux using
the DS Connection Manager.
Parent topic: Cloud databases [page 84]
Related Information
Amazon Redshift database [page 85]
Azure SQL database [page 96]
Google BigQuery [page 98]
Google BigQuery ODBC [page 99]
Snowake [page 103]
4.1.5.1 Datastore options for SAP HANA Cloud, data lake
The datastore for SAP HANA Cloud, data lake contains the connection information that SAP Data Services
uses to connect to your database.
Create and congure a data lake datastore following the basic instructions in Creating a database datastore in
the Designer Guide.
The following table contains the options to complete that are specic for data lake.
100
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Option Value
Datastore Type Database
Database Type SAP HANA data lake
Authentication Method Choose between Basic and X509.
X509 Client Certicate
Depends on the Authentication Method:
• If you chose Basic, this option is not available.
• If you chose X509, select the Certicate le in your le
system. Substitution Parameter is supported.
The User Name and Password elds are not available in
this case.
Use SSL encryption
SSL/TLS encryption is required, therefore you cannot
change this value from Yes.
Encryption parameters Double-click in the cell to open the Encryption Parameters
dialog box.
Encryption Parameters dialog box
TLS options You cannot change this value from tls_type=rsa;direct-yes:
• TLS_Type: RSA is the only supported encryption type
for the connection.
• DIRECT: Yes is the only acceptable value because DI-
RECT through a proxy is the only supported connection
type.
Parent topic: SAP HANA Cloud, data lake database [page 99]
Related Information
Congure ODBC driver in DS Connection Manager for Linux [page 101]
4.1.5.2 Congure ODBC driver in DS Connection Manager
for Linux
Congure the ODBC driver for connecting to your SAP HANA Cloud, data lake database for Linux using the DS
Connection Manager.
The following examples show the steps to congure the ODBC driver for SAP HANA Cloud, data lake using
the SAP Data Services Connection Manager. For details about using the Connection Manager, see Using the
Connection Manager in the Administrator Guide.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 101

Example
The following sample conguration shows the options in the DS Connection Manager to congure the
ODBC driver for a DSN-less connection, using authentication method Basic. Options for which you supply
your own information are shown in <> in bold.
Specify one database type:
...list of database types...
15) SAP Hana Data Lake ODBC Driver
Specify database index #'1'
15
********************************
Configuration for SAP Hana Data Lake
********************************
The ODBC inst file is <path>/odbcinst.ini.
Specify the Driver Name:
<Driver_Name>
Specify the Driver:
/<path>/libdbodbc17.so
Specify the Host Name:
<url.hanacloud.ondemand.com>
Specify the Port:'443'
Specify the Authentication Method(1:Basic|2:X509):'1'
Specify the User Name:
HDLADMIN
Type database password:(no echo)
Retype database password:(no echo)
Testing connection...
Successfully added driver.
Press Enter to go back to the Main Menu.
Example
The following sample conguration shows the options in the DS Connection Manager to congure the
ODBC driver for a DSN-less connection, using authentication method X509. Options for which you supply
your own information are shown in in bold.
Specify one database type:
...list of database types...
15) SAP Hana Data Lake ODBC Driver
Specify database index #'1'
15
********************************
Configuration for SAP Hana Data Lake
********************************
The ODBC inst file is <path>/odbcinst.ini.
Specify the Driver Name:
<Driver_Name>
Specify the Driver:
/<path>/libdbodbc17.so
Specify the Host Name:
<url.hanacloud.ondemand.com>
Specify the Port:'443'
Specify the Authentication Method(1:Basic|2:X509):'1'
2
Specify the X509 Client Certificate:''
/<path>/drivers/<file name>.pem
Testing connection...
Successfully added driver.
Press Enter to go back to the Main Menu.
102
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Parent topic: SAP HANA Cloud, data lake database [page 99]
Related Information
Datastore options for SAP HANA Cloud, data lake [page 100]
4.1.6Snowake
Snowake provides a data warehouse that is built for the cloud.
After connecting to Snowake, you can do the following:
• Import tables
• Read or load Snowake tables in a data ow
• Create and load data into template tables
• Browse and import the tables located under dierent schemas (for example, Netezza)
• Preview data
• Push down base SQL functions and Snowake-specic SQL functions (see SAP Note 2212730 )
• Bulkload data (possible through AWS S3, Azure Cloud Storage, or Google Cloud Storage le location)
For instructions to create a target template table, see the Template tables section of the Designer Guide.
Using an ODBC driver to connect to Snowake on Windows [page 104]
Use the ODBC Drivers Selector utility bundled with SAP Data Services to congure Snowake as a
source for SAP Data Services.
Using an ODBC driver to connect to Snowake on Linux [page 105]
Use the DS Connection Manager to congure Snowake as a source for SAP Data Services.
Snowake datastore [page 111]
Options specic to Snowake when you create or edit a datastore.
Snowake source [page 112]
Option descriptions for using a Snowake database table as a source in a data ow.
Snowake data types [page 113]
SAP Data Services converts Snowake data types to the internal data types when it imports metadata
from a Snowake source or target into the repository.
Snowake target table options [page 114]
When you use a Snowake table as a target in SAP Data Services, complete the target options.
Parent topic: Cloud databases [page 84]
Related Information
Amazon Redshift database [page 85]
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 103
Azure SQL database [page 96]
Google BigQuery [page 98]
Google BigQuery ODBC [page 99]
SAP HANA Cloud, data lake database [page 99]
4.1.6.1 Using an ODBC driver to connect to Snowake on
Windows
Use the ODBC Drivers Selector utility bundled with SAP Data Services to congure Snowake as a source for
SAP Data Services.
For more information about the ODBC Drivers Selector utility, see Using the ODBC Drivers Selector for
Windows in the Administrator Guide.
Before you start to congure the connection to Snowake, make sure you meet the following prerequisites:
• You have correctly installed the Snowake ODBC Driver from the Snowake ocial website.
See the SAP Data Services Product Availability Matrix (PAM) for the latest client version that we support.
For more information about the Snowake ODBC driver, see the Snowake User Guide on the Snowake
website.
• You have database account credentials for the ODBC connection to Snowake.
To connect to Snowake through a DSN, perform the following steps:
1. Congure a Data Source Name (DSN).
1. Open ODBC Data Source Administrator from your Windows Create a Snowake database datastore
using the DSN you just created. For more information, see Start menu or click the ODBC Administrator
button in the Datastore Editor when you create the Snowake datastore in Data Services.
2. In the ODBC Administrator, open the System DSN tab and select the ODBC driver for Snowake that
you just installed.
3. Click Congure.
4. Enter the required information (for example, UserCreate a Snowake database datastore using
the DSN you just created. For more, Password, Server, Database, and so on) into the Snowake
Conguration Dialog window and click Save. For information about the connection parameters, see the
Snowake User Guide.
2. Creating a database datastore in the Designer Guide and Snowake datastore [page 111].
To connect to Snowake in server-based mode, perform the following steps:
1. Open the Data Services Designer and perform the steps in Creating a database datastore.
2. Select the correct values for the datastore options.
• Datastore Type: Database
• Database Type: Snowake
• Database Version: Select the latest compatible database version.
• Use data source name (DSN): Leave this option unchecked.
For descriptions of the remaining options for the Snowake datastore, see Common datastore options in
the Designer Guide and Snowake datastore [page 111].
3. Click Apply or OK.
104
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Parent topic: Snowake [page 103]
Related Information
Using an ODBC driver to connect to Snowake on Linux [page 105]
Snowake datastore [page 111]
Snowake source [page 112]
Snowake data types [page 113]
Snowake target table options [page 114]
4.1.6.2 Using an ODBC driver to connect to Snowake on
Linux
Use the DS Connection Manager to congure Snowake as a source for SAP Data Services.
Before you perform the steps in this topic, read Congure drivers with data source name (DSN) connections in
the Administrator Guide.
For details about using the Connection Manager, see Using the Connection Manager in the Administrator
Guide.
This topic contains the following information:
• Preparation [page 105]
• Connect to Snowake in server-based mode [page 106]
• Connect to Snowake through DSN [page 108]
Preparation
Before using an ODBC driver to connect to Snowake, make sure you perform the following required steps:
• Download and install the Snowake ODBC driver from the Snowake website.
See the SAP Data Services Product Availability Matrix (PAM)
for the latest supported client version.
For more information about the Snowake ODBC driver, see the Snowake User Guide on the Snowake
website.
• Obtain database account credentials for the ODBC connection to Snowake.
• Install the unixODBC tool (version V2.3 or higher) on your Linux system with the software package tool
‘yum’ for Redhat or ‘zypper’ for SuSE Linux.
• Set the following system environment variables:
• ODBCSYSINI=<Path where you place the $ODBCINI and $ODBCINST files>
• ODBCINI=<DSN configuration file>
• ODBCINST=<Driver configuration file>
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 105
For example:
export ODBCSYSINI=/home/dbcfg/
export ODBCINI=/home/dbcfg/odbc.ini
export ODBCINST=/home/dbcfg/odbcinst.ini
Data source sample in $ODBCINI:
[SF_DSN_EXAMPLE]
Driver=/usr/lib64/snowflake/odbc/lib/libSnowflake.so
UID=USER_EXAMPLE
PWD=******
SERVER=******.snowflakecomputing.com
PORT=443
DATABASE=DB_EXAMPLE
SCHEMA=
WAREHOUSE=
ROLE=AUTHENTICATOR=SNOWFLAKE_JWT
PRIV_KEY_FILE=/home/dbcfg/snowflake/rsa_key.p8
PRIV_KEY_FILE_PWD=******
Driver sample in $ODBCINST:
[SF_EXAMPLE]
driver=/usr/lib64/snowflake/odbc/lib/libSnowflake.so
unixODBC=/usr/lib64
Note
• The job engine internally uses the bundled le $LINK_DIR/bin/ds_odbc.ini to get to the ODBC
Driver Manager, so the le cannot be referenced by the system environment ODBCINI.
• The two les that are referenced by $ODBCINI and $ODBCINST must be accessible, readable, and
writable by SAP Data Services.
Connect to Snowake in server-based mode
To use an ODBC driver to connect to Snowake in server-based mode, do the following:
1. Navigate to the home directory for SAP Data Services.
2. Move into the subfolder bin and then source ./al_env.sh.
3. Run the Connection Manager utility: DSConnectionManager.sh.
For more information, see Using the Connection Manager in the Administrator Guide.
4. Congure the ODBC driver (enter 2).
***************************************************
SAP Data Services Connection Manager
***************************************************
------------------Start Menu------------------
Connection Manager is used to configure Data Sources or Drivers.
1: Configure Data Sources
2: Configure Drivers
q: Quit Program
Select one command:'1'
2
5. Add a new driver (enter a) or edit an existing driver (enter e).
------------------Main Menu-Configure Drivers------------------
106
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Drivers:
Index Database Type Version State Name
------ ------ ------ ------ ------
1: Sybase IQ 16 installed SAPIQ16
The command list:
Use Ctrl+B+Enter to go back to the main menu.
a: Add a new driver
e: Edit an existing driver
d: Delete an existing driver
s: Restart the Data Services Job Service and the EIM Adaptive Processing
Server
q: Quit to Start Menu
Select one command:
6. Specify a database type. In this example you would enter 10 for Snowake. Note that numbers may change
from release to release.
1) MySQL Driver for version [8.x, 5.7, 5.6, 5.5, 5.1, 5.0]
2) HANA Driver for version [2, 1]
3) Teradata Driver for version [17.10, 16.20, 16.00, 15.10, 15.00,
14.10, 14.00, 13.10, 13.0, 12]
4) Netezza Driver for version [11, 7, 6, 5, 4]
5) Sybase IQ Driver for version [15, 16]
6) Informix Driver for version [14, 12, 11]
7) DB2 UDB Driver for version [11, 10, 9]
8) Oracle Driver for version [19, 18, 12, 11, 10, 9]
9) SQL Anywhere Driver for version [17, 16, 12]
10) Snowflake Driver for version [3.x, 5.x]
11) Hive Server Driver for version [2.x.y, 2.1.2, 2.1.1]
12) PostgreSQL Driver for version [10.x, 12.x, 13.x, 14.x]
13) Google BigQuery Driver
14) Amazon Redshift Driver for version [8.x]
15) SAP Hana Data Lake ODBC Driver
7. Complete the datastore options.
1) Driver Version: <Version of the driver (3.x or 5.x)>
2) Driver Name: <Driver name that is used by Data Services and saved in
DSConfig.txt>
3) Driver: <Snowflake ODBC driver (see Preparation section above for more
information)>
4) Host Name: <Host system name>
5) Port: <Port number for the database server>
6) Database Name: <Database name>
7) Unix ODBC Lib Path: <unixODBC library path (see Preparation section
above for more information)>
8) User Name: <Database user name>
9) Authentication Method: <Authentication method (Basic or Key Pair)>
10) Password: <Password (required for Basic authentication)>
11) Private Key File: <Private key file generated by Openssl>
12) Private Key File Password: <Password used to encrypt the private key
file (required for Key Pair authentication)>
13) JWT timeout: <JSON-based web token timeout value (required for Key
Pair authentication)>
For more information about the Snowake security-related parameters, see the Snowake User Guide on
the Snowake website.
The following examples show the steps necessary to congure the ODBC driver for Snowake using the SAP
Data Services Connection Manager.
Basic authentication example:
********************************
Configuration for Snowflake
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 107

********************************
The ODBC inst file is <***/***>/odbcinst.ini.
Specify the Driver Version:'3.x'
5.x
Specify the Driver Name:
SF_EXAMPLE
Specify the Driver:
/usr/lib64/snowflake/odbc/lib/libSnowflake.so
Specify the Host Name:
******.snowflakecomputing.com
Specify the Port:'443'
Specify the Database:
DB_EXAMPLE
Specify the Unix ODBC Lib Path:’’
/usr/lib64
Specify the User Name:
USER_EXAMPLE
Specify the Authentication Method(1:Basic|2:Key Pair):'1'
1
Type database password:(no echo)
Retype database password:(no echo)
Testing connection...
Successfully added driver.
Press Enter to go back to the Main Menu.
Key Pair authentication example:
********************************
Configuration for Snowflake
********************************
The ODBC inst file is <***/***>/odbcinst.ini.
Specify the Driver Version:'3.x'
5.x
Specify the Driver Name:
SF_EXAMPLE
Specify the Driver:
/usr/lib64/snowflake/odbc/lib/libSnowflake.so
Specify the Host Name:
******.snowflakecomputing.com
Specify the Port:'443'
Specify the Database:
DB_EXAMPLE
Specify the Unix ODBC Lib Path:’’
/usr/lib64
Specify the User Name:
USER_EXAMPLE
Specify the Authentication Method(1:Basic|2:Key Pair):'1'
2
Specify the Private Key File:
/home/ssl/snowflake/rsa_key.p8
Specify the Private Key File Password:
Specify the JWT timeout(in seconds):'30'
Testing connection...
Successfully added driver.
Press Enter to go back to the Main Menu.
Connect to Snowake through DSN
To use an ODBC driver to connect to Snowake through DSN, do the following:
108
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

1. Navigate to the home directory for SAP Data Services.
2. Move into the subfolder bin and then source ./al_env.sh.
3. Run the Connection Manager utility: DSConnectionManager.sh.
For more information, see Using the Connection Manager in the Administrator Guide.
4. Congure the data source (enter 1).
***************************************************
SAP Data Services Connection Manager
***************************************************
------------------Start Menu------------------
Connection Manager is used to configure Data Sources or Drivers.
1: Configure Data Sources
2: Configure Drivers
q: Quit Program
Select one command:'1'
1
5. Add a new database source (enter
a
) or edit an existing database source (enter
e
).
------------------Main Menu-Configure Data Sources------------------
Data Sources:
Index Database Type Name
------ ------ ------
No database source is configured.
The command list:
Use Ctrl+B+Enter to go back to the main menu.
a: Add a new database source
e: Edit an existing database source
d: Delete an existing database source
r: Replicate an existing database source
s: Restart the Data Services Job Service and the EIM Adaptive Processing
Server
q: Quit to Start Menu
Select one command:
a
6. Specify a database type. In this example you would enter 18 for Snowake. Note that numbers may change
from release to release.
Specify one database type:
1) MySQL
2) Microsoft SQL Server via DataDirect
3) SAP HANA
4) IBM DB2 on iSeries or zSeries via DataDirect
5) Teradata
6) Netezza NPS
7) Sybase IQ
8) Sybase ASE
9) IBM Informix IDS
10) Attunity
11) SQL Anywhere
12) Vertica
13) Amazon Redshift
14) Apache Cassandra
15) Hive Server
16) Apache Impala
17) SAP Vora
18) Snowflake
19) PostgreSQL
20) Google BigQuery
21) SAP Hana Data Lake
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 109

7. Complete the remaining options.
1) DSN Name: <Data source name that will be shown in $ODBCINI>
2) User Name: <Database user name>
3) Password: <Password (required for Basic authentication)>
4) Unix ODBC Lib Path: <unixODBC library path (see Preparation section
above for more information)>
5) Driver Version: <Driver version>
6) Driver: <Snowflake ODBC driver (see Preparation section above for more
information)>
7) Host Name: <Host system name>
8) Port: <Port number for the database server>
9) Database Name: <Database name>
For more information about the Snowake security-related parameters, see the Snowake User Guide on
the Snowake website.
The following example shows the steps to congure a data source for Snowake using the SAP Data Services
Connection Manager.
********************************
Configuration for Snowflake
********************************
Specify the DSN name from the list or add a new one:
SF_DSN_EXAMPLE
Specify the User Name:
USER_EXAMPLE
Type database password:(no echo)
Retype database password:(no echo)
Specify the Unix ODBC Lib Path:
/usr/lib64
Specify the Driver Version:'3.x'
5.x
Specify the Driver:
/usr/lib64/snowflake/odbc/lib/libSnowflake.so
Specify the Host Name:
******.snowflakecomputing.com
Specify the Port:'443'
Specify the Database:
DB_EXAMPLE
Testing connection...
Successfully added driver.
Press Enter to go back to the Main Menu.
Note
After conguration, the information will be reected in the local le $ODBCINI and $LINK_DIR/bin/
ds_odbc.ini.
For steps to dene a database datastore, see Creating a database datastore in the Designer Guide.
For information about Snowake database datastore options, see Snowake datastore [page 111].
Parent topic: Snowake [page 103]
Related Information
Using an ODBC driver to connect to Snowake on Windows [page 104]
110
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Snowake datastore [page 111]
Snowake source [page 112]
Snowake data types [page 113]
Snowake target table options [page 114]
4.1.6.3 Snowake datastore
Options specic to Snowake when you create or edit a datastore.
For information about creating a database datastore and descriptions for common datastore options, see the
Designer Guide.
Snowake-specic datastore options
Option Description
Authentication Method
Authentication methods include:
• Basic (default): User and password authentication.
• Key Pair: Enhanced authentication security that uses a client key and
password (for encrypted version private keys only).
Note
The Key Pair authentication method is supported on server-based
Snowake (DSN-less) connections only.
Private Key File
The private key le.
Private Key File Password The password used to protect the private key le. A password is required for
encrypted version private keys only.
JWT Timeout (in seconds) JSON-based web token timeout value. The default is 30 seconds.
For more detailed information about key pair authentication, see the Snowake documentation.
Parent topic: Snowake [page 103]
Related Information
Using an ODBC driver to connect to Snowake on Windows [page 104]
Using an ODBC driver to connect to Snowake on Linux [page 105]
Snowake source [page 112]
Snowake data types [page 113]
Snowake target table options [page 114]
Creating a database datastore
Common datastore options
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 111

4.1.6.4 Snowake source
Option descriptions for using a Snowake database table as a source in a data ow.
When you use a Snowake table as a source, the software supports the following features:
• All Snowake data types
• SQL functions and snowake-specic SQL function
• Push-down ODBC generic functions
For more about push down functions, see SAP Note 2212730 , “SAP Data Services push-down operators,
functions, and transforms”. Also read about maximizing push-down operations in the Performance
Optimization Guide.
The following table lists source options when you use a Snowake table as a source:
Option
Description
Table name Name of the table that you added as a source to the data ow.
Table owner Owner that you entered when you created the Snowake table.
Datastore name Name of the Snowake datastore.
Database type Database type that you chose when you created the datastore. You cannot change
this option.
Table Schema Name of the table schema.
Performance settings
Option
Description
Join Rank Species the rank of the data le relative to other tables and
les joined in a data ow.
Enter a positive integer. The default value is 0.
The software joins sources with higher join ranks before join-
ing sources with lower join ranks.
If the data ow includes a Query transform, the join rank
specied in the Query transform overrides the Join Rank
specied in the File Format Editor.
For new jobs, specify the cache only in the Query transform
editor.
For more information about setting “Join rank”, see “Source-
based performance options” in the Performance Optimiza-
tion Guide.
112
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Option
Description
Cache Species whether the software reads the data from the
source and load it into memory or pageable cache.
• Yes: Always caches the source unless the source is the
outer-most source in a join. Yes is the default setting.
• No: Never caches the source.
If the data ow includes a Query transform, the cache set-
ting specied in the Query transform overrides the Cache
setting specied in the Format File Editor tab.
For new jobs, specify the cache only in the Query transform
editor.
For more information about caching, see “Using Caches” in
the Performance Optimization Guide.
Array fetch size
Indicates the number of rows retrieved in a single request
to a source database. The default value is 1000. Higher num-
bers reduce requests, lowering network trac, and possibly
improve performance. Maximum value is 5000.
Parent topic: Snowake [page 103]
Related Information
Using an ODBC driver to connect to Snowake on Windows [page 104]
Using an ODBC driver to connect to Snowake on Linux [page 105]
Snowake datastore [page 111]
Snowake data types [page 113]
Snowake target table options [page 114]
4.1.6.5 Snowake data types
SAP Data Services converts Snowake data types to the internal data types when it imports metadata from a
Snowake source or target into the repository.
The following table lists the internal data type that Data Services uses in place of the Snowake data type.
Snowake
data type Converts to Data Services data type Notes
byteint/tinyint decimal(38,0)
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 113
Snowake data type Converts to Data Services data type Notes
smallint decimal(38,0)
int/integer decimal(38,0)
bigint decimal(38,0)
number/numeric/decimal decimal Default of precision is 38.
oat double
double double
real double
varchar varchar
char varchar Default is 1 byte.
string/text varchar Default is 16 mbyte.
boolean int
binary blob
varbinary blob
datetime/timestamp datetime
date date
time time
semi-structure not supported VARIANT, OBJECT, ARRAY
If Data Services encounters a column that has an unsupported data type, it does not import the column.
However, you can congure Data Services to import unsupported data types by checking the Import
unsupported data types as VARCHAR of size option in the datastore editor dialog box.
Parent topic: Snowake [page 103]
Related Information
Using an ODBC driver to connect to Snowake on Windows [page 104]
Using an ODBC driver to connect to Snowake on Linux [page 105]
Snowake datastore [page 111]
Snowake source [page 112]
Snowake target table options [page 114]
4.1.6.6 Snowake target table options
When you use a Snowake table as a target in SAP Data Services, complete the target options.
The Snowake target supports the following features:
114
PUBLIC
Data Services Supplement for Big Data
Cloud computing services
• transactional loads
• load triggers, pre-load commands, and post-load commands
• bulk loading
After you add the Snowake table as a target in a data ow, open the Bulk loader tab and complete the options
as described in the following table.
Bulk loader tab
Option
Description
Bulk load Select to use bulk loading options to write the data.
Mode Select the mode for loading data in the target table:
• Append: Adds new records to the table.
Note
Append mode does not apply to template tables.
• Truncate: Deletes all existing records in the table, and
then adds new records.
Remote Storage
Utilize the remote storage method to copy the local data
le into the staging storage temporarily and then load it to
the target Snowake table. Both the staging local le and
the duplicated one in the staging storage can be cleaned
according to the setting to the bulk loader. Select the remote
storage method:
• Amazon S3
• Microsoft Azure
• Google Cloud Storage
File Location
Enter or select the corresponding Amazon S3, Microsoft
Azure, or Google Cloud Storage location le location. You
can enter a variable for this option.
Generate les only Enable to generate data les that you can use for bulk load-
ing.
When enabled, the software loads data into data les instead
of the target in the data ow. The software writes the data
les into the bulk loader directory specied in the datastore
denition.
If you do not specify a bulk loader directory, the
software writes the les to %DS_COMMON_DIR%/log/
BulkLoader/<filename> . Then you manually copy
the les to the Amazon S3, Microsoft Azure, or Google Cloud
Storage remote system.
The le name is
SFBL_<DatastoreName>_<DBname>_<SchemaNam
e>_<TableName>_***.dat, where <TableName> is
the name of the target table.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 115

Option Description
Clean up bulk loader directory after load Enable to delete all bulk load-oriented les from the bulk
load directory after the load is complete.
Complete the General settings as described in the following table:
Option
Description
Column comparison Species how the software maps the input columns to per-
sistent cache table columns.
• Compare by position: The software disregards the col-
umn names and maps source columns to target col-
umns by position.
• Compare by name: The software maps source columns
to target columns by name. Compare by name is the
default setting.
Number of loaders
Sets the number of threads to generate multiple data les
for a parallel load job. Enter a positive integer for the number
of loaders (threads).
Also complete error handling and transaction control options as described in the following topics in the
Reference Guide:
• Error Handling options
• Transaction control
Parent topic: Snowake [page 103]
Related Information
Using an ODBC driver to connect to Snowake on Windows [page 104]
Using an ODBC driver to connect to Snowake on Linux [page 105]
Snowake datastore [page 111]
Snowake source [page 112]
Snowake data types [page 113]
4.2 Cloud storages
Access various cloud storages through le location objects and gateways.
File location objects specify specic le transfer protocols so that SAP Data Services safely transfers data from
server to server.
116
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

For information about the SAP Big Data Services to access Hadoop in the cloud, see Supplement for Big Data
Services.
Amazon S3 [page 117]
Amazon Simple Storage Service (S3) is a product of Amazon Web Services that provides scalable
storage in the cloud.
Azure Blob Storage [page 123]
In SAP Data Services Designer, we refer to Azure Blob Storage as Azure Cloud Storage.
Azure Data Lake Storage [page 130]
Use an Azure Data Lake Storage le location object to download data from and upload data to your
Azure Data Lake Storage.
Google Cloud Storage le location [page 134]
A Google Cloud Storage (GCS) le location contains le transfer protocol information for moving large
data les, 10 MB and larger, between GCS and SAP Data Services.
Parent topic: Cloud computing services [page 84]
Related Information
Cloud databases [page 84]
Upload data to HDFS in the cloud [page 15]
4.2.1Amazon S3
Amazon Simple Storage Service (S3) is a product of Amazon Web Services that provides scalable storage in
the cloud.
Store large volumes of data in an Amazon S3 cloud storage account. Then use SAP Data Services to securely
download your data to a local directory. Congure a le location object to specify both your local directory and
your Amazon S3 directory.
The following table describes the Data Services built-in functions specic for Amazon S3.
Built-In Functions
Function
Description
load_from_s3_to_redshift
Moves data from Amazon S3 to Amazon Redshift.
copy_to_remote_system
Concatenates the remote directory that you specify in the
copy function with the information in the le location object
to form a full directory structure that includes subfolders.
copy_from_remote_system
Concatenates the remote directory that you specify in the
copy function with the information in the le location object
to form a full directory structure that includes subfolders.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 117

Function Description
load_from_fl_to_snowflake
Loads data from les in Azure Cloud Storage or Amazon S3
storage to a specied table in your Snowake cloud storage.
For descriptions of all built-in functions, see the “” section in the .
Amazon S3 le location protocol options [page 118]
When you congure a le location object for Amazon S3, complete all applicable options, especially the
options specic to Amazon S3.
Parent topic: Cloud storages [page 116]
Related Information
Azure Blob Storage [page 123]
Azure Data Lake Storage [page 130]
Google Cloud Storage le location [page 134]
4.2.1.1 Amazon S3 le location protocol options
When you congure a le location object for Amazon S3, complete all applicable options, especially the options
specic to Amazon S3.
Use a le location object to access data or upload data stored in your Amazon S3 account. To view options
common to all le location objects, see the Reference Guide. The following table describes the le location
options that are specic to the Amazon S3 protocol.
Restriction
You must have "s3:ListBucket" rights in order to view a list of buckets or a special bucket.
Option
Description
Access Key
Species the Amazon S3 identication input value.
Secret Key
Species the Amazon S3 authorization input value.
Region
Species the name of the region you're transferring data to
and from; for example, "South America (Sao Palo)".
118 PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Option Description
Server-Side Encryption Species the type of encryption method to use.
Amazon S3 uses a key to encrypt data at the object level
as it writes to disks in the data centers and then decrypts it
when the user accesses it:
• None
• Amazon S3-Managed Keys
• AWS KMS-Managed Keys
• Customer-Provided Keys
Data Services displays either one or none of the three re-
maining encryption options based on your selection here.
Encryption Algorithm Species the encryption algorithm to use to encode the
data. For example, AES256,aws:kms.
AWS KMS Key ID Species whether to create and manage encryption keys via
the Encryption Keys section in AWS IAW console.
Leave this option blank to use a default key that is unique to
you, the service you're using, and the region in which you're
working.
AWS KMS Encryption Context Species the encryption context of the data.
The value is a base64-encoded UTF-8 string holding JSON
with the encryption context key-value pairs.
Example
If the encryption context is {"fullName": "John Connor" },
you need base64-encoded: echo {"fullName":
"John Connor" } | openssl enc -base64
eyJmdWxsTmFtZSI6ICJKb2huIENvbm5vciIgf
SANCg==
Enter
eyJmdWxsTmFtZSI6ICJKb2huIENvbm5vciIgf
SANCg== in the encryption context option.
Customer Key Species the key.
Enter a value less-than or equal-to 256 bits.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 119

Option Description
Communication Protocol/Endpoint URL
Species the communication protocol you use with S3.
• http
• https
• Enter the endpoint URL.
If you choose to enter the endpoint URL, consider the follow-
ing information:
• If the endpoint URL is for http, and it contains a region,
ensure that you use a dash before the region.
Example
For example, enter http://s3-
<region>.amazonaws.com. For the U.S. East
(N.Virginia) region, the endpoint is http://
s3.amazonaws.com. Notice the period instead
of a dash.
• If the endpoint URL is for https, enter the endpoint URL
using either a dash or a period.
Example
Enter either https://s3-
<region>.amazonaws.com or https://
s3.<region>.amazonaws.com.
120
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Option Description
Request Timeout (ms) Species the time to wait before the system times out while
trying to complete the request to the specied Amazon S3
account in milliseconds (ms).
The default setting is 20,000 ms, which equals 20 seconds.
If you set Request Timeout (ms) to 0, the system uses
the HTTPRequestTimeout option setting (in seconds)
in the AL_Engine section of the DSConfig.txt le.
The HTTPRequestTimeout option has a default value of
2000 seconds.
The system logs the timeout value in the trace le when you
congure the job to log trace messages:
1. Enable the Transform property in the batch job trace
properties.
2. Set the Rest_Debug_Level option to 1 in the
AL_Engine section of the DSConfig.txt le.
For more information about job tracing, see the following
topics:
• Batch job trace properties in the Designer Guide.
• Executing batch jobs in the Management Console Guide.
Compression Type
Species the compression type to use.
The software compresses the les before uploading to S3
and decompresses the les after download from S3.
Note
When you upload a le to the Amazon S3 cloud
server using the copy_to_remote_system()
function and gzip compression, Data Services
adds a .gz le extension to the le name.
For example, sample.txt.gz. Read about the
copy_to_remote_system() built-in function in
the Reference Guide.
When you download the le, Data Services decom-
presses the le and removes the .gz extension from
the le name. For example, sample.txt.
Connection Retry Count
Species the number of times the software tries to upload or
download data before stopping the upload or download.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 121
Option Description
Batch size for uploading data, MB
Species the size of the data transfer to use for uploading
data to S3.
Data Services uses single-part uploads for les less than 5
MB in size, and multipart uploads for les larger than 5 MB.
Data Services limits the total upload batch size to 100 MB.
Batch size for downloading data, MB
Species the size of the data transfer Data Services uses to
download data from S3.
Number of threads
Species the number of upload threads and download
threads for transferring data to S3.
Storage Class
Species the S3 cloud storage class to use to restore les.
• STANDARD: Default storage class.
• REDUCED_REDUNDANCY: For noncritical, reproducible
data.
• STANDARD_IA: Stores object data redundantly across
multiple geographically separated availability zones.
• ONEZONE_IA: Stores object data in only one availability
zone.
Note
The GLACIER storage class isn't supported. Data Serv-
ices can't specify GLACIER storage class during object
creation.
For more information about the storage classes, see the Am-
azon AWS documentation.
Remote directory
Optional. Species the name of the directory for Amazon S3
to transfer les to and from.
Bucket
Species the name of the Amazon S3 bucket that contains
the data.
Local directory
Optional. Species the name of the local directory to use to
create the les. If you leave this eld empty, Data Services
uses the default Data Services workspace.
Proxy host, port, user name, password
Species proxy information when you use a proxy server.
For information about load_from_s3_to_reshift and other built-in functions, see the Reference Guide.
For more information about le location common options, see the Reference Guide.
Parent topic: Amazon S3 [page 117]
122
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Related Information
Amazon Redshift datastores [page 87]
4.2.2Azure Blob Storage
In SAP Data Services Designer, we refer to Azure Blob Storage as Azure Cloud Storage.
To access your Azure Blob Storage from Data Services, create an Azure Cloud Storage le location object.
The following table describes the Data Services built-in functions specic for Azure Cloud Storage.
Built-In Functions
Function
Description
load_from_azure_cloudstorage_to_synapse
Loads data from your Azure Cloud Storage to your Azure
Synapse Analytics workspace.
load_from_fl_to_snowflake
Loads data from les in Azure Cloud Storage or Amazon S3
storage to a specied table in your Snowake cloud storage.
For details about the built-in function, see the “Data Services Functions and Procedures” section in the
Reference Guide.
Azure Cloud Storage le location protocol [page 124]
Use a le location object to download data from or upload data to your Azure Blob Storage account.
Number of threads for Azure blobs [page 129]
The number of threads is the number of parallel uploaders or downloaders to be run simultaneously
when you upload or download blobs.
Parent topic: Cloud storages [page 116]
Related Information
Amazon S3 [page 117]
Azure Data Lake Storage [page 130]
Google Cloud Storage le location [page 134]
Azure Data Lake Storage [page 130]
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 123
4.2.2.1 Azure Cloud Storage le location protocol
Use a le location object to download data from or upload data to your Azure Blob Storage account.
The following table lists the le location object descriptions for the Azure Cloud Storage protocol. To view
options common to all le location objects, see the Reference Guide.
Note
To work with Azure Blob data in your Data Lake Storage account, see Azure Data Lake Storage [page 130].
Option
Description
Name
Enter a unique name for the le location object.
Protocol
Choose Azure Cloud Storage for the type of le transfer pro-
tocol.
Account Name
Enter the name for the Azure Data Lake Storage account.
Storage Type
Choose the storage type to access.
Data Services supports only one type for Azure Blob Stor-
age: Container.
Authorization Type
Choose the type of storage access signature (SAS) authori-
zation for Azure storage.
• Shared Key: Account level SAS for Azure Storage Serv-
ices. Accesses resources in one or more storage serv-
ices.
• File (Blob) Shared Access Signature: Service level SAS
for Azure blob storage services. Accesses a specic le
(blob).
Note
File (Blob) Shared Access Signature isn’t applicable
for Snowake bulk loading. Snowake bulk loading
requires le names that are generated randomly at
runtime. Therefore, select Shared Key or Container
Shared Access Signature for Snowake with bulk
loading
• Container Shared Access Signature: Service level SAS
for Azure container storage services. Accesses les
(blobs) in a container.
124
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Option Description
Shared Access Signature URL Enter the access URL that enables access to a specic le
(blob) or blobs in a container. Azure recommends that you
use HTTPS instead of HTTP.
Note
Applicable when you select File (Blob) Shared Access
Signature or Container Shared Access Signature for
Authorization Type.
To access blobs in a container,
include the following elements in
the URL: https://<storage_account_name>/
<container_name>/<signature value>
To access a specic le (blob),
include the following elements in
the URL: https://<storage_account_name>/
<container_name>/<file_name>/<signature
value>
Account Shared Key
Specify the Account Shared Key. Obtain a copy from the
Azure portal in the storage account information.
Note
For security, the software doesn’t export the account
shared key when you export a data ow or le location
object that species Azure Cloud Storage as the proto-
col.
Connection Retry Count Specify the number of times the computer tries to create a
connection with the remote server after a connection fails.
The default value is 10. The value can’t be zero.
After the specied number of retries, Data Services issues
an error message and stops the job.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 125

Option Description
Request Timeout (ms) Species the time to wait before the system times out while
trying to complete the request to the specied Azure Cloud
Storage in milliseconds (ms).
The default setting is 20,000 ms, which equals 20 seconds.
If you set Request Timeout (ms) to 0, the system uses
the HTTPRequestTimeout option setting (in seconds)
in the AL_Engine section of the DSConfig.txt le.
The HTTPRequestTimeout option has a default value of
2000 seconds.
The system logs the timeout value in the trace le when you
congure the job to log trace messages:
1. Enable the Transform property in the batch job trace
properties.
2. Set the Rest_Debug_Level option to 1 in the
AL_Engine section of the DSConfig.txt le.
For more information about job tracing, see the following
topics:
• Batch job trace properties in the Designer Guide.
• Executing batch jobs in the Management Console Guide.
Batch size for uploading data, MB
Specify the maximum size of a data block per request when
transferring data les. The limit is 100 MB.
Caution
Accept the default setting unless you’re an experienced
user with an understanding of your network capacities
in relation to bandwidth, network trac, and network
speed.
Batch size for downloading data, MB
Specify the maximum size of a data range to be downloaded
per request when transferring data les. The limit is 4 MB.
Caution
Accept the default setting unless you’re an experienced
user with an understanding of your network capacities
in relation to bandwidth, network trac, and network
speed.
126 PUBLIC
Data Services Supplement for Big Data
Cloud computing services
Option Description
Number of threads Specify the number of upload threads and download threads
for transferring data to Azure Cloud Storage. The default
value is 1.
When you set this parameter correctly, it could decrease the
download and upload time for blobs. For more information,
see Number of threads for Azure blobs [page 129].
Remote Path Prex
Optional. Specify the le path for the remote server, exclud-
ing the server name. You must have permission to this direc-
tory.
If you leave this option blank, the software assumes that the
remote path prex is the user home directory used for FTP.
When an associated le format is used as a reader in a
data ow, the software accesses the remote directory and
transfers a copy of the data le to the local directory for
processing.
When an associated le format is used as a loader in a data
ow, the software accesses the local directory location and
transfers a copy of the processed le to the remote direc-
tory.
Container type storage is a at le storage system and it
doesn’t support subfolders. However, Microsoft allows for-
ward slashes with names to form the remote path prex, and
a virtual folder in the container where you upload the les.
Example
You currently have a container for nance database les.
You want to create a virtual folder for each year. For
2016, you set the remote path prex to: 2016/. When
you use this le location, all of the les upload into the
virtual folder “2016”.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 127

Option Description
Local Directory
Specify the path of your local server directory for the le
upload or download.
Requirements for local server:
• must exist
• located where the Job Server resides
• you have appropriate permissions for this directory
For Azure Blob Storage location only: When an associated
le format is used as a reader in a data ow, the software
accesses the remote directory and transfers a copy of the
data le to the local directory for processing. Not applicable
for FTP.
When an associated le format is used as a loader in a data
ow, the software accesses the local directory location and
transfers a copy of the processed le to the remote direc-
tory.
Container
Specify the Azure container name for uploading or down-
loading blobs to your local directory.
If you specied the connection information, including ac-
count name, shared key, or proxy information, select the
Container eld. The software requests a list of existing con-
tainers from the server for the specic account. Either select
an existing container or specify a new one. When you specify
a new one, the software creates it when you run a job using
this le location object.
Proxy Host, Port, User Name, Password
Optional. Specify the proxy information when you use a
proxy server.
Parent topic: Azure Blob Storage [page 123]
Related Information
Number of threads for Azure blobs [page 129]
128
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

4.2.2.2 Number of threads for Azure blobs
The number of threads is the number of parallel uploaders or downloaders to be run simultaneously when you
upload or download blobs.
The Number of threads setting aects the eciency of downloading and uploading blobs to or from Azure
Cloud Storage.
Determine the number of threads
To determine the number of threads to set for the Azure le location object, base the number of threads on the
number of logical cores in the processor that you use.
Example thread settings
Processor logical cores Set Number of threads
8 8
16 16
The software automatically re-adjusts the number of threads based on the blob size you are uploading or
downloading. For example, when you upload or download a small le, the software may adjust to use fewer
numbers of threads and use the block or range size you specied in the Batch size for uploading data, MB or
Batch size for downloading data, MB options.
Upload Blob to an Azure container
When you upload a large le to an Azure container, the software may divide the le into the same number
of lists of blocks as the setting you have for Number of threads in the le location object. For example, when
the Number of threads is set to 16 for a large le upload, the software divides the le into 16 lists of blocks.
Additionally, each thread reads the blocks simultaneously from the local le and also uploads the blocks
simultaneously to the Azure container.
When all the blocks are successfully uploaded, the software sends a list of commit blocks to the Azure Blob
Service to commit the new blob.
If there is an upload failure, the software issues an error message. If they already existed before the upload
failure, the blobs in the Azure container stay intact.
When you set the number of threads correctly, you may see a decrease in upload time for large les.
Download Blob from an Azure container
When you download a large le from the Azure container to your local storage, the software may divide the
le into the Number of threads setting in the le location object. For example, when the Number of threads is
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 129
set to 16 for a large le download to your local container, the software divides the blobs into 16 lists of ranges.
Additionally, each thread downloads the ranges simultaneously from the Azure container and also writes the
ranges simultaneously to your local storage.
When your software downloads a blob from an Azure container, it creates a temporary le to hold all of the
threads. When all of the ranges are successfully downloaded, the software deletes the existing le from your
local storage if it existed, and renames the temporary le using the name of the le that was deleted from local
storage.
If there is a download failure, the software issues an error message. The existing data in local storage stays
intact if it existed before the download failure.
When you set the number of threads correctly, you may see a decrease in download time.
Parent topic: Azure Blob Storage [page 123]
Related Information
Azure Cloud Storage le location protocol [page 124]
4.2.3Azure Data Lake Storage
Use an Azure Data Lake Storage le location object to download data from and upload data to your Azure Data
Lake Storage.
For information about using variables and parameters to increase the exibility of jobs, work ows, and data
ows, see the Designer Guide.
Data Services provides a built-in function that loads data from your Azure Data Lake Storage to Azure Synapse
Analytics. The function is load_from_azure_datalakestore_to_synapse. For details about the built-in
function, see the Reference Guide.
Azure Data Lake Storage Gen1
Use Azure Data Lake Storage Gen1 for big data analytic processing. To create a le location object for Gen1,
make sure that you select Gen1 for the Version option.
Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 has all of the capabilities of Gen1 plus it’s built on Azure Blob storage. To create
a le location object for Gen2, make sure that you select Gen2 for the Version option.
130
PUBLIC
Data Services Supplement for Big Data
Cloud computing services
Azure Data Lake Storage le location object options
The following table describes the le location options for the Azure Data Lake Storage protocol. The table
combines options for Azure Data Lake Storage Gen1 and Gen2. The table contains a Version column that
indicates the applicable version for the option.
Note
For descriptions of the common le location options, see the Reference Guide.
Option
Description Version
Name Enter a unique name for the le location object. Both
Protocol Select Azure Data Lake Store.
Optionally, choose a substitution parameter.
Both
Version Select Gen1 or Gen2. Both
Authorization Type Select Shared Key, Service Principal or Azure Active
Directory.
Gen2
Account Shared Key When Authorization Type is set to Shared Key, enter
the account shared key that you obtain from your ad-
ministrator.
Gen2
Communication Protocol/Endpoint
URL
HTTPS or the endpoint URL. Gen2
Request Timeout (ms) Species the time to wait before the system times out
while trying to complete the request to the specied
Azure Data Lake Storage in milliseconds (ms).
The default setting is 20,000 ms, which equals 20
seconds. If you set Request Timeout (ms) to 0, the
system uses the HTTPRequestTimeout option
setting (in seconds) in the AL_Engine section of the
DSConfig.txt le. The HTTPRequestTimeout
option has a default value of 2000 seconds.
The system logs the timeout value in the trace le
when you congure the job to log trace messages:
1. Enable the Transform property in the batch job
trace properties.
2. Set the Rest_Debug_Level option to 1 in
the AL_Engine section of the DSConfig.txt
le.
For more information about job tracing, see the follow-
ing topics:
• Batch job trace properties in the Designer Guide.
• Executing batch jobs in the Management Console
Guide.
Both
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 131

Option Description Version
Connection Retry Count
Specify the number of times the computer tries to
create a connection with the remote server after a
connection fails.
The default value is 10. The value can’t be zero.
After the specied number of retries, Data Services
issues an error message and stops the job.
Both
Data Lake Store name
Name of the Azure Data Lake Storage to access.
Optionally use a substitution parameter.
Both
Service Principal ID
Obtain from your Azure Data Lake Storage adminis-
trator.
Both
Tenant ID
Obtain from your Azure Data Lake Storage adminis-
trator.
Both
Password
Obtain from your Azure Data Lake Storage adminis-
trator.
Both
Application ID
Obtain from your Azure Data Lake Storage adminis-
trator.
Gen2
Batch size for uploading data (MB)
Specify the maximum size of a data block to upload
per request when transferring data les.
• Gen1: Default value is 4 MB. Maximum value is 4
MB.
• Gen2: Default value is 10 MB. Maximum value is
100 MB.
Caution
Keep the default setting unless you’re an experi-
enced user with an understanding of your network
capacities in relation to bandwidth, network traf-
c, and network speed.
Both
132 PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Option Description Version
Batch size for downloading data
(MB)
Specify the maximum size of a data range to down-
load per request when transferring data les.
• Gen1: Default value is 4 MB. Maximum value is 4
MB.
• Gen2: Default value is 10 MB. Maximum value is
100 MB.
Caution
Keep the default setting unless you’re an experi-
enced user with an understanding of your network
capacities in relation to bandwidth, network traf-
c, and network speed.
Both
Number of threads
Number of parallel uploaders or downloaders to run
simultaneously. The default value is 1.
Tip
Setting the Number of threads to more than 1 can
reduce the time to upload Azure blob storage to
or download azure blob storage from Azure Data
Lake Storage.
Both
Remote path prex
Directory path for your les in the Azure Data Lake
Storage. Obtain the directory path from Azure Data
Lake Storage Properties.
Example
If the following is the directory path for your Azure
Data Lake Storage Properties:
adl://
<yourdatastoreName>.azuredatalake
store.net/<FolderName>/
<subFolderName>
Then the Remote path prex value is:
<FolderName>/<subFolderName>
Permission to access the directory is required.
Optionally use a substitution parameter.
Both
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 133

Option Description Version
Local directory
Path to the local directory for your local Data Lake
Storage data.
Permission to access this directory required.
Optionally use a substitution parameter.
Both
Container
If you specied the connection information, including
account name, shared key, or proxy information, se-
lect the Container eld. The software requests a list
of existing containers from the server for the specic
account. Either select an existing container or specify
a new one.
The name of the new one must be lower case and
have a length of more than 3 characters. When you
specify a new container, the software creates it when
you run a job using this le location object.
Both
Proxy Host, Port, User Name,
Password
Optional. Specify the proxy information when you use
a proxy server.
Both
Parent topic: Cloud storages [page 116]
Related Information
Amazon S3 [page 117]
Azure Blob Storage [page 123]
Google Cloud Storage le location [page 134]
4.2.4Google Cloud Storage le location
A Google Cloud Storage (GCS) le location contains le transfer protocol information for moving large data
les, 10 MB and larger, between GCS and SAP Data Services.
To work with your data from the Google Cloud Platform, create a le location object that contains your account
connection information and Google le transfer protocol. Use the le location in the following ways:
• As a source, select the GCS le location name in the Cloud Storage File Location object option in a Google
BigQuery datastore conguration.
• As a target, enter the location and le name for the GCS le location object in the Location or File location
option in a target editor.
134
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

You can also use the information from the GCS le location in the built-in function load_from_gcs_to_gbq,
to load data from your GCS to a Google BigQuery table. The function includes the Google BigQuery datastore,
which names the GCS le location. For details about the function, see the Reference Guide.
Uploading to GCS can use a large amount of local disk space. When you upload data to GCS in at les, XML
les, or JSON les, consider setting the number of rows in the target editor option Batch size (rows). The option
can reduce the amount of local disk space that Data Services uses to upload your data.
Note
If you set Location or File location to a location and le name for a non-GCS le location object, Data
Services ignores the setting in Batch size (rows).
To learn about le location objects, and to understand how SAP Data Services uses the le transfer protocol in
the le location conguration, see the Reference Guide.
GCS le location option descriptions [page 135]
Complete the options in a Google Cloud Storage (GCS) le location to be able to extract data from and
load data to your GCS account.
Decrease local disk usage when uploading [page 141]
Decrease the local disk space used when SAP Data Services uploads a large le of generated data to
your Google Cloud Storage (GCS) account.
Parent topic: Cloud storages [page 116]
Related Information
Amazon S3 [page 117]
Azure Blob Storage [page 123]
Azure Data Lake Storage [page 130]
4.2.4.1 GCS le location option descriptions
Complete the options in a Google Cloud Storage (GCS) le location to be able to extract data from and load
data to your GCS account.
The GCS le location contains connection and access information for your GCS account. The following table
lists the le location object descriptions for the Google Cloud Storage le location. For descriptions of common
options, and for more information about le location objects, see the Reference Guide.
GCS le location option descriptions
Option
Description
Name Species a unique name for the le location object.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 135
Option Description
Protocol Species the type of le transfer protocol.
Select Google Cloud Storage.
Project Species the Google project name to access.
Upload URL Species the URL for uploading data to GCS. Accept
the default, which is https://www.googleapis.com/
upload/storage/v1.
Download URL Species the URL for extracting data from GCS. Accept
the default, which is https://www.googleapis.com/
storage/v1.
Authentication Server URL
Species the Google server URL plus the name of the Web
access service provider, which is OAuth 2.0.
Accept the default, which is https://
accounts.google.com/o/oauth2/token.
Authentication Access Scope
Species the specic type of data access permission.
• Read-only: Access for reading data, including listing
buckets.
• Read-write: Access for reading and changing data. Not
applicable for metadata like access control lists (ACLs).
• Full-control: Access with full control over data, including
the ability to modify ACLs.
• Cloud-platform.read-only: Access for viewing your
data across Google Cloud Platform services. For
Google Cloud Storage, this option is the same as
devstorage.read-only.
• Cloud-platform: Access for viewing and managing
data across all Google Cloud Platform services. For
Google Cloud Storage, this option is the same as
devstorage.full-control. Cloud-platform: is
the default setting.
OAuth Mechanism
Species the authentication mechanism.
• Service Authentication (default): Data Services holds
the credentials of a service account to complete au-
thentication.
• User Authentication: Data Services obtains credentials
from the end user. If you don't have a refresh token, you
must sign into Google to complete the authentication.
You can also use an existing refresh token.
When you specify User Authentication, you must also
populate Client ID, Client Secret, and Refresh Token.
136 PUBLIC
Data Services Supplement for Big Data
Cloud computing services
Option Description
Service Account Email Address
Species the email address from your Google project. This
email is the same as the service account email address that
you enter into the applicable Google BigQuery datastore.
Note
Obtain the email address when you sign in to your Goo-
gle project.
Service Account Private Key
Species the P12 or JSON le you generated from your Goo-
gle project and stored locally.
Note
Log in to your Google project and select to generate the
private key le in either P12 or JSON format, and save
the le to your local computer.
Click Browse and open the location where you saved the le.
Select the .p12 or .JSON le and click Open.
Service Account Signature Algorithm
Species the algorithm type that Data Services uses to sign
JSON Web tokens.
Accept the default, which is SHA256withRSA.
Data Services uses this value, along with your service ac-
count private key, to obtain an access token from the Au-
thentication Server.
Substitute Access Email Address
Optional, for Google BigQuery. Enter the substitute email
address from your Google BigQuery datastore.
Client ID Species the OAuth client ID for Data Services. To get the
client ID, go to the Google API Console.
For more detailed instructions, see the Google documenta-
tion.
Client Secret
Species the OAuth client secret for Data Services. To get
the client secret, go to the Google API Console.
For more detailed instructions, see the Google documenta-
tion.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 137

Option Description
Refresh Token When OAuth mechanism is set to User Authentication, speci-
es the refresh token that is required for the Google Cloud
Storage le location connection.
To enter an existing refresh token, do the following:
1. Click the ellipsis (…) next to the Refresh Token eld.
2. In the Get Refresh Token window, select Refresh Token.
3. Click OK. The refresh token appears (masked for pri-
vacy and security reasons) in the Refresh Token eld.
To generate a new refresh token, enter an authorization
code.
1. Click the ellipsis (…) next to the Refresh Token eld.
2. In the Get Refresh Token window, select Authorization
Code.
3. Enter an authorization code.
To get an authorization code, follow the in-
structions in the Google documentation (https://
developers.google.com/identity/protocols/oauth2/na-
tive-app#step-2:-send-a-request-to-googles-oauth-2.0-
server
).
4. Click OK. A new refresh token is generated and ap-
pears (masked for privacy and security reasons) in the
Refresh Token eld.
Request Timeout (ms)
Species the time to wait before the system times out while
trying to complete the request to the specied Google Cloud
Storage in milliseconds (ms).
The default setting is 20,000 ms, which equals 20 seconds.
If you set Request Timeout (ms) to 0, the system uses
the HTTPRequestTimeout option setting (in seconds)
in the AL_Engine section of the DSConfig.txt le.
The HTTPRequestTimeout option has a default value of
2000 seconds.
The system logs the timeout value in the trace le when you
congure the job to log trace messages:
1. Enable the Transform property in the batch job trace
properties.
2. Set the Rest_Debug_Level option to 1 in the
AL_Engine section of the DSConfig.txt le.
For more information about job tracing, see the following
topics:
• Batch job trace properties in the Designer Guide.
• Executing batch jobs in the Management Console Guide.
138
PUBLIC
Data Services Supplement for Big Data
Cloud computing services
Option Description
Web Service URL Species the Data Services Web Services server URL that
the data ow uses to access the Web server.
Compression Type
Species the type of compression to use.
• None: Doesn't use compression.
• gzip: Enables you to upload gzip les to GCS.
Note
If you set the Batch size (rows) option to a non-
zero positive integer, Data Services ignores the
Compression Type of gzip. Batch size (rows) is in
the target le format editor. Applicable only for at
les, XML les, and JSON les.
Connection Retry Count
Species the number of times Data Services tries to create
a connection with the remote server after the initial connec-
tion attempt fails.
The default value is 10. The value can't be zero.
After the specied number of retries, Data Services issues
an error notication and stops the job.
Batch size for uploading data, MB
Species the maximum size for a block of data to upload per
request.
The limit is 5 TB.
For each request, Data Services uploads a block of data from
the local temporary le to your GCS account. The block of
data is in the specied size.
Batch size for downloading data, MB
Species the maximum size for a block of data to download
per request.
The limit is 5 TB.
For each request, Data Services downloads a block of data in
the specied size from GCS to your local le.
Number of threads
Species the number of threads to run in parallel when
transferring data to GCS.
Enter a number from 1 through 30. The default is 1.
Processing with multiple threads can increase job perform-
ance.
If you enter any number outside of 1 through 30, Data Serv-
ices automatically adjusts the number at runtime. For exam-
ple, Data Services changes a setting of 50 to 30 at runtime.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 139

Option Description
Bucket
Species the GCS bucket name, which is the name of the
basic container that holds your data in GCS.
Select a bucket name from the list.
Create a new bucket by entering a name that doesn't exist
in your Google account. When Google doesn't nd a bucket
by that name, it creates the bucket when you upload data to
your GCS account.
When you create a new bucket, also select a region in the
Region (for new bucket only) option.
Region (for new bucket only)
Select a region for the specied bucket. Applicable only
when you enter a new bucket name for Bucket. If you select
an existing bucket, Data Services ignores the region selec-
tion.
Remote Path Prex
Species the location of the Google Cloud Storage bucket.
To enter a folder structure, ensure that the path prex ends
with a forward slash (/). For example, test_folder1/
folder2/. You must have permission to this directory.
If you leave this option blank, Data Services assumes that
your GCS bucket is in the home directory of your le transfer
protocol.
Source: If source is an associated le format, Data Services
accesses the remote directory and transfers a copy of the
data le to the local directory for processing.
Target: If target is an associated le format, Data Services
accesses the local directory and transfers a copy of the gen-
erated le to the remote directory.
140
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Option Description
Local Directory
Species the le path of the local server that you use for this
le location object.
The local server directory is located where the Job Server
resides. You must have permission to this directory.
Note
If this option is blank, Data Services assumes the direc-
tory %DS_COMMON_DIR%/workspace as the default
directory.
Source: If source is an associated le format, Data Services
accesses the remote directory and transfers a copy of the
data le to the local directory for processing.
Target: If target is an associated le format, Data Services
accesses the local directory and transfers a copy of the gen-
erated le to the remote directory.
Proxy Host, Port, User Name, Password
Optional. Species the proxy server information when you use
a proxy server.
Parent topic: Google Cloud Storage le location [page 134]
Related Information
Decrease local disk usage when uploading [page 141]
4.2.4.2 Decrease local disk usage when uploading
Decrease the local disk space used when SAP Data Services uploads a large le of generated data to your
Google Cloud Storage (GCS) account.
Data Services uses the le transfer protocol in a GCS le location to load large amounts of data to your GCS
account. Large size is 10 MB or more. During the load process, Data Services rst loads all records to a local
temporary le before it uploads data to your GCS account. The rst load process uses local disk space equal to
the size of the le.
Decrease local disk space usage by using the option Batch size (rows). The option limits the load to a set
number of rows. Data Services loads the set number of rows in batches to the local le, which decreases the
local disk space used.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 141
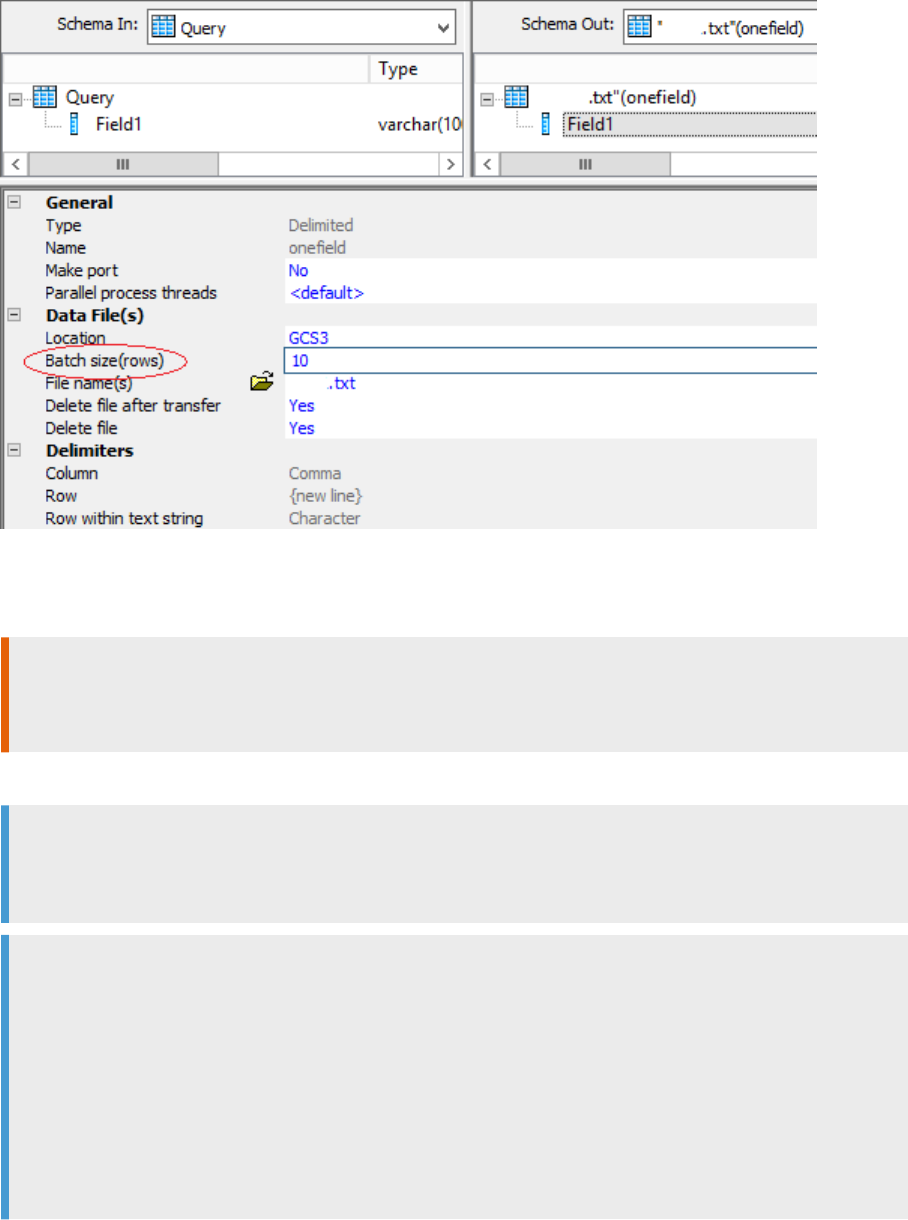
Find the Batch size (rows) option in the target editor for at les, XML les, and JSON les. The following gure
shows the setting in the target editor for a at le:
When you set Batch size (rows) to 1 or more, Data Services uploads the batch rows in a single thread.
Therefore, Data Services ignores the setting in Parallel process threads. Additionally, Data Services does not
use compression, so it ignores a setting of gzip for Compression type in the GCS le location.
Caution
If you set Location or File location to a location and le name for a non-GCS le location object, Data
Services ignores the setting in Batch size (rows).
Disable Batch size (rows) by leaving the default setting of zero (0).
Note
The following example uses simple row and le sizes for illustration. Sizes may not realistically reect actual
data.
Example
Your generated le contains 10,000 rows and is about 10 MB. You set Batch size (rows) to 2000, which is 2
MB. Then you execute the job.
Data Services loads the rst 2000 rows to the local temporary le, using 2 MB of local disk space. After all
2000 rows nish loading, it uploads the 2000 rows from the local le to your GCS account. When it nishes
loading the 2000 rows to GCS, Data Services deletes the rows in the local le, which frees up 2 MB of
local disk storage. Data Services performs this process ve times for a total of 10,000 rows. The maximum
amount of local disk storage the process uses is 2 MB, compared to 10 MB without using the Batch size
(rows) option.
142
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Row batch size considerations [page 143]
Consider your environment and your data before you set the Batch size (rows) option.
Parent topic: Google Cloud Storage le location [page 134]
Related Information
GCS le location option descriptions [page 135]
4.2.4.2.1 Row batch size considerations
Consider your environment and your data before you set the Batch size (rows) option.
Before you set the option Batch size (rows) in the target le format editor, consider your goals. Also keep in
mind the size of one row of data. When each row contains many elds, the record size may determine the
number of rows to set.
The following table describes scenarios for three specic goals.
Goal and action scenarios
Goal
Action
You want the best performance regardless of the local disk
space the process uses.
Set Batch size (rows) to zero (0) to disable it, and set the
performance optimization settings in the GCS le location.
You achieve the best performance when you use the settings
in the le location object. However, the upload uses local
disk space equal to the size of the entire le.
You want to conserve local disk space, but you’re also inter-
ested in optimizing performance.
Use Batch size (rows).
Run test jobs to determine the setting that best meets your
goal.
• A higher setting uses more local disk space, but still less
space than without using the option.
• A lower setting uses less local disk space than without
the option.
You don't want to use more than a specic amount of local
disk space.
Work backwards to determine the setting for Batch size
(rows), beginning with the maximum amount of disk space
to use for the upload transaction.
Data Services Supplement for Big Data
Cloud computing services
PUBLIC 143

Examples
Example
Best performance
You plan to execute the job that uploads data to your GCS account over night when there isn’t a large
demand for local disk space. Therefore, you leave the Batch size (rows) option set to the default of zero (0).
Then you congure the GCS le location and set the following options for optimized performance:
• Compression Type
• Batch size for uploading data, MB
• Number of threads
Note
The settings in the GCS le location do not aect loading the data to the local temporary le, but they
aect loading from the temporary le to GCS.
Example
Compare settings
The following table compares option settings for Batch size (rows) and how it aects local disk storage and
performance. For this example, generated data contains 10,000 rows and the total size is 10 MB.
Compare settings
Settings
Example 1 Example 2
Batch size (rows) 5,000 1,000
Total disk space 5 MB 1 MB
Number of connections 2 10
Performance (up ↑ or down ↓) ↑ ↓
Example
Maximum batch size
You design the Data Services data ow to add additional columns to each row of data, making each row
longer and larger than before processing. You base the number of rows to set for Batch size (rows) using a
maximum disk space.
• Maximum disk space to use is 2 MB
• Convert MB to Bytes: 2 MB = 2,097,152 Bytes
• Generated row size is 1,398 bytes
• 2,097,152 ÷ 1,398 = 1,500
• Set Batch size (rows) to 1500
If the generated data contains 10,000 rows, Data Services connects to GCS a total of seven times, with the
last batch containing only 500 rows.
144
PUBLIC
Data Services Supplement for Big Data
Cloud computing services

Important Disclaimers and Legal Information
Hyperlinks
Some links are classied by an icon and/or a mouseover text. These links provide additional information.
About the icons:
• Links with the icon
: You are entering a Web site that is not hosted by SAP. By using such links, you agree (unless expressly stated otherwise in your
agreements with SAP) to this:
• The content of the linked-to site is not SAP documentation. You may not infer any product claims against SAP based on this information.
• SAP does not agree or disagree with the content on the linked-to site, nor does SAP warrant the availability and correctness. SAP shall not be liable for any
damages caused by the use of such content unless damages have been caused by SAP's gross negligence or willful misconduct.
• Links with the icon : You are leaving the documentation for that particular SAP product or service and are entering an SAP-hosted Web site. By using
such links, you agree that (unless expressly stated otherwise in your agreements with SAP) you may not infer any product claims against SAP based on this
information.
Videos Hosted on External Platforms
Some videos may point to third-party video hosting platforms. SAP cannot guarantee the future availability of videos stored on these platforms. Furthermore, any
advertisements or other content hosted on these platforms (for example, suggested videos or by navigating to other videos hosted on the same site), are not within
the control or responsibility of SAP.
Beta and Other Experimental Features
Experimental features are not part of the ocially delivered scope that SAP guarantees for future releases. This means that experimental features may be changed by
SAP at any time for any reason without notice. Experimental features are not for productive use. You may not demonstrate, test, examine, evaluate or otherwise use
the experimental features in a live operating environment or with data that has not been suciently backed up.
The purpose of experimental features is to get feedback early on, allowing customers and partners to inuence the future product accordingly. By providing your
feedback (e.g. in the SAP Community), you accept that intellectual property rights of the contributions or derivative works shall remain the exclusive property of SAP.
Example Code
Any software coding and/or code snippets are examples. They are not for productive use. The example code is only intended to better explain and visualize the syntax
and phrasing rules. SAP does not warrant the correctness and completeness of the example code. SAP shall not be liable for errors or damages caused by the use of
example code unless damages have been caused by SAP's gross negligence or willful misconduct.
Bias-Free Language
SAP supports a culture of diversity and inclusion. Whenever possible, we use unbiased language in our documentation to refer to people of all cultures, ethnicities,
genders, and abilities.
146
PUBLIC
Data Services Supplement for Big Data
Important Disclaimers and Legal Information
Data Services Supplement for Big Data
Important Disclaimers and Legal Information
PUBLIC 147

www.sap.com/contactsap
© 2024 SAP SE or an SAP aliate company. All rights reserved.
No part of this publication may be reproduced or transmitted in any form
or for any purpose without the express permission of SAP SE or an SAP
aliate company. The information contained herein may be changed
without prior notice.
Some software products marketed by SAP SE and its distributors
contain proprietary software components of other software vendors.
National product specications may vary.
These materials are provided by SAP SE or an SAP aliate company for
informational purposes only, without representation or warranty of any
kind, and SAP or its aliated companies shall not be liable for errors or
omissions with respect to the materials. The only warranties for SAP or
SAP aliate company products and services are those that are set forth
in the express warranty statements accompanying such products and
services, if any. Nothing herein should be construed as constituting an
additional warranty.
SAP and other SAP products and services mentioned herein as well as
their respective logos are trademarks or registered trademarks of SAP
SE (or an SAP aliate company) in Germany and other countries. All
other product and service names mentioned are the trademarks of their
respective companies.
Please see https://www.sap.com/about/legal/trademark.html for
additional trademark information and notices.
THE BEST RUN
