
AudioPaLM: A Large Language Model That Can
Speak and Listen
Paul K. Rubenstein
∗
Chulayuth Asawaroengchai
∗
Duc Dung Nguyen
∗
Ankur Bapna Zalán Borsos Félix de Chaumont Quitry Peter Chen
Dalia El Badawy Wei Han Eugene Kharitonov Hannah Muckenhirn
Dirk Padfield James Qin Danny Rozenberg Tara Sainath Johan Schalkwyk
Matt Sharifi Michelle Tadmor Ramanovich Marco Tagliasacchi Alexandru Tudor
Mihajlo Velimirovi
´
c Damien Vincent Jiahui Yu Yongqiang Wang
Vicky Zayats Neil Zeghidour Yu Zhang Zhishuai Zhang Lukas Zilka
Christian Frank
Google
Abstract
We introduce AudioPaLM, a large language model for speech understanding and
generation. AudioPaLM fuses text-based and speech-based language models,
PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified
multimodal architecture that can process and generate text and speech with applica-
tions including speech recognition and speech-to-speech translation. AudioPaLM
inherits the capability to preserve paralinguistic information such as speaker iden-
tity and intonation from AudioLM and the linguistic knowledge present only in
text large language models such as PaLM-2. We demonstrate that initializing
AudioPaLM with the weights of a text-only large language model improves speech
processing, successfully leveraging the larger quantity of text training data used
in pretraining to assist with the speech tasks. The resulting model significantly
outperforms existing systems for speech translation tasks and has the ability to
perform zero-shot speech-to-text translation for many languages for which in-
put/target language combinations were not seen in training. AudioPaLM also
demonstrates features of audio language models, such as transferring a voice across
languages based on a short spoken prompt. We release examples of our method at:
https://google-research.github.io/seanet/audiopalm/examples.
1 Introduction
Large language models (LLMs) [Brown et al., 2020, Rae et al., 2021, Chowdhery et al., 2022] excel
at generating text for tasks that require the modeling of complex interactions as well as knowledge
retrieval, such as open-domain question answering or few-shot machine translation [Anil et al., 2023].
The remarkable generative abilities of the underlying system — a Transformer [Vaswani et al., 2017]
trained to predict sequences of discrete tokens — have been subsequently extended to continuous,
natural signals with images [Yu et al., 2022b] or audio waveforms [Lakhotia et al., 2021, Kreuk et al.,
2022, Wang et al., 2023] being converted into a stream of discrete units through a lossy compression
algorithm and then modeled in a sequential fashion as would be text.
In the context of audio generation, the AudioLM framework [Borsos et al., 2022] has introduced
a hierarchical approach which combines two types of audio tokens, with high-level coarse tokens
extracted from self-supervised embeddings [Chung et al., 2021] being used to condition the generation
of lower-level codes of a neural codec [Zeghidour et al., 2021]. This general framework, which makes
∗
Authors have contributed equally to this work.
arXiv:2306.12925v1 [cs.CL] 22 Jun 2023
little assumptions about the nature of the modeled audio signals, has been used to generate speech and
music [Kharitonov et al., 2023, Agostinelli et al., 2023, Donahue et al., 2023]. In the particular case
of text-to-music [Agostinelli et al., 2023] or text-to-speech [Kharitonov et al., 2023], a Transformer
model takes text tokens as inputs and generates audio tokens, such that text and audio vocabularies
do not interact with each other. Such models could naturally be converted into, respectively, music
captioning and speech recognition systems by swapping their inputs and outputs. Following this
observation, combining text and audio vocabularies into a multimodal, single vocabulary would allow
for training a single model in both directions.
In this work, we introduce AudioPaLM, a multimodal generative model of speech and text. At the
heart of AudioPaLM is a joint vocabulary that can represent speech and text with a limited number
of discrete tokens which, combined with an elementary markup description of tasks, allows training
a single decoder-only model on a mixture of tasks that involve arbitrarily interleaved speech and
text. This includes speech recognition, text-to-speech synthesis, and speech-to-speech translation,
unifying tasks that are traditionally solved by heterogeneous models into a single architecture and
training run. Moreover, as the underlying architecture of AudioPaLM is a large Transformer model,
we can initialize its weights with those of a large language model pretrained on text which allow
it to benefit from the linguistic and common sense knowledge of models such as PaLM [Chowdhery
et al., 2022] or PaLM 2 [Anil et al., 2023]. In particular, we show in Section 5.4.8 how the model’s
translation capability is derived from the translation capability of the underlying text model. The
contributions of this work are:
•
We present a unified speech-text LLM, capable of consuming and producing both speech
and text, and leveraging the existing capabilities of PaLM Chowdhery et al. [2022] and
PaLM-2 [Anil et al., 2023] coming from text-only pretraining.
•
This unified approach across modalities allows training AudioPaLM on a mixture of tasks
such as Automatic Speech Recognition (ASR), Automatic Speech Translation (AST) and
Speech-to-Speech Translation (S2ST), achieving state of the art results on AST and S2ST
benchmarks, and competitive performance on ASR benchmarks.
•
Leveraging AudioLM’s audio prompting [Borsos et al., 2022], our model performs S2ST
with voice transfer of unseen speakers, surpassing existing methods in terms of speech
quality and voice preservation, as measured by both objective and subjective evaluations.
•
Our model exhibits zero-shot capabilities, performing AST with speech input/target language
combinations that were not seen in training.
The remainder of this paper is organized as follows: in Section 2 we discuss the relation to existing
work. In Section 3 we describe our method. In Section 4 we provide details about the data we use,
and other technical details as a prelude to the experiments. In Section 5 we present our experimental
results including a series of ablations to determine the influence of various design choices. We
conclude in Section 6.
2 Related work
2.1 Multimodal fusion
Encoder-based models are used to learn features which can be used for downstream tasks. By learning
joint representations of both modalities together, the goal is that in addition to the learned features be-
ing richer than they would be with each modality treated separately, they are aligned with one another,
improving their performance when used for inter-modality tasks. Such approaches have been applied
in audio [Chen et al., 2022c, Bapna et al., 2022, Zhang et al., 2023a] and in vision [Chen et al., 2020,
Gan et al., 2020, Fu et al., 2021] as well as combining both audio and video inputs [Shi et al., 2022].
Similar to BERT [Devlin et al., 2018], such encoders may be trained with a masked language model
objective for both the multimodal setting as in previously mentioned works and for the unimodal
setting [Baevski et al., 2020, Hsu et al., 2021, Chiu et al., 2022]. They may alternatively be trained in
a contrastive manner [Radford et al., 2021, Yuan et al., 2021, Yu et al., 2022a] resulting in separate
encoders for each modality with each informed by the other due to the contrastive objective.
A line of work on multimodal encoder-decoder models (also known as Vision Language Models in
the vision literature) has sought to fuse text-decoders with advances in non-text encoder models.
2
Examples include Flamingo [Alayrac et al., 2022] and PaLI [Chen et al., 2022b] in the vision domain,
and Whisper [Radford et al., 2022] in the audio domain. The general idea of these approaches is to
take an audio or vision encoder and a text decoder and to combine them, either with adapter layers as
in Flamingo and Whisper, or by merging via a separate encoder as in PaLI.
Both PaLI and Flamingo use pretrained components. The advantage of this is that individual
components can be frozen while finetuning the model on multimodal data (Whisper does not use a
pretrained encoder or decoder and so does not freeze individual components). The disadvantage is
that such models are constrained to only output text, since the decoder is text-only. In contrast, our
proposed approach results in a decoder-only model which models sequences of arbitrary audio and
text tokens. This is similar to the approach taken by Wang et al. [2022] except that we use a single
decoder-only model and all audio seen by the model is tokenized, whereas Wang et al. [2022] use an
encoder-decoder architecture and use continuous inputs and tokenized outputs for images.
2.2 Generating audio with language models
Recent work [Lakhotia et al., 2021, Wang et al., 2023] has explored generating speech by modeling
discretized representations as target tokens of an autoregressive Transformer [Vaswani et al., 2017]
network. Such discrete tokens can be extracted from self-supervised speech representations [Oord
et al., 2018, Baevski et al., 2020, Hsu et al., 2021, Chung et al., 2021], modeling long-term patterns
in audio sequences while providing limited reconstruction quality, or from a neural codec [Zeghidour
et al., 2021, Défossez et al., 2022], providing high-fidelity reconstruction but with less temporal
structure. AudioLM [Borsos et al., 2022] addresses this dichotomy by introducing a hierarchical
approach, where a first stage produces “semantic” tokens from a self-supervised w2v-BERT sys-
tem [Chung et al., 2021], which a second stage then uses as conditioning to generate the “acoustic”
tokens of a SoundStream [Zeghidour et al., 2021] neural codec. This joint modeling of semantic and
acoustic tokens allows the model to learn linguistic structure from the syntactic to the lexical and
phonetic levels from speech-only corpora, without any textual guidance, while generating realistic
speech from arbitrary speakers and in diverse acoustic conditions.
SPEAR-TTS [Kharitonov et al., 2023] combines the decoder-only generator of AudioLM with a text
encoder, such that the model can perform text-to-speech synthesis. By leveraging pretraining and
backtranslation [Sennrich et al., 2016], SPEAR-TTS can be trained with only 15 minutes of labeled
speech. The ability of this model to learn a mapping between text and semantic tokens in such a
low-data regime suggests that these representations are very close, yet the model’s encoder-decoder
architecture specifically ingests text and outputs audio, such that both vocabulary of tokens (text
and semantic) are disjoint and modeled separately. SpeechLM [Hassid et al., 2023] also exploits the
similarity between text and semantic tokens by initializing a decoder-only audio generator with the
weights of a pretrained text-based language model. While this allows some transfer of knowledge from
text-to-speech modeling, the resulting architecture is not multimodal: semantic tokens replace the text
vocabulary —rather than extending it— and the model is finetuned on speech-only data. AudioPaLM
bridges these gaps and combines semantic tokens and text into an extended, multimodal set of tokens
used interchangeably as inputs and outputs, such that text-only language model pretraining can be
used to initialize a decoder-only model that can then be finetuned on a mixture of tasks that map
freely between speech and text (e.g. speech-to-text, text-to-speech or speech-to-speech).
2.3 Speech-to-speech translation
The field of speech-to-speech translation (S2ST) focuses on converting spoken language from one
language to another, facilitating communication between individuals who speak different languages.
Conventional automatic speech-to-speech translation systems are typically composed of a cascade of
three components: automatic speech recognition (ASR), text-to-text machine translation (MT), and
text-to-speech (TTS) synthesis [Lavie et al., 1997, Wahlster, 2000, Nakamura et al., 2006]. However,
these cascade-based approaches primarily focus on the text and may overlook important aspects such
as para-linguistic features, computational efficiency, compound errors, and the accurate handling of
proper names, nouns, and non-verbal communication that do not require translation.
Direct speech-to-speech translation systems [Jia et al., 2019b, Kano et al., 2021, Jia et al., 2022b] are
trained end-to-end operating on the audio spectrogram domain without relying on text representation
at inference time. In these systems, the synthesized audio has access to acoustic information in
3
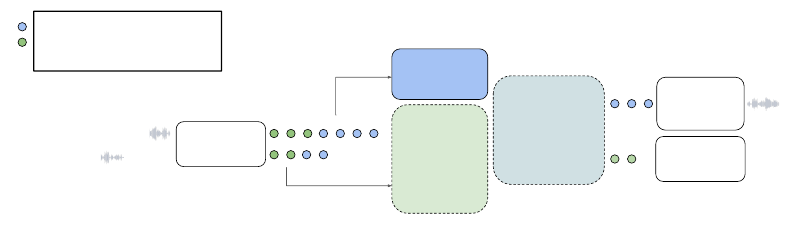
Text
Embeddings
Matrix
Audio
Embeddings
Matrix
[S2ST French English]
Decoder-only
Transformer
audio tokens
text tokens
pre-trained on text-only data
- -
SoundStorm
or AudioLM
stages 2 + 3
Audio & text
tokenizers
[ASR Italian]
Text
detokenizer
Ciao
mondo!
Figure 1: The AudioPaLM model, illustrated on speech-to-speech translation and automatic speech
recognition. We take a pretrained text-only model (dashed lines) and expand its embeddings matrix to
model a new set of audio tokens. The model architecture is otherwise unchanged; a mixed sequence
of text and audio tokens is fed as input and the model decodes text or audio tokens. Audio tokens are
converted back to raw audio with the latter AudioLM stages or SoundStorm (see Section 3.3).
source speech and can potentially learn to preserve acoustic features and reduce compound errors
and computational requirements.
There are other cascaded S2ST systems that utilize learned discrete speech representations as an
intermediate representation [Tjandra et al., 2019, Zhang et al., 2021, Lee et al., 2022, Ma et al., 2021,
Lee et al., 2021]. In these systems the translation operates in learned discrete representation space
allowing to learn alignment in the discrete domain, and simplify leveraging of text pre-training. Lastly,
there are other S2ST approaches that improve on performance, efficiency, and data requirements. Jia
et al. [2022a] and Wei et al. [2022b] leveraged weakly supervised data and component pre-training to
improve translation accuracy while requiring little parallel speech data.
3 Method
We use a decoder-only Transformer to model sequences consisting of text and audio tokens. As far
as the model is concerned, text and audio are just sequences of arbitrary integers, as the inputs are
tokenized before feeding to the model, and any outputs are detokenized before being returned to a
user of the model. By representing speech with discrete tokens in a finite vocabulary, we can build
a multimodal vocabulary which is the union of this audio vocabulary and a SentencePiece [Kudo
and Richardson, 2018b] one used to represent text. Thus, in principle there is almost no difference
between our setting and the usual decoder-only setup for pure text, except that in our setting some of
the tokens represent audio and some text, and we initialize our multimodal model using a pretrained
text-only checkpoint.
The overall model is described in Figure 1. In the rest of this section we describe the main steps of
the model: first, how text and audio inputs are tokenized; second, how we modify existing pretrained
text decoders to also model audio; and third, how we convert the model output into raw audio. Since
the first and third steps are identical to the process used by Borsos et al. [2022] and [Borsos et al.,
2023], we keep our explanation of these points high-level and refer the reader to those papers for
further details.
Finally, we describe how we finetune AudioPaLM on a mixture of combined speech and text tasks
including speech recognition and translation from or into either speech or text.
3.1 Audio Embeddings and Tokenization
We follow the process of Lakhotia et al. [2021], Borsos et al. [2022] to convert raw waveforms
into tokens. This involves extracting embeddings from an existing speech representation model and
subsequently discretizing those embeddings into a limited set of audio tokens. Borsos et al. [2022]
extract embeddings from the w2v-BERT model [Chung et al., 2021] and quantize them via k-means.
In this work, we experiment with the following approaches to obtain a set of discrete audio tokens.
4
•
w2v-BERT: We follow the procedure described in Borsos et al. [2022] with two modifi-
cations. First, we use a w2v-BERT model that has been trained on multilingual data, as
opposed to the English-only setting of Borsos et al. [2022]. Second, we do not normalize the
embeddings before performing the k-means clustering. While Borsos et al. [2022] found that
the normalization removed speaker-identity information without degrading performance,
we found in the multilingual setting that normalization did indeed cause degradation. This
method produces tokens at a rate of 25Hz and the token vocabulary is of size 1024.
•
USM-v1: We perform the same procedure with the more performant Universal Speech
Model (USM) encoder [Zhang et al., 2023a] instead of the w2v-BERT encoder. We use the
largest 2B parameter variant of this multilingual speech encoder and extract embeddings
from the middle layer. Similar to w2v-BERT, this method produces tokens at a rate of 25Hz
and the token vocabulary is of size 1024.
•
USM-v2 : We additionally experiment with a quantizer that is trained with an auxiliary ASR
loss. This version has been finetuned further to provide better multilingual performance. As
with USM-v1, this method accepts raw audio as input and returns a sequence of integers
with length proportional to the length of the audio as output.
3.2 Modifying text-only decoders to model both text and audio
In a Transformer decoder, the first layer of the model after input preprocessing is the token embeddings
matrix
E
which maps integer-valued tokens to dense embeddings; given a vocabulary of
t
tokens
and embeddings of size
m
,
E
is a
t × m
matrix whose
i
th row gives the embedding for the
i
th token.
Another embeddings matrix
E
′
appears in the final softmax layer used to compute the logits over all
tokens at each position; it is a
m × t
matrix which is multiplied with the
m
-dimensional output of the
model to obtain a
t
dimensional vector of logits, one for each of the tokens. In the PaLM architecture,
these matrices have shared variables, so that one is the transpose of the other, that is, E
′
= E
⊺
.
The rest of the decoder architecture is completely agnostic to the number of tokens modelled.
Therefore we only need to make one small modification to turn a text-only model into one that models
both text and audio: we expand the size of the embeddings matrix
E
to be of size
(t + a) × m
where
a is the number of audio tokens (the size of E
′
= E
⊺
changes accordingly).
In order to make use of pretrained text models, we change the existing model checkpoints by adding
a
new rows to the embeddings matrix
E
. An implementation detail is that the first
t
tokens (from zero
to
t
) correspond to the SentencePiece text tokens while the next
a
tokens (from
t
to
t + a
) represent
audio tokens. While we can re-use the text embeddings of the pre-trained model, the new audio
embeddings are freshly initialized and must be trained. We found it necessary to train all model
parameters rather than keeping the previous weights fixed. We train using mixed speech and text
tasks, as detailed in Section 4. In Section 5.4.2 we show how adding audio tokens to a text-pretrained
checkpoint in the above manner is highly beneficial for performance on the considered speech and
text tasks (compared to re-training from scratch). For further details about the PaLM architecture we
refer the reader to Section 2 of [Chowdhery et al., 2022].
3.3 Decoding audio tokens to raw audio
To synthesize an audio waveform from audio tokens, we experimented with two different methods:
i) autoregressive decoding, following the setup of AudioLM [Borsos et al., 2022] and ii) non-
autoregressive decoding, using the recently proposed SoundStorm model [Borsos et al., 2023]. In
both cases the audio tokens are first used to generate SoundStream tokens [Zeghidour et al., 2021],
which are then converted to an audio waveform with a convolutional decoder.
The acoustic generation in AudioLM proceeds in two stages: “Stage 2” is a decoder-only Transformer
model that takes the audio tokens produced by AudioPaLM and a voice conditioning as input, and
generates SoundStream tokens that can be used to materialize the speech in the desired voice, but at a
very low bitrate. “Stage 3” reconstructs higher levels of SoundStream’s residual vector quantizer,
which increases the bitrate and improves the audio quality. We use the same hyperparameters and the
training process as in [Kharitonov et al., 2023].
SoundStorm proposes an alternative non-autoregressive decoding scheme, which applies an iterative
method that proceeds in parallel on all tokens. SoundStorm produces audio of the same quality as
5
AudioLM, but with higher consistency in voice and acoustic conditions, while being two orders of
magnitude faster.
In both cases we train on Multilingual LibriSpeech [Pratap et al., 2020] and the voice conditioning is
supplied as a 3-second long voice sample, represented as both audio tokens and SoundStream tokens.
By providing part of the original input speech as the voice conditioning, the model is able to preserve
the original speaker’s voice when translating their speech to a different language (see Section 5).
Whenever the original audio is shorter than 3 seconds, it is repeated to reach the required duration.
3.4 Training tasks
Types of tasks We apply our method to the problems of speech recognition, speech synthesis and
speech-to-speech translation. All datasets used in this report are speech-text datasets which contain a
subset of the following fields.
• Audio: speech in the source language.
• Transcript: a transcript of the speech in Audio.
• Translated audio: the spoken translation of the speech in Audio.
• Translated transcript: the written translation of the speech in Audio.
The component tasks that we consider in this report are:
• ASR (automatic speech recognition): transcribing the audio to obtain the transcript.
•
AST (automatic speech translation): translating the audio to obtain the translated transcript.
• S2ST (speech-to-speech translation): translating the audio to obtain the translated audio.
• TTS (text-to-speech): reading out the transcription to obtain the audio.
•
MT (text-to-text machine translation): translating the transcript to obtain the translated
transcript.
A dataset including more than two of the fields may be used for multiple possible tasks. As explored
in the experiment of Section 5.4.1, we found that including multiple tasks (for example, both ASR
and AST) from the same dataset resulted in improved performance.
Expressing tasks Following Raffel et al. [2020], we signal to the model which task it should
perform on a given input by prefixing the input with a tag specifying the task and the English name
of the language of the input and, optionally, the language of the output if it is different.
For example, to query the model to perform ASR on an utterance in French, the tokenized audio
input would be preceded by the tag
[ASR French]
. To perform TTS in English, the text would
be preceded by
[TTS English]
. To perform S2ST from English to French, the tokenized English
audio would be preceded by
[S2ST English French]
. The tag is tokenized using the normal text
tokenizer of the model; we do not introduce special tokens to express the task or the languages
involved. We found that changing task names to be more human-readable, such as using
transcribe
the following French audio
instead of
[ASR French]
, does not change the performance of
the model. Naming the language in the task – compared to just using generic tags like
transcribe
audio or [ASR] – is not ultimately required but is beneficial for low-resource languages.
Combined tasks We consider both direct tasks, where the model is expected to directly map from
input to output, and combined tasks, where we instruct the model to also output intermediate steps
for a complex task. This is similar in spirit to chain of thought prompting [Wei et al., 2022a].
For example, for S2ST we could demand that the model directly maps from English audio tokens
to French audio tokens. This would be expressed with the task tag
[S2ST English French]
.
Alternatively we can train the model to first output English text, followed by French text, and finally
French audio tokens. We express this with the task tag
[ASR AST S2ST English French]
. The
model performs this task as a single autoregressive decoding, i.e. it is not performed with multiple
separate calls to the model for each task. In particular this means that the model can attend to the
input and all prior decoded content at each stage, as opposed to a separated pipeline approach of
doing ASR, MT and then TTS.
6
We found combined tasks to improve performance, which we explore in the experiment of Sec-
tion 5.4.4.
3.5 Training mixtures
In this section we describe the data mixtures used to train our best models based on the datasets listed
in Table 1. Mixtures were implemented using the SeqIO library [Roberts et al., 2022]. More details
on the datasets can be found in Section 4.
There are two mixtures: one used to train the Audio PaLM 8B AST and AudioPaLM-2 8B AST models
which output text and are trained on ASR and AST tasks; the other used to train the Audio PaLM 8B
S2ST model which outputs both text and speech and additionally includes TTS and S2ST tasks.
• The AST mixture is composed of:
–
The ASR tasks from the CVSS, VoxPopuli ASR, CommonVoice 11, Conversational
EsEn and Youtube ASR datasets. For the CVSS and Conversational EsEn datasets, we
use ASR in both source and target languages.
–
The AST tasks from CVSS, Conversational EsEn and VoxPopuli S2ST. We use Vox-
Populi S2ST for AST by mapping from the translated audio to the transcript, since the
translated transcript is not available.
– The combined AST + ASR task for the CVSS and Conversational EsEn datasets.
– The MT task from the WMT/TED dataset.
• The S2ST mixture is composed of the above, plus additionally:
–
The TTS tasks from the CVSS and VoxPopuli ASR datasets. For CVSS we use only
the source transcript and audio.
–
The S2ST tasks from the Vox Populi S2ST, CVSS, WMT/TED and PaLM MT TTS
datasets. Note that except for VoxPopuli S2ST, the speech targets of these datasets
are all synthetically generated. For VoxPopuli S2ST we perform translation from both
source to target, and target to source.
–
The combined ASR + AST + S2ST tasks from the Conversational EsEn, CVSS and
WMT/TED datasets.
In general the components of the mixture are weighted according to the number of elements in each
component while we downweighted larger datasets; Table 1 lists the amounts of audio that models
trained on the above mixtures have seen during training.
3.6 Training setup
In all experiments, we use the same finetuning setup as described in Section 6.1.2 of [Chowdhery
et al., 2022]. In particular, we finetune with the Adafactor optimizer with a constant learning rate of
5 × 10
−5
and dropout rate of 0.1, and we use loss masking on the inputs.
4 Data and Metrics
4.1 Datasets
Table 1 lists the datasets used in AudioPaLM training.
•
CoVoST2 [Wang et al., 2020] is a speech-to-text dataset mapping speech in 21 languages to
English text.
•
CVSS [Jia et al., 2022c] augmented CoVoST2 to synthesize speech for the target text
in two flavors: CVSS-C uses a canonical speakers voice, while CVSS-T transfers voice
properties from the source voice. Unless stated otherwise, we use the CVSS-C flavor in
speech-to-speech translation experiments.
•
VoxPopuli [Wang et al., 2021] contains speeches from the European Parliament together
with their transcripts – which can be used for speech recognition (ASR) tasks – as well
as spoken translations from parliamentary interpreters – which can be used for speech
translation (S2ST) tasks.
7

Table 1: Datasets used for training AudioPaLM. The number of training hours corresponds to the
number of hours seen by the AudioPaLM AST, AudioPaLM-2 AST and AudioPaLM S2ST models
during training, as a result of datasets balancing and a finite number of training steps.
Name Audio Transcript
Translated Translated # Hours of training audio
# Languages
audio transcript AudioPaLM AST AudioPaLM-2 AST AudioPaLM S2TS
CoVoST2 / CVSS ✓ ✓ ✓ ✓ 0.9k 0.9k 1.4k 21 pairs X → En
VoxPopuli ASR ✓ ✓ - - 1.6k 1.6k 1.6k 14
VoxPopuli S2ST ✓ ✓ ✓ - 6.7k 3.9k 5.4k 15
CommonVoice 11 ✓ ✓ - - 3.4k 2k 0.9K 98
Conversational EsEn ✓ ✓ ✓ ✓ 2k 2k 2k 2
YouTube ASR ✓ ✓ - - 13k 7.6k - 56
WMT/TED TTS ✓ ✓ ✓ ✓ - - 26.2k 21 pairs X → En
PaLM MT TTS ✓ ✓ ✓ ✓ - - 10.9k 113 pairs X → En
•
Common Voice [Ardila et al., 2020] consists of text paired with recordings where people
were asked to read the text aloud.
•
The conversational dataset described in [Jia et al., 2019a] was obtained by crowd-sourcing
humans to read a subset of the Spanish side of a proprietary conversational Spanish-English
MT dataset.
•
YouTube ASR is an unlabeled multilingual dataset of YouTube-based audio which was
transcribed automatically by using the USM-2B ASR model [Zhang et al., 2023a]. The
dataset helps to improve models for YouTube to perform better on captioning and translation.
•
WMT/TED TTS is based on WMT [Barrault et al., 2020, 2019, Bojar et al., 2018, 2017,
2015, 2013] and TED [Qi et al., 2018] text-to-text translation datasets as described in [Bapna
et al., 2022]. Following Jia et al. [2022a] the dataset is augmented by running all the source
and target text through a TTS engine to generate synthetic paired audio.
•
PaLM MT TTS provides additional training data for S2ST: We use PaLM-2 to translate
the transcripts of the YouTube, Common Voice, and Babel [Gales et al., 2017] datasets
to English, and use a prior AudioPaLM 8B S2ST model (trained without this dataset) to
synthesize the speech. The method is similar in spirit to [Jia et al., 2019a] which combines
MT and TTS to generate additional paired data.
We train models on mixtures based on these datasets as described in Section 3.5 on ASR, AST, and
S2ST tasks from the above datasets. In Section 5.4.6 we explore how adding more data improves the
performance of our method.
Note that our method makes use of the text-pretrained PaLM checkpoints and audio tokenizers. So
while the models are trained on the datasets listed in Table 1, they can also benefit from PaLM’s text
training data [Anil et al., 2023] via the pre-trained PaLM checkpoint, and from the data used to train
the audio tokenizers.
4.2 Evaluation Metrics
We evaluate our method on the following benchmarks:
•
CoVoST2 AST: We use BLEU scores, with the SacreBLEU corpusBLEU implementation
Papineni et al. [2002], Post [2018]. We do not perform any normalization to the text before
computing BLEU.
•
FLEURS AST: The FLEURS [Conneau et al., 2023] dataset contains speech utterances and
their corresponding transcripts in 102 languages and is used for evaluation, only. We use
BLEU scores, as described for CoVoST2 AST.
•
VoxPopuli ASR: We use the JiWER implementation of word error rate (WER). We normalise
the text by ignoring capitalisation and punctuation before computing the WER.
•
CoVoST2 ASR: Comparable to VoxPopuli ASR, but for Japanese and Chinese, the character
error rate (CER) is reported instead of WER. We report this metric for experiments trained
on CoVoST2, only.
8

Table 2: Top level results of this paper.
Model
CoVoST2 AST CVSS S2ST VoxPopuli ASR
BLEU↑ ASR-BLEU↑ WER↓
Whisper Large-v2 1.5B [Radford et al., 2022] 29.1 − 13.6
mSLAM-CTC 2B [Bapna et al., 2022] 25.2 − 9.1
MAESTRO 600M [Chen et al., 2022c] 25.2 − 8.1
USM-M [Zhang et al., 2023a] 30.7 − −
Translatotron 2 + pretraining
− 25.6 −
+ TTS aug [Jia et al., 2022a]
AudioPaLM 8B AST (ours) 35.4 − 11.1
AudioPaLM 8B S2ST (ours) 36.2 32.5 16.0
AudioPaLM-2 8B AST (ours) 37.8 − 9.8
AudioPaLM-2 8B cascaded ASR + transl. (ours) 39.0 − −
•
CVSS S2ST: Following Translatron 2 [Jia et al., 2022b], we feed the audio output of our
model into an ASR model and use BLEU to compare the ASR output with the ground truth
target text. We use the same ASR model as Jia et al. [2022b] and so the metrics presented
here are directly comparable.
All evaluations are performed on the test splits of the corresponding datasets.
5 Experiments
We start with our top-level results presenting significant improvements over prior results on automatic
speech-to-text translation (AST) and direct speech-to-speech translation (S2ST), as well as competi-
tive results on automatic speech recognition (ASR). Ablations of individual factors are provided in
Section 5.4.
5.1 Speech translation and speech recognition results
Table 2 displays results on ASR, AST and S2ST benchmarks for our method and existing baselines.
Our models come in two variants; the first variant (referred to as AST) is trained on AST tasks without
S2ST and TTS data; the second variant (referred to as S2ST) is trained with S2ST and TTS data
and is therefore able to produce speech as well. To generate the audio for the S2ST results we used
SoundStorm [Borsos et al., 2023]. For details on the training mixtures see Section 3.5.
As an initial checkpoint, we use a PaLM-2 8B checkpoint [Anil et al., 2023] to which we add the
capability to process audio tokens as input and output as described in Section 3.2. The additional
audio token embeddings are initialized to
0
. As in the original PaLM and PaLM 2 models, the input
and output embeddings are shared.
Our method exceeds the baselines on AST and S2ST and is competitive on ASR. Our method also
comes close in AST performance to a cascaded approach in which we use our best AudioPaLM-2
ASR model followed by translation with another AudioPaLM-2 model finetuned only for text-to-text
translation on CoVoST2.
5.2 Zero-shot behaviour
Setup. We evaluate the zero-shot capabilities of our AST models on the FLEURS multilingual
dataset [Conneau et al., 2023]. The dataset contains speech utterances and their corresponding
transcripts in 102 languages. Note that none of our models were trained on FLEURS, so we use the
dataset for evaluation only. In this context, we focus on the language pairs X
→
English and extract
two subsets of languages:
•
29 AST-observed languages: languages for which speech-to-text translation (AST) data (X
→
En) was seen during training (as these language pairs were present in the VoxPopuli
9

Table 3: Zero-shot AST performance on the FLEURS dataset. We split the results into two groups:
AST observed are languages for which X
→
En speech-to-text data was present in the AudioPaLM
training data. Only ASR observed are languages for which only ASR data was present in the training
data (so the translation is done by the AudioPaLM model in a zero-shot manner). This shows that
AudioPaLM inherits its translation capabilities from the base model, and is consistent with the
improved translation capabilities of PaLM-2 compared to PaLM. The hours of training data for
AudioPaLM do not include audio data seen in self-supervised training of audio tokenization models.
∗
Whisper has seen AST data for all languages considered and is included here just for reference.
Model
AST observed languages Only ASR observed languages
BLEU↑ AST / ASR hours BLEU↑ AST / ASR hours
Whisper Large-v2 1.5B [Radford et al., 2022] 23.3 74.0k / 104.4k 19.6
∗
40.6k / 11.3k
AudioPaLM 8B AST 22.4 6.6k / 11.4k 10.0 0 / 5.3k
AudioPaLM-2 8B AST 28.6 4.8k / 8.2k 20.7 0 / 3.1k
S2ST, CoVoST2 or/and Conversational EsEn datasets). These languages are indicated with
a § in Table 17.
•
26 ASR-observed languages: languages for which no speech-to-text translation data was
seen when training our AST models, but for which at least 1 hour of transcription (ASR)
data was present. We removed 3 languages (Cantonese, Kurdish and Ganda) for which
we did not have a BLEU score for the baseline. These languages are indicated with a † in
Table 17.
Results. In Table 3, we present the results obtained with the two proposed AST models AudioPaLM
and AudioPaLM-2, as well as the baseline model “Whisper Large-v2 1.5B”. We also present the
number of AST and ASR speech training hours for these three models. For the proposed models, the
reported number of hours do not take into account the amount of speech used to train the tokenizers.
Discussion. We observe that the proposed AudioPaLM-2 model significantly outperforms the
Whisper model on AST-observed languages. Although Whisper is used as a reference for the only
ASR observed setting, its results are not zero-shot as Whisper has been trained on 40.6K hours of
speech-to-text translation (AST) data for these languages. For the AudioPaLM models, this setting is
zero-shot as it did not see any AST data for these languages. Despite this disadvantage, AudioPaLM-
2 also outperforms the Whisper model on ASR-observed languages. For a detailed performance
comparison for each language, see Appendix D.
There is a large improvement obtained by using the AudioPaLM-2 instead of the AudioPaLM model:
28% increase for AST-observed languages and 107% increase for ASR-observed languages. These
numbers show that the superior text translation capabilities of AudioPaLM-2 immediately transfer
to the audio domain, despite the fact that the model has not seen any speech-to-text data for these
language pairs during training in the case of ASR-observed languages.
5.3 Quality of generated speech
In addition to measuring the translation quality of the speech content as reported in Table 2, we are
also interested in evaluating whether the speech generated by AudioPaLM is (a) of high quality, and
(b) truthfully preserves the voice of the speaker when translating to a different language. To this end,
we use a combination of objective metrics and subjective evaluation studies that use the test split
of the CVSS-T dataset [Jia et al., 2022c]. The subjective experiments were conducted on an earlier
version of AudioPaLM using the acoustic generation method described in AudioLM [Borsos et al.,
2022].
Baselines. As a first baseline, we use the ground-truth translated utterances which are provided
as a part of the CVSS-T dataset. These utterances were obtained by synthesizing the ground-truth
translated text with a high-quality TTS system which was modified to enable voice transfer [Jia et al.,
2021, 2022c]. As a result, the ground-truth utterances mimic the voice in the source utterance.
10

Table 4: Audio quality and voice similarity results. Subjective and objective audio quality results are
reported on the 1...5 MOS scale. Objective voice similarity and acoustic consistency are measured in
terms of cosine similarity. Subjective voice similarity scores span 1...5. Both objective and subjective
metrics are computed on the same set of examples. Higher is better across all metrics.
Audio quality Voice similarity Acoustic consistency
Objective Subjective Objective Subjective Objective
CVSS-T 3.41 3.88 0.24 3.70 0.54
Translatotron 2 3.36 3.96 0.18 3.51 0.44
AudioPaLM 3.65 4.44 0.40 4.00 0.81
As a second baseline, we use Translatotron 2. Note that we could not use the “Translatotron 2 +
pretraining + TTS aug” model (mentioned in Table 2) in the comparison because it was not trained
to preserve voices and instead generates speech in a single canonical voice. Instead, we use the
Translatotron 2 system presented by Jia et al. [2022c] which is capable of transferring the voice
from the source utterance (albeit it achieves a lower BLEU score on CVSS). This version of the
Translatotron 2 model was trained on the CVSS-T dataset and implements S2ST from 21 languages
to English.
Objective metrics. As the first objective metric, we use a no-reference MOS estimator akin
to Reddy et al. [2021] which, given an audio sample, provides an estimate of the perceived audio qual-
ity on a scale from 1 to 5. To measure cross-lingual voice transfer quality, we rely on an off-the-shelf
speaker verification model [Chen et al., 2022a] as used by Zhang et al. [2023b] and Kharitonov et al.
[2023], and compute the cosine similarity between the embeddings of the source (encoded/decoded
with SoundStream) and the translated speech. Besides voice preservation, we also measure how
well the acoustic properties (recording conditions, background noise) are transferred from the source
audio to the target. We do so by computing the cosine similarity between embeddings extracted
from a model trained to identify segments that belong to the same recording [Borsos et al., 2023].
Subjective evaluation. We run two separate studies, one for evaluating the quality of the generated
speech, and another for assessing the voice similarity. We use the same set of samples for both
studies. Since utterances in CVSS-T are sourced from volunteer-generated data of variable quality,
we noticed that some of the utterances contain loud overlapping speech (e.g., a TV show or a song
playing in the background) or extremely strong noise (e.g., clothes rubbing against the microphone).
Such aberrations complicate the work of raters, thus we decided to pre-filter by only selecting inputs
with an estimated MOS of at least
3.0
. Finally, we sampled 10 examples per language, giving us
21 × 10 = 210
source utterances to translate. All utterances were peak normalised and resampled to
16kHz, if needed.
Before starting, the raters were provided with a small set of illustrative examples with ground-truth
grades. They also completed a small pilot study as a training. The utterances (pairs of source-target
utterances, in the case of the voice similarity evaluation) were presented one-by-one. The ratings are
provided on a 5-grade scale from 1 (poor quality or completely different voices) to 5 (excellent quality,
identical voices). In the voice similarity study, the raters are explicitly asked to ignore differences
in the recording conditions and language, and solely focus on the voice. Each of the
630
output
examples (
10
inputs from each of
21
languages were generated with each of the
3
different systems)
was rated
10
times which results in 6300 ratings per study. Aggregating those ratings per system, we
obtain mean opinion score (MOS) and similarity mean opinion score (SMOS).
Results. We report the results of the objective and subjective evaluations in Table 4. From these
results we observe that AudioPaLM significantly outperforms the baseline Translatotron 2 system
both in audio quality and in voice similarity, in objective and subjective measurements. Moreover,
AudioPaLM has higher quality and better voice similarity than the ground-truth synthesized recordings
in CVSS-T, with a relatively large gap in most of the metrics. Following Jia et al. [2022c], we also
compared the systems across high and low-resource groups (French, German, Spanish and Catalan
vs. the rest) and found no significant variation of the metrics across these groups.
11

Table 5: Results from experiment 5.4.1 showing the impact of training with ASR data in addition to
AST data. Adding ASR tasks to the training mix helps to improve performance on AST.
Tasks
CoVoST2 AST
BLEU↑
AST only 16.0
AST & ASR 18.5
5.4 Impact of model and data choices
In this section we walk the reader through experiments that guided us towards our final training recipe
from initial early experimentation. These show the impact of individual factors and build on top of
one another until reaching the final setup described and analysed in the previous sections.
5.4.1 Training on multiple tasks
To achieve the results in Section 5.1, we trained on multiple tasks based on the same underlying
data to improve performance. For example, the CoVoST2 data can be used for both ASR and AST
tasks, and we observed that adding ASR tasks in training results in improved performance on AST
benchmarks, compared to training with the AST tasks alone. In this section we investigate the effect
of this choice on model performance.
Setup. We train two models on the CoVoST2 dataset. All conditions are identical except that in
one experiment, we use only the AST data; in the other we train with both AST and ASR tasks. The
base models are the PaLM 8B checkpoint and we use the USM-v1 tokenizer. We evaluate on the
CoVoST2 AST benchmark.
Results. See Table 5. We observe that adding ASR tasks into the dataset increases BLEU by 2.5
from 16.0 to 18.5 on the CoVoST2 AST benchmark.
Discussion. Although ASR is not part of the evaluation task, adding ASR data helped improve
performance. Our hypothesis is that ASR tasks help the model to better connect its understanding of
the new audio input to its previous understanding of text. In subsequent experiments we include both
ASR and AST tasks when using the CoVoST2 training data.
5.4.2 Training from scratch vs. finetuning
The results in Section 5.1 are based on finetuning a text-pretrained PaLM checkpoint. Here we
investigate the effect of using such a model compared to starting training from scratch on the same
architecture.
Setup. In the 1B from-scratch and 8B from-scratch experiments we start with randomly initialised
weights. In the 8B finetune experiment we start from the PaLM 8B checkpoint, which has been
modified by adding extra rows to the token embedding matrix for the audio tokens, which are
randomly initialised.
All three models are trained on CoVoST2 ASR and AST tasks.
Results. See Table 6. We observe that finetuning the PaLM 8B checkpoint achieves substantially
higher performance than training from scratch on CoVoST2 tasks for both ASR and AST. The
1B-from-scratch experiment was added to determine whether a smaller model architecture would
work better than the 8B model when trained from scratch on CoVoST2; it does not.
Discussion. Finetuning a pretrained checkpoint substantially improves results. This is in some
sense not surprising as the base model is very capable to begin with; nonetheless it is interesting that
with finetuning the model is able to adapt to completely new input stimulus, since the audio tokens
are totally new embeddings that the model must learn to understand. Furthermore the audio tokens
are very different from text: despite the low sampling rate, there is presumably still some redundancy
12

Table 6: Results from Experiment 5.4.2 showing that training from a pretrained checkpoint has a
substantial positive effect on performance compared to training from scratch.
Initial checkpoint
CoVoST2 AST CoVoST2 ASR
BLEU↑ WER↓
PaLM 1B from scratch 6.5 66.0
PaLM 8B from scratch 6.9 63.3
PaLM 8B finetuned 18.4 40.2
Table 7: Results from Experiment 5.4.3 showing the impact of training with different types of tokens.
Performance is affected significantly by the choice of tokens.
Tokens
CoVoST2 AST CoVoST2 ASR
BLEU↑ WER↓
W2V-BERT 15.2 50.1
USM-v1 18.5 40.2
USM-v2 26.9 22.3
in the data and the rate of samples is still much higher than text tokens — we estimate from the data
that at 25Hz, one text token corresponds to approximately 6-8 audio tokens.
5.4.3 Different tokenization schemes
To obtain the results in Section 5.1, we tokenized audio based on USM-v2. Here we investigate the
impact of the choice of tokenization scheme on the final results.
Setup. We train three models with all conditions identical except for the tokenization scheme
applied to the audio. All models are trained using the PaLM 8B checkpoint. In each case we use
the CVSS datasets with ASR and AST tasks with the source audio preprocessed using different
tokenizers. The three tokenizers used are the w2v-BERT, USM-v1 and USM-v2 tokenizers which
were discussed Section 3.1.
Results. See Table 7. We observe that the choice of tokenization scheme has a large impact on the
performance of the model. The fact that the USM encoder is more powerful than w2v-BERT indeed
translates to an improvement in performance in our setting. The USM-v2 tokens perform even better,
yielding substantially improved results.
Discussion. The choice of tokenization scheme has a substantial effect on performance. This is not
surprising; the model only is exposed to the information captured by the tokenizer, and this may be in
a form which is easy or difficult for the model to process. Future work should consider tokenization
of audio more carefully because this is still relatively immature as a research area.
5.4.4 Training with combined tasks
To obtain the results in Section 5.1, we required the model to compute intermediate steps for complex
tasks by combining multiple tasks into one, as described in Section 3.4. In the following we investigate
the impact of this choice.
Setup. We train pairs of models on the CoVoST2 AST dataset. Within a pair, the only change
is that for one model we train with ASR and AST tasks, while for the other we also include the
combined task consisting of first doing ASR and then outputting the AST result. For the latter model,
at evaluation time we report the result of doing the combined task from which we use only the final
output. We repeat this setup twice: once with the USM-v1 tokens, and once with the USM-v2 tokens.
Results. See Table 8. This shows that expressing the AST task as a combination of simpler tasks
results in improved performance on the AST task. At the same time, we see a small reduction in
performance on the ASR task.
13

Table 8: Results from Experiment 5.4.4 showing that defining complex tasks as combinations of
simpler tasks results in an improvement in performance on the AST task and a small reduction on the
ASR task.
Tokens Tasks
CoVoST2 AST CoVoST2 ASR
BLEU↑ WER↓
USM-v1
Direct 18.5 40.2
Combined 22.1 41.6
USM-v2
Direct 26.9 22.3
Combined 30.5 25.3
Table 9: Results from Experiment 5.4.5 showing that training with S2ST data brings new capabilities
but results in a degradation of performance on AST and ASR tasks.
Tasks
CoVoST2 AST CVSS S2ST CoVoST2 ASR
BLEU↑ ASR-BLEU↑ WER↓
AST, ASR 30.5 − 25.3
AST, ASR & S2ST 27.8 24.2 27.1
Discussion. Our results are consistent with prior works which have observed that allowing the
model to break down a complex task into easier pieces results in improved performance, relative to
making the model directly output the answer [Wei et al., 2022a].
At the same time, we observe a reduction in performance on the ASR task. We hypothesize that this
may be a consequence of our checkpoint selection criterion, which was to select the checkpoint with
the best AST metric on the validation split. It may also be a consequence of the large change in the
data mixture resulting from this change.
We note that it may appear that combined tasks reduce the problem to a pipeline approach of separate
ASR and translation systems. However this is not the case, as the model can refer to all previous
tokens at each step and is a single unified model. For example, when decoding the translated text,
it is possible to refer to the input audio and any information contained in them. This is particularly
important for the S2ST setting (see Experiment 5.4.5) where prosodic information may be present in
the input audio, which can be attended to while decoding output audio.
5.4.5 Training with additional speech-to-speech tasks
In the following, we investigate the impact of adding speech-to-speech translation (S2ST) tasks to the
trained tasks.
Setup. We train two models using the CoVoST2 dataset. One model is only trained on the AST, ASR
and combined AST tasks. The other model is additionally trained on S2ST as a direct and combined
task. Thus the difference between these two models is that in the S2ST the model additionally sees
tasks in which it must output audio tokens, whereas for the other tasks (and all previous experiments)
the model only outputs text tokens.
Results. See Table 9. We observe that adding the S2ST task results in the new capability of being
able to perform S2ST, but that this comes at the cost of a modest decrease in performance to both the
AST BLEU score and ASR WER score when evaluating on the CoVoST2 test split.
Discussion. Since we use loss masking on the inputs for each training example, performing S2ST
is fundamentally different from ASR or AST since the model must learn to emit audio tokens. For
ASR and AST, the model takes audio tokens as input, but the loss masking means that it doesn’t need
to learn to model these sequences of audio tokens. It is thus perhaps not surprising that this results in
a decrease in performance on the text-output tasks, since model capacity must be devoted to audio
modelling.
14

Table 10: Results for Experiment 5.4.6 showing that scaling the amount of training data improves
performance. Observe also that within each pair, adding S2ST tasks brings new capabilities, but
at the expense of slight decrease in performance on AST and ASR tasks. “Public speech datasets”
corresponds to CoVoST2/CVSS, Vox Populi, CommonVoice 11 and Conversational EsEn.
Datasets Tasks
VoxP. ASR CoVoST2 ASR CoVoST2 AST CVSS S2ST
WER↓ WER↓ BLEU↑ ASR-BLEU↑
CoVoST2 / CVSS
AST 168.7 25.3 30.5 −
S2ST 166.3 27.1 27.8 24.2
Public speech datasets
AST 9.0 15.5 33.1 −
S2ST 14.5 19.4 31.9 27.0
Public speech datasets AST 9.6 13.8 34.8 −
+ YT S2ST 14.5 16.5 32.3 27.6
Public speech datasets AST 11.1 15.1 35.4 −
+ YT + WMT/TED S2ST 15.4 16.6 33.8 29.5
Public speech datasets
S2ST 16.0 15.0 36.2 31.2
+ PaLM MT TTS + WMT/TED
5.4.6 Scaling the training data
In this section we investigate the impact of increasing the amount of training data.
Setup. We run this analysis on two types of models, both trained from a PaLM 8B checkpoint and
with USM-v2 tokens. The models “AudioPaLM 8B AST” are trained without the S2ST tasks, the
models “AudioPaLM 8B S2ST” are trained with the S2ST tasks.
We train these two types of models with an increasing amount of data:
•
The CoVoST2 dataset only. For the S2ST model, we use the modified S2ST version of this
dataset: CVSS.
•
All the public datasets described in Table 1, namely CoVoST2/CVSS, VoxPopuli AST,
VoxPopuli S2ST, CommonVoice 11 and Conversational EsEn.
• All the public datasets, as well as the YouTube ASR dataset.
•
All the public datasets, as well as the YouTube ASR dataset and the WMT/TED text-to-text
translation dataset. For the S2ST models, we follow Jia et al. [2022a] and synthesise a paired
S2ST dataset from this by using TTS on the examples in this dataset.
•
As above, but using the synthetic PaLM-based MT TTS dataset S2ST mixture instead of
the YouTube ASR dataset. For this dataset we used PaLM-2 to translate the transcripts of
the YouTube, Common Voice, and Babel datasets to English text, and then synthesized the
English speech to create a speech-to-speech dataset.
Results. See Table 10. We observe that training with increasing amounts of data yields a substantial
improvement. In particular, consistent with Experiment 5.4.1 we see that adding additional ASR
data helps on AST tasks. Consistent with Experiment 5.4.5 we observe that for each fixed dataset
mixture for which we compare the AST and S2ST mixtures, including the S2ST tasks brings new
S2ST capabilities at the cost of a modest reduction in performance on AST. All of the S2ST results in
Table 10 use AudioLM stage 2 and 3 models [Borsos et al., 2022] to reconstruct the audio samples
from audio tokens as discussed in Section 3.3.
Discussion. It is unsurprising that scaling the amount of training data results in an improvement
in performance. We observe that adding more data in some cases leads to a small reduction in
performance on the ASR tasks, though always an improvement on the AST tasks. Similar to
Experiment 5.4.4, this may be a consequence of our checkpoint selection criterion, which is based on
AST performance on the CVSS validation set.
15

Table 11: Results for Experiment 5.4.7 showing the impact on S2ST metrics of decoding from audio
tokens to wave audio using AudioLM stage 2 and 3 models compared to SoundStorm.
Decoder
CVSS S2ST
ASR-BLEU↑
AudioLM 31.2
SoundStorm 32.5
Table 12: Results for Experiment 5.4.8 showing impact of finetuning PaLM vs PaLM-2.
Datasets Checkpoint
VoxPopuli ASR CoVoST2 ASR CVSS AST
WER↓ WER↓ BLEU↑
Public + YT
PaLM 9.6 13.8 34.8
PaLM-2 9.7 17.4 37.2
Public + YT + WMT/TED
PaLM 11.1 15.1 35.4
PaLM-2 9.8 15.7 37.8
5.4.7 Decoding with AudioLM vs SoundStorm
In this section we investigate the impact on S2ST metrics of decoding using AudioLM stage 2 and 3
models vs SoundStorm.
Setup. We take the best AudioPaLM model from Section 5.4.6 trained with the mixture consisting
of public, PaLM MT TTS and WMT/TED datasets. The previous experiment used AudioLM stage 2
and 3 models to decode the audio tokens output by AudioPaLM to wave audio. We rerun this using a
SoundStorm model instead, and measure the impact on the CVSS S2ST task.
Results. See Table 11. We observe a 1.3 BLEU point increase when using SoundStorm compared
to AudioLM. This result corresponds to the S2ST model presented in Table 2 trained on the S2ST
mixture described in 3.5.
Discussion These observations are consistent with those reported in Borsos et al. [2023], which
found that compared to AudioLM, SoundStorm produces more intelligible speech when used to
decode semantic audio tokens. This was measured by how faithfully the resulting audio matches a
ground truth transcript when transcribed with an ASR system, which is similar to our setup.
5.4.8 Impact of using PaLM-2
In the following we explore the effect of using the PaLM-2 checkpoint vs the original PaLM model.
PaLM-2 was trained with improved data and techniques compared to the original PaLM model, and
was explicitly trained with parallel translation data. We therefore aim to understand whether these
improvements translate to gains in speech tasks.
Setup. We focus on speech-to-text tasks and do not consider S2ST. We train two pairs of models
on the largest datasets considered in Section 5.4.6. For each dataset we train two models, one using
the PaLM 8B checkpoint and the other using the PaLM-2 8B checkpoint. Compared to the PaLM
finetuning experiments, the optimization hyperparameters differed: we used a dropout rate of
0.2
and
a learning rate schedule of linear ramp-up to 10
−4
followed by exponential decay to 10
−5
.
Results. See Table 12. On the smaller mixture, we observe an improvement on the CoVoST2 AST
task, and a minor degradation on VoxPopuli ASR and a more significant degradation on CoVoST2
ASR. On the larger data mixture, we see that PaLM-2 exceeds PaLM on the Vox Populi ASR and
CVSS AST tasks, and is slightly worse on CoVoST2 ASR. Our interpretation of these results is that
the improved ability of PaLM-2 to perform text translation leads to an improvement for AST. The
impact on ASR capabilities is mixed, where when using the full training mixture, PaLM 2 exhibits
slightly worse ASR capabilities on CoVoST2 and slightly better ones on VoxPopuli ASR.
16
Table 13: Results for Experiment 5.4.9 showing impact of architecture scale when using PaLM-2
checkpoints on AST/ASR tasks.
Datasets Checkpoint size
VoxPopuli ASR CoVoST2 ASR CVSS AST
WER↓ WER↓ BLEU↑
Public + YT
128M 15.9 30.2 16.6
1B 11.9 21.5 30.4
8B 9.7 17.4 37.2
Public + YT + WMT/TED
128M 16.4 29.9 18.3
1B 11.7 17.3 31.6
8B 9.8 15.7 37.8
Discussion. While we do see a difference, we suspect that the different capabilities between PaLM
and PaLM-2 are not as important in this setting as they might be for purely text-based tasks, since the
addition of tokenized audio is novel for both models.
5.4.9 Impact of architecture scale
In the following we investigate the impact of the model size on the downstream task performance.
We use PaLM-2 for this and focus on the ASR and AST settings.
Setup. We train three PaLM-2 models of different sizes (128M, 1B, and 8B) using USM-v2 tokens
with the same two largest datasets from Section 5.4.6 and observe their performance on our benchmark
ASR and AST tasks.
Results. See Table 13. We find that our results improve substantially with model size, with 42%
and 28% reduction in WER for CVSS and VoxPopuli ASR tasks and over 13 points increase in BLEU
scores for translation tasks respectively moving from 128M to 1B model on the full Public + YT +
WMT/TED dataset. Increasing the model size further from 1B to 8B leads to additional gains of a
further 10% and 16% reduction in WER for CVSS and VoxPopuli ASR tasks and a further 6.2 point
improvement in BLEU score. We find the scaling improvements also hold across different training
datasets (e.g., Public + YT compared with Public + YT + WMT/TED).
Discussion. As expected, performance on downstream ASR/AST tasks improves with larger model
size. Our 1B sized model outperforms Whisper 1.5B Large model by over 5 BLEU points and 28%
reduction in WER for VoxPopuli ASR.
6 Conclusion
We introduce AudioPaLM, a large language model that can process and generate speech and text
interchangeably. AudioPaLM starts from a pre-trained text-based LLM and extends its vocabulary
with discrete audio tokens. In doing so, the model can leverage its existing text capabilities while
being finetuned to also consume and produce tokenized audio on a mixture of speech-text tasks.
Moreover, by expressing the different tasks with textual tags, a single model can be trained on all tasks
together. AudioPaLM demonstrates state-of-the-art results on speech translation benchmarks and
competitive performance on speech recognition tasks, as well as zero-shot speech-to-text translation
abilities on unseen language pairs. AudioPaLM also benefits from features of audio language models,
such as voice prompting, and can perform S2ST with voice transfer of a superior quality compared to
existing baselines, as measured by both automatic metrics and human raters.
Limitations The fact that our model can natively produce audio is a consequence of the fact that
we make use of tokenized audio. This introduces a strong dependency on the quality of the audio
tokenizer, as demonstrated in Section 7. We additionally empirically found it necessary to finetune
the whole model, unlike a Flamingo-like [Alayrac et al., 2022] approach which freezes most of
the weights and thus provides guarantees on preservation of the original capabilities of the model
components.
17
Open questions There are numerous further avenues of research. One strand is around audio
tokenization: what are desirable properties of audio tokens, how can we measure them, and how
can we optimize for them? Another is around evaluations. In comparison to text, the richness of
the set of established benchmarks for generative text/audio tasks is less developed. This work has
focused on speech recognition and speech translation, for which the benchmarks are more mature.
The establishment of more benchmarks and metrics for generative audio tasks will help to accelerate
research further.
Acknowledgements
We would like to thank Nobuyuki Morioka and Yifan Ding for their help in re-creating the TTS-
augmented WMT/TED dataset which was also used in Jia et al. [2022a] and Adam Roberts and Ron
Weiss for their advice and reviews. We would like to thank Slav Petrov, Colin Cherry and the PaLM-2
team for their advice and support.
References
A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen,
A. Roberts, M. Tagliasacchi, M. Sharifi, N. Zeghidour, and C. Frank. Musiclm: Generating music
from text. arXiv preprint arXiv:2301.11325, 2023.
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican,
M. Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in Neural
Information Processing Systems, 35:23716–23736, 2022.
R. Anil, A. M. Dai, O. Firat, M. Johnson, D. Lepikhin, A. T. Passos, S. Shakeri, E. Taropa, P. Bailey,
Z. Chen, E. Chu, J. Clark, L. E. Shafey, Y. Huang, K. S. Meier-Hellstern, G. Mishra, E. Moreira,
M. Omernick, K. Robinson, S. Ruder, Y. Tay, K. Xiao, Y. Xu, Y. Zhang, G. H. ’Abrego, J. Ahn,
J. Austin, P. Barham, J. A. Botha, J. Bradbury, S. Brahma, K. M. Brooks, M. Catasta, Y. Cheng,
C. Cherry, C. A. Choquette-Choo, A. Chowdhery, C. Crépy, S. Dave, M. Dehghani, S. Dev,
J. Devlin, M. C. D’iaz, N. Du, E. Dyer, V. Feinberg, F. Feng, V. Fienber, M. Freitag, X. García,
S. Gehrmann, L. González, G. Gur-Ari, S. Hand, H. Hashemi, L. Hou, J. Howland, A. R. Hu,
J. Hui, J. Hurwitz, M. Isard, A. Ittycheriah, M. Jagielski, W. H. Jia, K. Kenealy, M. Krikun,
S. Kudugunta, C. Lan, K. Lee, B. Lee, E. Li, M.-L. Li, W. Li, Y. Li, J. Li, H. Lim, H. Lin, Z.-Z.
Liu, F. Liu, M. Maggioni, A. Mahendru, J. Maynez, V. Misra, M. Moussalem, Z. Nado, J. Nham,
E. Ni, A. Nystrom, A. Parrish, M. Pellat, M. Polacek, A. Polozov, R. Pope, S. Qiao, E. Reif,
B. Richter, P. Riley, A. Ros, A. Roy, B. Saeta, R. Samuel, R. M. Shelby, A. Slone, D. Smilkov, D. R.
So, D. Sohn, S. Tokumine, D. Valter, V. Vasudevan, K. Vodrahalli, X. Wang, P. Wang, Z. Wang,
T. Wang, J. Wieting, Y. Wu, K. Xu, Y. Xu, L. W. Xue, P. Yin, J. Yu, Q. Zhang, S. Zheng, C. Zheng,
W. Zhou, D. Zhou, S. Petrov, and Y. Wu. Palm 2 technical report. arXiv preprint arXiv:2305.10403,
2023.
R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Henretty, R. Morais, L. Saunders,
F. Tyers, and G. Weber. Common voice: A massively-multilingual speech corpus. In Proceedings
of the Twelfth Language Resources and Evaluation Conference, pages 4218–4222, Marseille,
France, May 2020. European Language Resources Association. ISBN 979-10-95546-34-4. URL
https://aclanthology.org/2020.lrec-1.520.
A. Baevski, Y. Zhou, A. Mohamed, and M. Auli. wav2vec 2.0: A framework for self-supervised
learning of speech representations. Advances in neural information processing systems, 33:
12449–12460, 2020.
A. Bapna, C. Cherry, Y. Zhang, Y. Jia, M. Johnson, Y. Cheng, S. Khanuja, J. Riesa, and A. Con-
neau. mslam: Massively multilingual joint pre-training for speech and text. arXiv preprint
arXiv:2202.01374, 2022.
L. Barrault, O. Bojar, M. R. Costa-jussà, C. Federmann, M. Fishel, Y. Graham, B. Haddow, M. Huck,
P. Koehn, S. Malmasi, C. Monz, M. Müller, S. Pal, M. Post, and M. Zampieri. Findings of the
2019 conference on machine translation (WMT19). In Proceedings of the Fourth Conference
on Machine Translation (Volume 2: Shared Task Papers, Day 1), pages 1–61. Association for
Computational Linguistics, 2019. URL https://aclanthology.org/W19-5301.
18
L. Barrault, M. Biesialska, O. Bojar, M. R. Costa-jussà, C. Federmann, Y. Graham, R. Grundkiewicz,
B. Haddow, M. Huck, E. Joanis, T. Kocmi, P. Koehn, C.-k. Lo, N. Ljubeši
´
c, C. Monz, M. Morishita,
M. Nagata, T. Nakazawa, S. Pal, M. Post, and M. Zampieri. Findings of the 2020 conference on
machine translation (WMT20). In Proceedings of the Fifth Conference on Machine Translation,
pages 1–55. Association for Computational Linguistics, 2020. URL
https://aclanthology.
org/2020.wmt-1.1.
O. Bojar, C. Buck, C. Callison-Burch, C. Federmann, B. Haddow, P. Koehn, C. Monz, M. Post,
R. Soricut, and L. Specia. Findings of the 2013 Workshop on Statistical Machine Translation. In
Proceedings of the Eighth Workshop on Statistical Machine Translation, pages 1–44. Association
for Computational Linguistics, 2013. URL https://aclanthology.org/W13-2201.
O. Bojar, R. Chatterjee, C. Federmann, B. Haddow, M. Huck, C. Hokamp, P. Koehn, V. Logacheva,
C. Monz, M. Negri, M. Post, C. Scarton, L. Specia, and M. Turchi. Findings of the 2015
workshop on statistical machine translation. In Proceedings of the Tenth Workshop on Statistical
Machine Translation, pages 1–46. Association for Computational Linguistics, 2015. URL
https:
//aclanthology.org/W15-3001.
O. Bojar, R. Chatterjee, C. Federmann, Y. Graham, B. Haddow, S. Huang, M. Huck, P. Koehn, Q. Liu,
V. Logacheva, C. Monz, M. Negri, M. Post, R. Rubino, L. Specia, and M. Turchi. Findings of
the 2017 conference on machine translation (WMT17). In Proceedings of the Second Conference
on Machine Translation, pages 169–214. Association for Computational Linguistics, 2017. URL
https://aclanthology.org/W17-4717.
O. Bojar, C. Federmann, M. Fishel, Y. Graham, B. Haddow, M. Huck, P. Koehn, and C. Monz.
Findings of the 2018 conference on machine translation (WMT18). In Proceedings of the Third
Conference on Machine Translation: Shared Task Papers, pages 272–303. Association for Compu-
tational Linguistics, 2018. URL https://aclanthology.org/W18-6401.
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, O. Teboul, D. Grangier,
M. Tagliasacchi, and N. Zeghidour. AudioLM: a language modeling approach to audio generation.
arXiv preprint arXiv:2209.03143, 2022.
Z. Borsos, M. Sharifi, D. Vincent, E. Kharitonov, N. Zeghidour, and M. Tagliasacchi. Soundstorm:
Efficient parallel audio generation. arXiv preprint arXiv:2305.09636, 2023.
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam,
G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh,
D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark,
C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei. Language models are few-shot
learners. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors, Advances in
Neural Information Processing Systems 33: Annual Conference on Neural Information Processing
Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. URL
https://proceedings.
neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu,
L. Zhou, S. Ren, Y. Qian, Y. Qian, J. Wu, M. Zeng, X. Yu, and F. Wei. Wavlm: Large-scale
self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process., 16
(6):1505–1518, 2022a. doi: 10.1109/JSTSP.2022.3188113. URL
https://doi.org/10.1109/
JSTSP.2022.3188113.
X. Chen, X. Wang, S. Changpinyo, A. Piergiovanni, P. Padlewski, D. Salz, S. Goodman, A. Grycner,
B. Mustafa, L. Beyer, et al. PaLI: A jointly-scaled multilingual language-image model. arXiv
preprint arXiv:2209.06794, 2022b.
Y.-C. Chen, L. Li, L. Yu, A. El Kholy, F. Ahmed, Z. Gan, Y. Cheng, and J. Liu. Uniter: Universal
image-text representation learning. In Computer Vision–ECCV 2020: 16th European Conference,
Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX, pages 104–120. Springer, 2020.
Z. Chen, Y. Zhang, A. Rosenberg, B. Ramabhadran, P. Moreno, A. Bapna, and H. Zen. Maestro:
Matched speech text representations through modality matching. arXiv preprint arXiv:2204.03409,
2022c.
19
C.-C. Chiu, J. Qin, Y. Zhang, J. Yu, and Y. Wu. Self-supervised learning with random-projection
quantizer for speech recognition. In International Conference on Machine Learning, pages
3915–3924. PMLR, 2022.
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung,
C. Sutton, S. Gehrmann, et al. PaLM: Scaling language modeling with pathways. arXiv preprint
arXiv:2204.02311, 2022.
Y.-A. Chung, Y. Zhang, W. Han, C.-C. Chiu, J. Qin, R. Pang, and Y. Wu. W2V-Bert: Combining
contrastive learning and masked language modeling for self-supervised speech pre-training. In
ASRU, 2021.
A. Conneau, M. Ma, S. Khanuja, Y. Zhang, V. Axelrod, S. Dalmia, J. Riesa, C. Rivera, and A. Bapna.
Fleurs: Few-shot learning evaluation of universal representations of speech. In 2022 IEEE Spoken
Language Technology Workshop (SLT), pages 798–805. IEEE, 2023.
A. Défossez, J. Copet, G. Synnaeve, and Y. Adi. High fidelity neural audio compression. CoRR,
abs/2210.13438, 2022. doi: 10.48550/arXiv.2210.13438. URL
https://doi.org/10.48550/
arXiv.2210.13438.
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirectional
transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
C. Donahue, A. Caillon, A. Roberts, E. Manilow, P. Esling, A. Agostinelli, M. Verzetti, I. Simon,
O. Pietquin, N. Zeghidour, and J. H. Engel. Singsong: Generating musical accompaniments
from singing. CoRR, abs/2301.12662, 2023. doi: 10.48550/arXiv.2301.12662. URL
https:
//doi.org/10.48550/arXiv.2301.12662.
T.-J. Fu, L. Li, Z. Gan, K. Lin, W. Y. Wang, L. Wang, and Z. Liu. Violet: End-to-end video-language
transformers with masked visual-token modeling. arXiv preprint arXiv:2111.12681, 2021.
M. J. Gales, K. M. Knill, and A. Ragni. Low-resource speech recognition and keyword-spotting. In
Speech and Computer: 19th International Conference, SPECOM 2017, Hatfield, UK, September
12-16, 2017, Proceedings 19, pages 3–19. Springer, 2017.
Z. Gan, Y.-C. Chen, L. Li, C. Zhu, Y. Cheng, and J. Liu. Large-scale adversarial training for vision-
and-language representation learning. Advances in Neural Information Processing Systems, 33:
6616–6628, 2020.
M. Hassid, T. Remez, T. A. Nguyen, I. Gat, A. Conneau, F. Kreuk, J. Copet, A. Défossez, G. Synnaeve,
E. Dupoux, R. Schwartz, and Y. Adi. Textually pretrained speech language models. arXiv preprint
arXiv:2305.13009, 2023.
W.-N. Hsu, B. Bolte, Y.-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed. Hubert:
Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM
Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021.
Y. Jia, M. Johnson, W. Macherey, R. J. Weiss, Y. Cao, C.-C. Chiu, N. Ari, S. Laurenzo, and Y. Wu.
Leveraging weakly supervised data to improve end-to-end speech-to-text translation. In Proc.
ICASSP, pages 7180–7184, 2019a.
Y. Jia, R. J. Weiss, F. Biadsy, W. Macherey, M. Johnson, Z. Chen, and Y. Wu. Direct speech-to-speech
translation with a sequence-to-sequence model. In INTERSPEECH, 2019b.
Y. Jia, H. Zen, J. Shen, Y. Zhang, and Y. Wu. Png bert: Augmented bert on phonemes and graphemes
for neural tts. Proc. Interspeech 2021, pages 151–155, 2021.
Y. Jia, Y. Ding, A. Bapna, C. Cherry, Y. Zhang, A. Conneau, and N. Morioka. Leveraging unsuper-
vised and weakly-supervised data to improve direct speech-to-speech translation. arXiv preprint
arXiv:2203.13339, 2022a.
Y. Jia, M. T. Ramanovich, T. Remez, and R. Pomerantz. Translatotron 2: High-quality direct speech-
to-speech translation with voice preservation. In International Conference on Machine Learning,
pages 10120–10134. PMLR, 2022b.
20
Y. Jia, M. T. Ramanovich, Q. Wang, and H. Zen. Cvss corpus and massively multilingual speech-to-
speech translation. arXiv preprint arXiv:2201.03713, 2022c.
T. Kano, S. Sakti, and S. Nakamura. Transformer-based direct speech-to-speech translation with
transcoder. In Proc. IEEE SLT, pages 958–965, 2021.
E. Kharitonov, D. Vincent, Z. Borsos, R. Marinier, S. Girgin, O. Pietquin, M. Sharifi, M. Tagliasacchi,
and N. Zeghidour. Speak, read and prompt: High-fidelity text-to-speech with minimal supervision.
arXiv preprint arXiv:2302.03540, 2023.
F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. Défossez, J. Copet, D. Parikh, Y. Taigman, and
Y. Adi. Audiogen: Textually guided audio generation. CoRR, abs/2209.15352, 2022. doi:
10.48550/arXiv.2209.15352. URL https://doi.org/10.48550/arXiv.2209.15352.
T. Kudo and J. Richardson. Sentencepiece: A simple and language independent subword tokenizer
and detokenizer for neural text processing. arXiv preprint arXiv:1808.06226, 2018a.
T. Kudo and J. Richardson. Sentencepiece: A simple and language independent subword tokenizer
and detokenizer for neural text processing. In E. Blanco and W. Lu, editors, Proceedings of the
2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018: System
Demonstrations, Brussels, Belgium, October 31 - November 4, 2018, pages 66–71. Association
for Computational Linguistics, 2018b. doi: 10.18653/v1/d18-2012. URL
https://doi.org/10.
18653/v1/d18-2012.
K. Lakhotia, E. Kharitonov, W.-N. Hsu, Y. Adi, A. Polyak, B. Bolte, T.-A. Nguyen, J. Copet,
A. Baevski, A. Mohamed, et al. On generative spoken language modeling from raw audio.
Transactions of the Association for Computational Linguistics, 9:1336–1354, 2021.
A. Lavie, A. Waibel, L. Levin, M. Finke, D. Gates, M. Gavalda, T. Zeppenfeld, and P. Zhan. JANUS-
III: Speech-to-speech translation in multiple languages. In ICASSP, 1997.
A. Lee, H. Gong, P.-A. Duquenne, H. Schwenk, P.-J. Chen, C. Wang, S. Popuri, J. Pino, J. Gu, and
W.-N. Hsu. Textless speech-to-speech translation on real data. arXiv preprint arXiv:2112.08352,
2021.
A. Lee, P.-J. Chen, C. Wang, J. Gu, X. Ma, A. Polyak, Y. Adi, Q. He, Y. Tang, J. Pino, and W.-N.
Hsu. Direct speech-to-speech translation with discrete units. In ACL, 2022.
X. Ma, H. Gong, D. Liu, A. Lee, Y. Tang, P.-J. Chen, W.-N. Hsu, K. Heafield, P. Koehn, and J. Pino.
Direct simultaneous speech to speech translation. arXiv preprint arXiv:2110.08250, 2021.
S. Nakamura, K. Markov, H. Nakaiwa, G. Kikui, H. Kawai, T. Jitsuhiro, J.-S. Zhang, H. Yamamoto,
E. Sumita, and S. Yamamoto. The ATR multilingual speech-to-speech translation system. IEEE
Transactions on Audio, Speech, and Language Processing, 2006.
A. v. d. Oord, Y. Li, and O. Vinyals. Representation learning with contrastive predictive coding.
arXiv preprint arXiv:1807.03748, 2018.
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu. Bleu: a method for automatic evaluation of machine
translation. In Proceedings of the 40th annual meeting of the Association for Computational
Linguistics, pages 311–318, 2002.
M. Post. A call for clarity in reporting BLEU scores. In Proceedings of the Third Conference on
Machine Translation: Research Papers, pages 186–191, Belgium, Brussels, Oct. 2018. Association
for Computational Linguistics. URL https://www.aclweb.org/anthology/W18-6319.
V. Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert. Mls: A large-scale multilingual dataset
for speech research. arXiv preprint arXiv:2012.03411, 2020.
Y. Qi, D. Sachan, M. Felix, S. Padmanabhan, and G. Neubig. When and why are pre-trained word
embeddings useful for neural machine translation? In Proceedings of the 2018 Conference of the
North American Chapter of the Association for Computational Linguistics: Human Language
Technologies, Volume 2 (Short Papers), pages 529–535. Association for Computational Linguistics,
2018. URL https://aclanthology.org/N18-2084.
21
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin,
J. Clark, et al. Learning transferable visual models from natural language supervision. In
International conference on machine learning, pages 8748–8763. PMLR, 2021.
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever. Robust speech
recognition via large-scale weak supervision. arXiv preprint arXiv:2212.04356, 2022.
J. W. Rae, S. Borgeaud, T. Cai, K. Millican, J. Hoffmann, H. F. Song, J. Aslanides, S. Henderson,
R. Ring, S. Young, E. Rutherford, T. Hennigan, J. Menick, A. Cassirer, R. Powell, G. van den
Driessche, L. A. Hendricks, M. Rauh, P. Huang, A. Glaese, J. Welbl, S. Dathathri, S. Huang,
J. Uesato, J. Mellor, I. Higgins, A. Creswell, N. McAleese, A. Wu, E. Elsen, S. M. Jayakumar,
E. Buchatskaya, D. Budden, E. Sutherland, K. Simonyan, M. Paganini, L. Sifre, L. Martens, X. L.
Li, A. Kuncoro, A. Nematzadeh, E. Gribovskaya, D. Donato, A. Lazaridou, A. Mensch, J. Lespiau,
M. Tsimpoukelli, N. Grigorev, D. Fritz, T. Sottiaux, M. Pajarskas, T. Pohlen, Z. Gong, D. Toyama,
C. de Masson d’Autume, Y. Li, T. Terzi, V. Mikulik, I. Babuschkin, A. Clark, D. de Las Casas,
A. Guy, C. Jones, J. Bradbury, M. J. Johnson, B. A. Hechtman, L. Weidinger, I. Gabriel, W. Isaac,
E. Lockhart, S. Osindero, L. Rimell, C. Dyer, O. Vinyals, K. Ayoub, J. Stanway, L. Bennett,
D. Hassabis, K. Kavukcuoglu, and G. Irving. Scaling language models: Methods, analysis &
insights from training gopher. CoRR, abs/2112.11446, 2021. URL
https://arxiv.org/abs/
2112.11446.
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu.
Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of
Machine Learning Research, 21(1):5485–5551, 2020.
C. K. A. Reddy, V. Gopal, and R. Cutler. Dnsmos: A non-intrusive perceptual objective speech quality
metric to evaluate noise suppressors. In IEEE International Conference on Acoustics, Speech and
Signal Processing (DNSMOS), 2021.
A. Roberts, H. W. Chung, A. Levskaya, G. Mishra, J. Bradbury, D. Andor, S. Narang, B. Lester,
C. Gaffney, A. Mohiuddin, C. Hawthorne, A. Lewkowycz, A. Salcianu, M. van Zee, J. Austin,
S. Goodman, L. B. Soares, H. Hu, S. Tsvyashchenko, A. Chowdhery, J. Bastings, J. Bulian,
X. Garcia, J. Ni, A. Chen, K. Kenealy, J. H. Clark, S. Lee, D. Garrette, J. Lee-Thorp, C. Raffel,
N. Shazeer, M. Ritter, M. Bosma, A. Passos, J. Maitin-Shepard, N. Fiedel, M. Omernick, B. Saeta,
R. Sepassi, A. Spiridonov, J. Newlan, and A. Gesmundo. Scaling up models and data with
t5x
and seqio, 2022.
R. Sennrich, B. Haddow, and A. Birch. Improving neural machine translation models with monolin-
gual data. In ACL, 2016.
B. Shi, W.-N. Hsu, K. Lakhotia, and A. Mohamed. Learning audio-visual speech representation by
masked multimodal cluster prediction, 2022.
A. Tjandra, S. Sakti, and S. Nakamura. Speech-to-speech translation between untranscribed unknown
languages. In Proc. IEEE ASRU, pages 593–600, 2019.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin.
Attention is all you need. In Advances in Neural Information Processing Systems (NeurIPS), pages
5998–6008, 2017.
W. Wahlster. Verbmobil: Foundations of speech-to-speech translation. Springer, 2000.
C. Wang, A. Wu, and J. M. Pino. Covost 2: A massively multilingual speech-to-text translation
corpus. CoRR, abs/2007.10310, 2020. URL https://arxiv.org/abs/2007.10310.
C. Wang, M. Rivière, A. Lee, A. Wu, C. Talnikar, D. Haziza, M. Williamson, J. Pino, and E. Dupoux.
Voxpopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised
learning and interpretation, 2021.
C. Wang, S. Chen, Y. Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li, et al. Neural
codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111,
2023.
22
P. Wang, A. Yang, R. Men, J. Lin, S. Bai, Z. Li, J. Ma, C. Zhou, J. Zhou, and H. Yang. Ofa: Unifying
architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In
International Conference on Machine Learning, pages 23318–23340. PMLR, 2022.
J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. Chi, Q. Le, and D. Zhou. Chain of thought prompting
elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022a.
K. Wei, L. Zhou, Z. Zhang, L. Chen, S. Liu, L. He, J. Li, and F. Wei. Joint pre-training with speech
and bilingual text for direct speech to speech translation. arXiv:2210.17027, 2022b.
J. Yu, Z. Wang, V. Vasudevan, L. Yeung, M. Seyedhosseini, and Y. Wu. Coca: Contrastive captioners
are image-text foundation models. arXiv preprint arXiv:2205.01917, 2022a.
J. Yu, Y. Xu, J. Y. Koh, T. Luong, G. Baid, Z. Wang, V. Vasudevan, A. Ku, Y. Yang, B. K. Ayan,
B. Hutchinson, W. Han, Z. Parekh, X. Li, H. Zhang, J. Baldridge, and Y. Wu. Scaling autoregressive
models for content-rich text-to-image generation. arXiv:2206.10789, 2022b. doi: 10.48550/arXiv.
2206.10789.
L. Yuan, D. Chen, Y.-L. Chen, N. Codella, X. Dai, J. Gao, H. Hu, X. Huang, B. Li, C. Li, et al.
Florence: A new foundation model for computer vision. arXiv preprint arXiv:2111.11432, 2021.
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi. SoundStream: An end-to-end
neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:
495–507, 2021.
C. Zhang, X. Tan, Y. Ren, T. Qin, K. Zhang, and T.-Y. Liu. UWSpeech: Speech to speech translation
for unwritten languages. In AAAI, 2021.
Y. Zhang, W. Han, J. Qin, Y. Wang, A. Bapna, Z. Chen, N. Chen, B. Li, V. Axelrod, G. Wang,
et al. Google USM: Scaling automatic speech recognition beyond 100 languages. arXiv preprint
arXiv:2303.01037, 2023a.
Z. Zhang, L. Zhou, C. Wang, S. Chen, Y. Wu, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li, et al. Speak
foreign languages with your own voice: Cross-lingual neural codec language modeling. arXiv
preprint arXiv:2303.03926, 2023b.
23
A Author Contributions
Paul initiated the project, created the AudioPaLM model architecture and proved its viability with
a number of pre-training, speech recognition and translation tasks, onboarded the team to the
project, and contributed significantly to the write-up of this report. Chulayuth performed many audio
tokenization experiments and completed the audio integration with PaLM2. Duc carried out the
experiments around combined tasks (performing both ASR and AST in the same task), synthesized
the WMT-derived speech-to-speech datasets and further developed the audio vocabulary. All of the
above contributed to the best-performing configuration for speech-to-speech translation. Paul and
Christian coordinated the write-up of this report. Duc and Chulayuth ran a majority of the ablation
experiments.
Ankur, Johan, Tara and Yu collaborated on the research and development of USM-v2 tokens which led
to our best-performing configuration across tasks. Jiahui and Zhishuai developed the token learning
approach for images and Jiahui advised on the development of USM-v2 tokens. James, Wei and
Yongqiang developed the large-scale tokenization and transcription infrastructure for USM models.
Yongqiang, Wei and Félix curated the semi-supervised ASR datasets. Alexandru put in place data
processing pipelines, improved our best mixture by adding a variety of ASR datasets, on AudioLM
speech generation models, and initially worked on the USM-v2 audio tokens together with Johan.
Danny worked on speech-to-speech translation and the ASR-BLEU metric for S2ST models together
with Alexandru and Duc. Peter and Vicky worked on the PaLM2 integration and cascaded model
baselines. Dalia significantly improved the best configuration of this report by adding TTS tasks and
text-to-text and synthetic speech-to-speech datasets to the model’s task mixtures.
Eugene, Damien, Mihajlo, and Neil worked on AudioLM speech quality and in particular on making
the translated voice consistent with the source voice and providing objective metrics. Mihajlo
coordinated this effort, trained speech generation models, and created the website together with
Hannah. Hannah further tuned the best models for the paper, analysed the zero-shot capabilities of
the models, managed the rating tasks for subjective speech quality metrics, and performed a detailed
training data analysis.
Neil contributed significantly to the writing of this report. Marco identified the opportunity to leverage
AudioLM for speech-to-speech translation and Zalán trained the very first such model. Zalán, Neil,
and Marco provided guidance around AudioLM details and project planning. Michelle provided
guidance on speech-to-speech baselines, Translatotron, and other related work. Lukas, Dirk, Matt
and Johan supported and advised the team throughout the project. Christian initiated the project,
coordinated the effort, and contributed with core ideas and technical work.
24

B Detailed results of AST models performance
Table 14: BLEU scores on CoVoST2.
Model
Arabic (ar)
Catalan (ca)
Welsh (cy)
German (de)
Spanish (es)
Estonian (et)
Persian (fa)
French (fr)
Indonesian (id)
Italian (it)
Japanese (ja)
Latvian (lv)
Mongolian (mn)
Dutch (nl)
Portuguese (pt)
Russian (ru)
Slovenian (sl)
Swedish (sv)
Tamil (ta)
Turkish (tr)
Chinese (zh)
All
Whisper 1.5B [Radford et al., 2022] 39.7 31.8 21.5 36.3 40.1 15.0 19.3 36.4 48.1 30.9 26.1 13.9 0.1 41.2 51.6 43.3 21.6 42.9 4.2 28.3 18.0 29.1
mSLAM-CTC 2B [Bapna et al., 2022] 19.3 35.4 6.7 35.9 41.0 22.6 9.7 39.0 8.8 37.3 3.3 26.8 0.8 37.6 42.8 48.4 32.3 38.5 0.6 24.2 10.0 25.2
AudioPaLM 8B AST 45.1 37.9 15.5 42.4 44.9 23.7 25.5 44.1 52.0 43.6 21.4 28.1 4.3 45.5 56.5 52.8 39.3 53.0 4.2 38.9 23.7 35.4
AudioPaLM 8B S2ST 45.5 36.4 19.4 41.4 43.4 27.2 28.4 43.2 54.3 42.9 24.4 33.3 5.8 43.4 55.5 54.3 41.8 53.8 6.9 37.5 21.4 36.2
AudioPaLM-2 8B AST 48.7 38.4 13.7 43.4 44.2 30.0 29.4 44.8 56.2 44.3 25.9 35.0 7.6 48.3 57.3 55.6 42.6 53.3 9.0 41.0 25.5 37.8
Table 15: WER (%) on Vox Populi.
Model
Czech (cs)
German (de)
English (en)
Spanish (es)
Estonian (et)
Finnish (fi)
French (fr)
Croatian (hr)
Hungarian (hu)
Italian (it)
Lithuanian (lt)
Dutch (nl)
Polish (pl)
Romanian (ro)
Slovak (sk)
Slovenian (sl)
All
Whisper 1.5B [Radford et al., 2022] 12.6 11.2 7.0 18.6 28.7 12.4 11.4 16.1 13.8 19.0 33.2 12.9 7.8 14.4 15.4 27.9 13.6
mSLAM-CTC 2B [Bapna et al., 2022] 6.8 8.7 7.0 8.4 - 8.7 9.4 9.1 8.4 15.4 - 10.5 6.4 7.8 6.0 15.1 9.1
MAESTRO 600M [Chen et al., 2022c] 6.9 7.9 6.3 7.2 - 8.6 7.9 8.5 7.1 13.3 - 9.2 5.7 7.3 5.2 14.2 8.1
AudioPaLM 8B AST 10.1 8.9 6.1 6.4 - 12.0 8.3 11.4 12.4 15.0 - 10.1 8.3 13.2 10.0 23.6 11.1
AudioPaLM 8B S2ST 13.6 10.6 6.5 7.6 - 17.6 10.0 17.4 9.8 17.0 - 11.1 7.6 22.7 8.6 64.3 16.0
AudioPaLM-2 8B AST 8.4 9.4 6.2 6.4 - 12.3 8.3 10.7 9.5 14.8 - 10.5 7.0 9.6 5.9 17.8 9.8
C Detailed results of S2ST models performance
Table 16: S2ST performance on CVSS, ASR-BLEU scores.
Model
Arabic (ar)
Catalan (ca)
Welsh (cy)
German (de)
Spanish (es)
Estonian (et)
Persian (fa)
French (fr)
Indonesian (id)
Italian (it)
Japanese (ja)
Latvian (lv)
Mongolian (mn)
Dutch (nl)
Portuguese (pt)
Russian (ru)
Slovenian (sl)
Swedish (sv)
Tamil (ta)
Turkish (tr)
Chinese (zh)
All
Translatotron 2 [Jia et al., 2022a] 30.2 31.9 5.4 33.6 38.5 21.0 11.6 36.5 32.8 35.7 8.5 22.7 2.5 34.1 41.1 45.6 25.8 36.6 2.2 28.7 13.1 25.6
AudioPaLM 8B S2ST 41.5 33.7 18.4 37.2 40.4 23.6 24.6 38.3 47.9 39.4 20.9 25.3 4.8 40.4 50.6 51.3 38.5 43.6 7.2 35.1 20.0 32.5
25

D Detailed results of AST zero-shot performance
Table 17: Zero-shot AST performance on FLEURS. BLEU scores for each language together with
the number of hours of audio the model has been trained on in each language. The hours of training
data for AudioPaLM do not include audio data seen in self-supervised training of audio tokenization
models. The languages indicated with § and † belong respectively to the “AST observed” and “ASR
observed” sets used in Section 5.2.
Model
Afrikaans
†
(af)
Amharic (am)
Arabic
§
(ar)
Assamese (as)
Asturian (ast)
Azerbaijani
†
(az)
Belarusian
†
(be)
Bulgarian
†
(bg)
Bengali
†
(bn)
Bosnian (bs)
Catalan
§
(ca)
Cebuano (ceb)
Kurdish (ckb)
Chinese
§
(cmn)
Czech
§
(cs)
Welsh
§
(cy)
Danish
†
(da)
German
§
(de)
Greek
†
(el)
English (en)
Spanish
§
(es)
Whisper 1.5B 34.1 1.9 25.5 5.4 - 13.7 11.7 28.5 13.2 29.7 34.2 - - 18.4 27.8 13.0 32.7 34.6 23.7 80.2 23.3
AST training data (hours) 330 32 2286 136 0 86 133 202 1988 219 236 0 0 11731 401 8263 386 4309 968 0 6693
ASR training data (hours) 4.1 0 739 0 0 47 2.4 86 1.3 11 1883 0 0 23446 192 73 473 13344 529 438218 11100
AudioPaLM-2 8B 34.7 3.8 29.0 9.3 30.8 16.2 15.1 35.5 15.9 35.7 42.5 10.3 4.0 21.3 34.5 7.2 37.9 38.7 18.8 77.2 26.9
AST training data (hours) 0 0 2 0 0 0 0 0 0 0 135 0 0 10 97 2 0 838 0 0 1887
ASR training data (hours) 96 0 146 0.4 0 99 135 168 121 0 515 0 2 120 237 5 115 848 151 1465 2047
Model
Estonian
§
(et)
Persian
§
(fa)
Fula (ff)
Finnish
§
(fi)
Filipino (fil)
French
§
(fr)
Irish (ga)
Galician
†
(gl)
Gujarati
†
(gu)
Hausa (ha)
Hebrew (he)
Hindi
†
(hi)
Croatian
§
(hr)
Hungarian
§
(hu)
Armenian
†
(hy)
Indonesian
§
(id)
Igbo (ig)
Icelandic
†
(is)
Italian
§
(it)
Japanese
§
(ja)
Javanese (jv)
Whisper 1.5B 18.7 19.6 - 22.1 24.4 32.2 - 27.9 16.2 0.4 21.8 22.0 27.0 21.2 16.0 29.1 - 9.1 23.6 18.9 6.2
AST training data (hours) 79 392 0 750 894 4481 0 368 208 8 418 5438 239 554 116 1174 0 84 2145 8860 622
ASR training data (hours) 41 24 0 1066 75 9752 0 9 0.3 0 688 12 91 379 13 1014 0 16 2585 7054 0
AudioPaLM-2 8B 31.7 25.7 0.29 29.3 15.6 36.5 0.3 34.7 12.2 0.6 0.4 21.7 30.6 29.2 10.2 34.2 0.3 17.8 27.8 11.1 9.7
AST training data (hours) 3 49 0 39 0 800 0 0 0 0 0 0 75 78 0 1 0 0 255 1 0
ASR training data (hours) 163 165 0 175 0 857 0.2 1 123 0.7 0 101 34 239 126 121 0 91 338 181 0
Model
Georgian
†
(ka)
Kamba (kam)
Kabuverdianu (kea)
Kazakh (kk)
Khmer (km)
Kannada (kn)
Korean
†
(ko)
Kyrgyz (ky)
Luxembourgish (lb)
Ganda (lg)
Lingala (ln)
Lao (lo)
Lithuanian
§
(lt)
Luo (luo)
Latvian
§
(lv)
Maori (mi)
Macedonian
†
(mk)
Malayalam
†
(ml)
Mongolian
§
(mn)
Marathi
†
(mr)
Whisper 1.5B (BLEU) 2.4 - - 5.4 6.1 11.6 21.3 - 16.8 - 1.0 11.0 14.0 - 14.3 10.2 27.7 16.7 1.0 12.9
AST training data (hours) 40 0 0 31 672 90 19938 0 10 0 20 20 99 0 68 1381 30 892 79 288
ASR training data (hours) 0.6 0 0 12 1 4 7993 0 0 0 0 0.1 67 0 65 0 16 0.5 0 0.6
AudioPaLM-2 8B (BLEU) 13.6 1.6 29.4 9.5 0.1 4.8 19.4 8.61 16.1 1.6 0.7 9.5 26.8 0.6 30.5 1.2 30.8 12.2 10.1 17.1
AST training data (hours) 0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 0 0 0 3 0
ASR training data (hours) 137 0 0 0.2 0 0 157 0.7 0 26 0 0 172 0 150 0 104 110 4 90
26

Table 17: (continued) Zero-shot AST performance on FLEURS. BLEU scores for each language
together with the number of hours of audio the model has been trained on in each language. The
hours of training data for AudioPaLM do not include audio data seen in self-supervised training of
audio tokenization models. The languages indicated with § and † belong respectively to the “AST
observed” and “ASR observed” sets used in Section 5.2. In the last column “All (82 languages)”,
the average BLEU score and total number of AST/ASR training hours were computed over the 82
languages (out of 102) that were used to evaluate the Whisper model.
Model
Malay
†
(ms)
Maltese (mt)
Myanmar (my)
Norwegian (nb)
Nepali
†
(ne)
Dutch
§
(nl)
Northern-Sotho (nso)
Nyanja (ny)
Occitan (oc)
Oromo (om)
Oriya (or)
Punjabi (pa)
Polish
§
(pl)
Pashto (ps)
Portuguese
§
(pt)
Romanian
§
(ro)
Russian
§
(ru)
Sindhi (sd)
Slovak
§
(sk)
Slovenian
§
(sl)
Whisper 1.5B 27.3 13.5 0.4 31.4 16.1 24.0 - - 20.2 - - 15.7 22.3 3.4 38.1 31.5 27.8 5.7 26.1 17.0
AST training data (hours) 1691 41 59 322 133 1767 0 0 49 0 0 117 2200 63 3620 555 7687 46 144 395
ASR training data (hours) 382 1 0.1 266 0.6 2077 0 0 0 0 0 0.8 4278 0 8573 356 9761 0 90 41
AudioPaLM-2 8B 31.9 12.4 0.0 34.6 16.2 29.1 1.1 1.4 22.9 0.3 8.9 6.0 25.3 0.4 38.4 35.7 31.2 1.4 32.3 27.4
AST training data (hours) 0 0 0 0 0 96 0 0 0 0 0 0 174 0 10 156 18 0 52 17
ASR training data (hours) 126 0.7 0 0 170 195 0 0 0 0 0.2 0.3 267 0 16 246 179 0 191 170
Model
Shona (sn)
Somali (so)
Serbian
†
(sr)
Swedish
§
(sv)
Swahili
†
(sw)
Tamil
§
(ta)
Telugu
†
(te)
Tajik (tg)
Thai
†
(th)
Turkish
§
(tr)
Ukrainian
†
(uk)
Umbundu (umb)
Urdu
†
(ur)
Uzbek (uz)
Vietnamese
†
(vi)
Wolof (wo)
Xhosa (xh)
Yoruba (yo)
Cantonese (yue)
Zulu (zu)
All (82 languages)
Whisper 1.5B 1.8 0.7 32.5 35.3 7.2 9.2 12.5 14.5 16.1 26.6 29.4 - 17.2 6.0 20.4 - - 1.4 - - 17.9
AST training data (hours) 279 21 136 1055 282 1484 987 15 1635 2241 509 0 1990 4 1719 0 0 432 0 0 120.6k
ASR training data (hours) 0 0 28 2119 5 136 4 0.3 226 4333 697 0 104 0.3 691 0 0 0 0 0 117.1k
AudioPaLM-2 8B 0.4 0.9 34.3 40.4 9.1 15.0 13.3 17.1 15.0 30.1 26.9 0.9 13.3 17.2 15.6 0.3 0.2 0.7 7.4 1.9 20.4
AST training data (hours) 0 0 0 2 0 2 0 0 0 4 0 0 0 0 0 0 0 0 0 0 4.8k
ASR training data (hours) 0 0 122 129 126 125 109 0 156 145 138 0 116 0 149 0 0 0 1 0 12.8k
27
